
この記事ではLLMに特化して解説します。LLM全般の仕組みは LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】 をご覧ください。
OpenRouterが2026年6月13日、Fusion API を発表した。複数のLLMを1つのプロンプトに並列実行し、judge(判定)モデルで合議させる「複合モデル(compound model)」だ。まず、この発表を告げた公式アカウントの投稿と、Fusionが「何をするものか」を1枚にした図から見てほしい。

この投稿——「市場で最も賢い複合モデル『Fusion API』を発表します。FusionはFable級の知性を半額で実現します」——は、OpenRouterが2026年6月13日に自社アカウント(@OpenRouter)から発したものだ。ここで押さえるべき要点を先にまとめる。
・何の発表か:複数のLLMを1プロンプトに並列実行し、judge(判定)モデルで合議させる「複合モデル(compound model)」。openrouter/fusion という単一の名前で呼べる
・なぜ効くか:各モデルが個別に答えると見落としや誤りが混ざる。judgeが複数回答を突き合わせ、矛盾を検出し合意点を残すことで単体モデルを上回る
・ベンチ結果:100タスクの深層リサーチ評価「DRACO」で、Fable 5+GPT-5.5の融合が 69.0% と単体Fable 5の 65.3% を上回った
・コストの二面性:安価モデル3つの予算パネルはFable 5に約1%差まで迫り、コストは 半額。一方で高精度プリセットは単一補完の 4〜5倍
・意味:「最強の単体モデルを選ぶ」競争から「複数を賢く合議させる」設計への転換点
OpenRouterは、OpenAI・Anthropic・Google・Mistral・Meta など主要プロバイダの数百モデルを単一のOpenAI互換APIで束ねるLLMゲートウェイだ。これまでは「どのモデルにルーティングするか」を最適化する存在だったが、Fusionで初めて「複数モデルを同時に走らせて統合する」レイヤーへ踏み込んだ。読者が抱く3つの問い——Fusionは結局何ができるのか/何を解決するのか/何を代替できるのか——に、以下の各セクションで順に答えていく。
本記事は何の発表か — Fusion APIの位置づけ
まず、今回の発表が「新モデルのリリース」ではない点を明確にしておく。Fusionができることは、既存モデルを賢く組み合わせて1つの回答を作ることであって、新しい基盤モデルを世に出すことではない。Fusionは新モデルではなく、既存モデル群をオーケストレーションする上位レイヤーだ。
公式アカウントの告知(記事冒頭に埋め込んだ投稿)は「市場で最も賢い複合モデル『Fusion API』を発表します。FusionはFable級の知性を半額で実現します」というものだった。この告知の背景には、発表に合わせて公開された技術ブログ「Surpassing Frontier Performance with Fusion(Fusionでフロンティア性能を超える)」がある。そこで示されたのは、安価なモデルを束ねた合議体が、フロンティアの単体モデルを上回りうるという実測結果だった(具体的な数値は後述のDRACOベンチのセクションで検証する)。
「compound model(複合モデル)」という言い方がポイントだ。単体のLLMではなく、複数モデル+判定ロジックを1つのAPIとしてパッケージし、利用者からは1モデルのように見える。後述するように、これは学術的に Mixture-of-Agents(MoA) や LLM-as-a-judge と呼ばれてきた手法を、設定不要のプロダクトに落とし込んだものだ。
なお、Fusionは Qwen 3.6 PlusがOpenRouterで1日1.4兆トークンを処理した過去最大級の事例 のような「単体モデルの巨大トラフィック」とは方向性が逆で、1リクエストあたりの計算量を増やして質を上げる発想に立っている。
Fusionの仕組み — panelとjudgeの2段構成
Fusionの動作は、panel(パネル=回答者の合議体) と judge(判定者) の2段に分かれる。流れを図にする。
web search/fetch有効"] F --> M2["パネル: モデルB
web search/fetch有効"] F --> M3["パネル: モデルC
web search/fetch有効"] M1 --> J["judge モデル
回答を比較・統合"] M2 --> J M3 --> J J --> A["構造化分析
合意/矛盾/穴/洞察/盲点"] A --> O["最終回答を合成"]
各段階を分解する。
・並列回答:プロンプトがパネルの各モデルに同時dispatchされる。各モデルは web search と web fetch が有効で、一次ソースを跨いで調べながら答える
・判定:judgeモデルが全回答を受け取り、比較分析する。出力は5つの観点に構造化される — consensus(合意)/ contradictions(矛盾)/ coverage gaps(カバレッジの穴)/ unique insights(独自の洞察)/ blind spots(盲点)
・合成:judgeの構造化分析をもとに、あなたが指定したモデル(既定では外側のモデル)が最終回答を組み立てる
ここで効いているのは「judgeが矛盾を可視化する」点だ。単体モデルは自信満々に間違える(ハルシネーション)が、3つのモデルのうち1つだけが言っている主張は judge が「contradiction」「unique insight(要検証)」として隔離できる。逆に全モデルが一致した部分は高信頼として残る。多数決ではなく、合意と相違を構造化して人間/後段に渡すのがFusionの本質だ。
この設計には、公式ドキュメントに書かれた細かな作り込みがいくつかある。読者の「Fusionは結局何ができるのか」に技術的に答えるうえで押さえておきたい。
・judgeは常にtemperature 0で走る:パネル側の各モデルはtemperatureで多様性を持たせられるが、judge(判定者)はドキュメント上、常に温度0で動く。判定は「ばらつかせる」より「一貫して厳密に突き合わせる」方が望ましいという設計思想の表れだ
・パネルは最大8モデルまで:analysis_modelsで1〜8個を指定できる。既定は品質プリセット(Opus / GPT-latest / Gemini Pro)。多いほど多様な視点が集まるが、料金とレイテンシは素直に増える
・パネルにはツールが渡る:各パネルモデルはweb searchとweb fetchを使いながら答える。judgeが受け取るのは「素の生成」ではなく「一次ソースを当たった上での回答」なので、引用付きの深層リサーチで威力が出る
・再帰はヘッダーで封じる:judgeやパネルの内側からFusionツールがまたFusionを呼ぶ無限ループを防ぐため、x-openrouter-fusion-depthヘッダーで深度を制限し、合議は1階層のみに固定している
つまりFusionは「複数モデルにただ投げて多数決を取る」単純な仕組みではない。パネルは多様に探索し(web検索つき)、judgeは温度0で厳密に突き合わせ、再帰は封じる——探索と収束を役割分担させた設計になっている。この役割分担が、次のセクションで見るベンチマーク上の伸びを生んでいる。
ベンチマーク — 安価パネルがFable 5に1%差まで迫る
OpenRouterは DRACO という深層リサーチ評価ベンチで100タスクを測定した。公式ブログによれば、DRACOは回答を4つのカテゴリで採点する——Factual Accuracy(事実正確性、約20項目)/ Breadth & Depth(広さと深さ、約9項目)/ Presentation Quality(提示品質、約6項目)/ Citation Quality(引用品質、約5項目)。項目数が最も多い事実正確性の重みが大きく、要するに「根拠を持って、広く深く、読みやすく、引用付きで答えられるか」を測るベンチだと理解すればよい。この設計自体が、単発生成より合議に有利に働く。事実誤認や引用漏れは、複数モデルを突き合わせると発見されやすいからだ。結果を表にまとめる。
| 構成 | DRACOスコア | 種別 | 備考 |
|---|---|---|---|
| Fable 5 + GPT-5.5 | 69.0% | 融合(2モデル) | 全構成中の最高。単体を全て上回る |
| Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68.3% | 融合(3モデル) | フロンティア3枚の合議 |
| Opus 4.8 + Opus 4.8(自己融合) | 65.5% | 融合(同一2枚) | 単体58.8%から+6.7pt |
| Fable 5(単体) | 65.3% | 単体 | 最強の単体モデル |
| Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro | 64.7% | 融合(予算パネル) | Fable 5に約1%差、コストは50% |
| GPT-5.5(単体) | 60.0% | 単体 | — |
| Opus 4.8(単体) | 58.8% | 単体 | — |
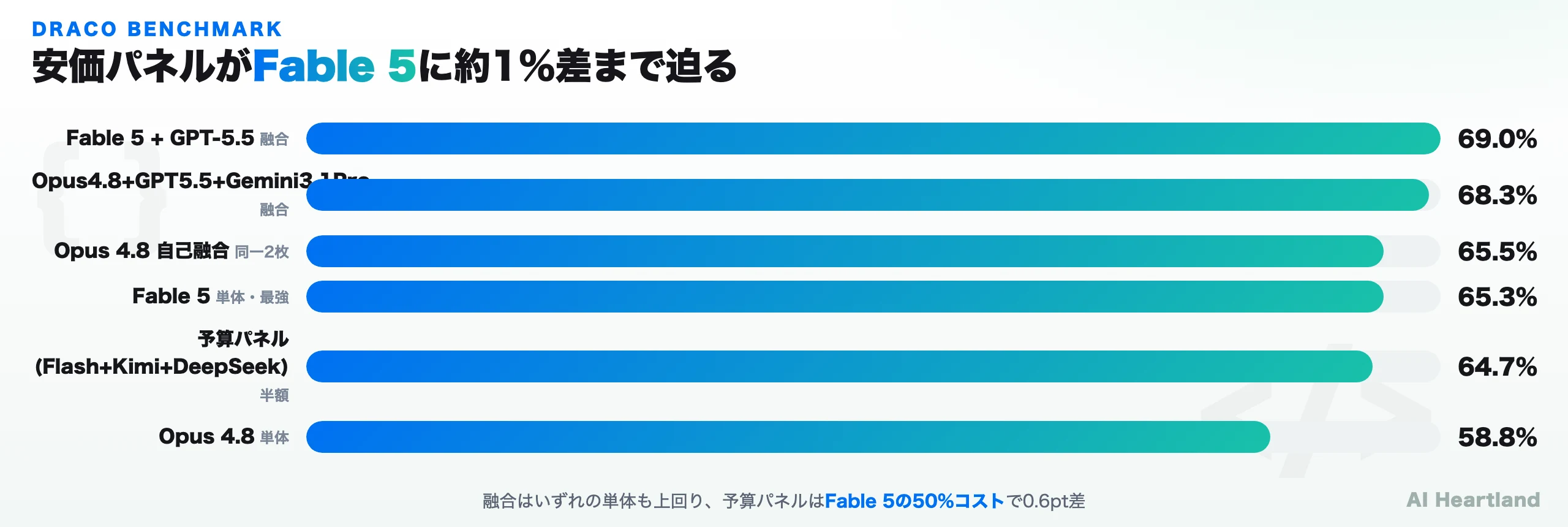
この表とグラフから読み取るべき発見は3つある。
・融合は単体を超える:Fable 5+GPT-5.5の69.0%は、いずれの単体(Fable 5の65.3%、GPT-5.5の60.0%)も上回った。1+1が2より大きくなった
・安く同等が出せる:予算パネル(Flash+Kimi+DeepSeek)の64.7%は、Fable 5単体の65.3%にわずか0.6pt差。しかもコストはFable 5の半分。これが公式ツイートの「Fable級を半額」の正体
・多様性だけが理由ではない:Opus 4.8を自分自身と融合させた自己融合でも58.8%→65.5%へ跳ねた。異なるモデルを混ぜる効果に加え、統合(synthesis)という工程そのものが精度を底上げしている
3つ目の「自己融合」の結果は特に示唆的だ。複数の異なるモデルを集める「アンサンブルの多様性」だけでなく、いったん複数回答を出して judge で突き合わせる手続き自体が、単発生成より良い答えを生む。Chain-of-Thoughtやself-consistencyの延長線上にある発見と言える。
ただし注意点も明記しておく。DRACOは深層リサーチに特化したベンチで、短文応答・コード生成・対話などでは融合の優位がそのまま再現するとは限らない。引用品質や事実正確性が重視されるタスクで効果が大きい、という文脈で読むのが正しい。
開発者向け — Fusionの呼び方とパラメータ
Fusionができることを最短で試す方法は、model を openrouter/fusion にするだけだ。OpenAI互換なので、既存のOpenAI/OpenRouterクライアントのモデル名を差し替えるだけで動く。手順として最小限の呼び出しを1つだけ示す。
curl https://openrouter.ai/api/v1/chat/completions \
-H "Authorization: Bearer $OPENROUTER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openrouter/fusion",
"messages": [
{"role": "user", "content": "炭素税への賛成・反対の最も強い論拠を調査して整理して"}
]
}'
これだけで、既定の品質プリセット(Opus / GPT / Gemini Proのパネル)が並列に走り、judgeが合議した回答が返る。ここから先はコードを並べるより、どのパラメータで挙動が変わるかを押さえる方が実務では重要だ。パネル構成やjudgeを明示制御したい場合は、通常のモデル呼び出しに tools として openrouter:fusion を渡し、analysis_models(パネル1〜8個)や max_tool_calls を指定する。主なパラメータを表で整理する。
| パラメータ | 既定値 | 意味 |
|---|---|---|
analysis_models | 品質プリセット(Opus / GPT-latest / Gemini Pro) | 並列実行するパネルのモデル。1〜8個。各モデルはweb search/fetch有効 |
model(judge) | 外側のモデル | 構造化分析を生成する判定モデル |
max_tool_calls | 8 | テキスト出力前のツール呼び出し回数。1〜16 |
max_completion_tokens | プロバイダ既定 | パネル/judge1回あたりの出力上限 |
temperature | プロバイダ既定 | パネルのサンプリング温度(0〜2)。judgeは常に0で走る(公式ドキュメント) |
tool_choice | — | required で毎リクエストFusionを強制 |
再帰についても設計済みだ。judgeやパネルの内側からFusionが再度発火しないよう、x-openrouter-fusion-depth ヘッダーで深度を制限し、合議は1階層のみに抑えている。APIを使わずに試すなら、チャットUI(openrouter.ai/fusion)でプリセットを選ぶか独自パネルを組んで動かせる。
料金 — 「半額」と「4〜5倍」の二面性を正しく読む
Fusionの料金は、どのパネルを選ぶかで印象が真逆になる。ここを誤解すると見積もりを外す。
仕組み上、Fusionは「パネルN回+judge1回」の補完を消費する。公式ドキュメントは、デフォルトの3モデルパネルで 単一補完のおよそ4〜5倍、パネル数に対してほぼ線形にスケールすると説明している。つまり高精度プリセット(Opus / GPT / Gemini Pro)は素直に割高だ。
一方で公式ツイートの「Fable級を半額」は、安価モデルの予算パネルを指している。Gemini 3 Flash・Kimi K2.6・DeepSeek V4 Proという廉価モデル3枚を束ねると、合計コストがFable 5単体の約半分に収まりながら、精度はFable 5に1%差まで迫る。同じopenrouter/fusionでも、選ぶパネルで料金の性格が正反対になる点を図で整理しておく。

深層リサーチ/批評"| H["高精度プリセット
単一補完の4〜5倍"] Q -->|"Fable級を安く
出したい"| B["予算パネル
Fable 5の約50%コスト"] Q -->|"短文/定型/低コスト"| S["単体モデルでよい
Fusionは割に合わない"]
見積もりの感覚をつかむために、料金構造を分解しておく。Fusionが消費するのは「パネルN回+judge1回」の補完だ。3モデルパネルなら、パネルで3回・judgeで1回、合わせて4回分の補完が走り、これが公式ドキュメントの言う「単一補完の4〜5倍」の内訳になる(judgeが外側モデルの生成も兼ねるため、体感で4〜5倍に収まる)。パネルを5モデルに増やせば5+1で6回分、8モデルなら8+1で9回分と、パネル数に対してほぼ線形に積み上がる。さらに各パネルモデルはweb search/fetchを使うため、max_tool_calls(既定8、最大16)を高く設定するとツール呼び出しの分だけ内側の補完回数も増える。つまり料金は「パネル数 × 1回あたりのモデル単価 × ツール呼び出し回数」の掛け算で膨らむ。コストを読み違えないコツは、パネル数を必要最小に絞り、安価モデルで組み、max_tool_callsを用途に見合う値まで下げる——この3点を最初に決めることだ。
判断基準はシンプルだ。間違いのコストが、追加の補完コストを上回るか。深層リサーチ、専門批評、法務・医療・金融のような高stakeな調査では、数回分の補完料を払ってでも合議で精度を取りに行く価値がある。逆に、短い定型応答やチャットの相づちにFusionを使うのは過剰だ。
競合との比較 — ルーターとオーケストレーターは別物
「複数モデルを扱うレイヤー」は他にもあるが、Fusionの1リクエスト内で合議する性質は質的に異なる。代表的な選択肢と並べる。
| ツール | 形態 | 1リクエストの挙動 | Fusionとの違い |
|---|---|---|---|
| OpenRouter Fusion | 複合モデル(マネージド) | 複数モデルを並列→judgeで合議→合成 | —(本記事の主役) |
| OpenRouter 通常ルーティング | ゲートウェイ | 1モデルに送る(フォールバックあり) | 合議はしない。最適な1モデルを選ぶだけ |
| LiteLLM | OSSプロキシ | 1モデルに送る(ルーティング/リトライ) | セルフホスト可。合議ロジックは自前実装が必要 |
| Vercel AI SDK | TSツールキット | 1モデルを抽象化して呼ぶ | UI/ストリーミング向け。合議は範囲外 |
| Martian / Not Diamond 等 | モデルルーター | プロンプトに最適な1モデルを選ぶ | 「選ぶ」が目的。複数同時実行はしない |
整理すると、世の中の多くは「1リクエスト=1モデル」のゲートウェイ/ルーターで、賢く振り分けはしても同時に走らせて統合はしない。Fusionはここで一線を画す。
学術的には、複数LLMの回答を別のLLMで統合する Mixture-of-Agents(MoA)、回答を採点・選別させる LLM-as-a-judge が以前から提案されてきた。Fusionの新規性は手法そのものではなく、それを 設定不要・1つのモデル名で呼べるマネージドAPI に落とし込み、web search統合とコスト最適化(予算パネル)まで含めて製品化した点にある。自前でMoAパイプラインを組む手間と、パネル設計・judge設計・再帰制御の難所を、APIの裏側に隠した。
ではFusionは何を代替できるのか。ここを具体的に整理すると導入判断がはっきりする。第一に、自前で組んでいたMoA/アンサンブルの実装を代替する。これまで「複数モデルに投げて、結果を別のLLMでまとめる」パイプラインは、キューイング・並列実行・タイムアウト処理・judgeプロンプトの設計・再帰暴走の防止まで全部を手作業で組む必要があった。Fusionはこれをopenrouter/fusionの1行に畳み込む。第二に、一部の深層リサーチ用途で、単体のフロンティアモデル(Fable 5やOpus 4.8など)を代替できる。DRACOで見たとおり、予算パネルなら半額でFable級に迫れるため、コスト制約の強いリサーチ機能では上位モデルの直接指定を置き換える候補になる。
一方で、代替できないものも明確だ。低レイテンシのチャット応答、コード補完、単純な分類・抽出といった「1発で速く安く返したい」タスクは、依然として単体モデルの領分だ。Fusionはこれらを置き換えるものではなく、むしろ使うと過剰になる。代替の線引きは「間違いのコストが、追加の補完コストとレイテンシを上回るか」——この一点に尽きる。
OpenRouter全体での位置づけ — ゲートウェイから合議レイヤーへ
Fusionを正しく理解するには、OpenRouterというプロダクトの進化線に置いてみるとよい。OpenRouterはもともと、数百のモデルを単一のOpenAI互換エンドポイント(/api/v1/chat/completions)で束ねるゲートウェイとして始まった。利用者はAPIキー1本とクレジット課金で、AnthropicのClaudeもGoogleのGeminiもMetaのLlamaも同じインターフェースから呼べる。プロバイダ障害時の自動フォールバック、最安プロバイダへのルーティング、利用量に応じた従量課金——これらが従来の価値だった。
つまりOpenRouterは長らく「配送(routing)の最適化」を担うレイヤーだった。どのモデルに、どのプロバイダ経由で、いくらで送るか。そこに賢さはあっても、生成そのものは常に単体モデルの仕事だった。
Fusionはこの境界を初めて越える。ルーティングの先で複数モデルを同時に動かし、judgeで束ね、1つの回答に統合する。OpenRouterのスタックを階層で描くとこうなる。

重要なのは、Fusionが既存のルーティング層の上に乗っていることだ。パネルの各モデルは引き続きOpenRouterの通常ルーティングで最安・最速のプロバイダへ配送される。その上にFusionが「合議」という新しい抽象を追加した格好だ。だからこそ、利用者はopenrouter/fusionという1つの名前を呼ぶだけで、裏側の数モデル×複数プロバイダの並列実行を意識せずに済む。
この位置づけは、OpenRouterが「モデルの卸売り」から「モデルを組み合わせて売る付加価値レイヤー」へ事業の軸足を広げ始めた兆候とも読める。単体モデルの価格競争が激化するなかで、ゲートウェイ事業者が差別化を図る自然な方向だ。Fable級を半額で出すという訴求は、まさに「合議によって安価モデルの価値を引き上げる」というOpenRouterの新しいポジショニングを象徴している。
実務での使いどころ — judgeの構造化分析を活かす
Fusionの真価は、最終回答テキストだけでなく judgeが返す構造化分析(合意/矛盾/穴/洞察/盲点)を後段で使うところにある。何を解決するのかを用途の粒度で言えば、Fusionは「答えを1つに丸める」道具ではなく「相違を可視化して品質を設計可能にする」道具だ。逆に、どんなタスクに向き・不向きかを図で押さえておくと導入判断を誤らない。

そのうえで、運用上のコツを挙げる。
・矛盾を握りつぶさない:judgeが検出したcontradictions(矛盾)は、そのまま人間レビューやファクトチェック工程に回す。Fusionは「正解を1つに丸める」ためでなく「相違を可視化する」ために使うと価値が出る
・パネルは目的で組む:事実重視なら検索強いモデル、批評重視なら推論強いモデルを混ぜる。同質なモデルばかりだと多様性の利得が減る
・バッチで使う:レイテンシが積むため、対話UIの即応より、夜間バッチのリサーチ・レポート生成・大量ドキュメント要約に向く
・コスト上限を切る:max_tool_calls や max_completion_tokens を絞り、パネル数も必要最小に。料金がパネル数に線形で効くことを忘れない
具体的な組み込み方を、よくある3つのシナリオで考えてみる。ひとつめは社内向けリサーチアシスタント。競合調査や技術選定のような「間違えると意思決定を誤る」問いに対し、事実重視のパネル(検索が強いモデル中心)を組み、judgeが検出したcontradictions(矛盾)を回答の末尾に「要確認事項」として自動で付す。人間は結論だけでなく「どこがモデル間で割れたか」を一目で把握でき、レビューの当たりをつけやすくなる。ふたつめは自動レポート生成のバッチ。夜間に大量のドキュメントやニュースを要約・統合する処理では、レイテンシがユーザー体験に直結しないため、Fusionの遅さが問題になりにくい。予算パネルを使えば、上位モデルを直接叩くより安く、かつ引用品質の高いレポートが得られる。みっつめはRAGの回答検証。検索で引いた文脈をもとにパネルが答え、judgeが「どの主張が全モデル一致か/どれが1モデルだけの主張か」を仕分ける。一致部分を高信頼、単独主張を要検証としてUIに出せば、ハルシネーションをユーザーに見せる前に工程で捕まえられる。
いずれのシナリオも共通するのは、judgeの構造化分析を「読み捨てず」に後段のロジックへ流すという点だ。Fusionを「賢い単一回答を返すAPI」としてだけ使うと、料金の割に得られる価値は薄い。合意・矛盾・盲点という判定結果そのものを製品の品質管理に組み込んで初めて、複合モデルにコストを払う意味が立つ。
開発者・利用者への影響 — 「最強の1モデル」競争の終わり方
Fusionが示すのは、モデル選定の発想転換だ。これまでLLM活用の定石は「ベンチマーク最上位の単体モデルを選ぶ」だった。だがDRACOの結果は、安価モデルの合議がフロンティア単体を超えうることを実測で見せた。これは現場に3つの変化をもたらす。
・コスト最適化の自由度が上がる:高い単体モデルに固定せず、安価モデルを束ねて同等精度を狙える。予算制約の強いプロダクトほど恩恵が大きい
・信頼性が「設計」できる:judgeの構造化分析(矛盾・盲点)を後段ロジックやレビューに渡せば、ハルシネーションのリスクを工程で抑えられる。RAGや自動リサーチの品質管理に直結
・ベンダーロックインの低下:単一モデルへの依存が減り、特定プロバイダの値上げ・障害・モデル廃止に強くなる
一方で見落としてはいけない制約もある。Fusionはレイテンシとコストを質と交換する仕組みだ。パネルが並列とはいえ最遅モデルに律速され、judge合成の分だけ遅延も積む。リアルタイム性が要るUXには不向きで、バッチのリサーチ・分析・レポート生成に最適化されている。「速い・安い・賢い」を全部取る魔法ではなく、賢さを買うために速度とコストを差し出すトレードオフだと理解して使うのが正しい。
この転換をもう一段深く捉えると、Fusionが問い直しているのは「モデルの賢さはどこに宿るのか」という前提だ。これまでの2〜3年、LLMの進歩はほぼ「1つのモデルの中身を大きく・賢くする」方向で進んできた。パラメータを増やし、学習データを積み、推論を強化する。ベンチマークのトップは常に単体モデルで、開発者の仕事は「今いちばん強い1つを選ぶ」ことだった。Fusionが示したのは、その前提の外側にもう1本、伸びしろがあるという事実だ。同じモデルでも、答えさせ方(合議・統合)を変えるだけで精度が上がる——自己融合でOpus 4.8が58.8%から65.5%へ跳ねた結果は、その象徴だった。
これは、推論時により多くの計算を投じて質を上げる「test-time compute(推論時計算)」の潮流とも重なる。Chain-of-Thoughtやself-consistency、あるいは推論特化モデルの長考が「1つのモデルの中で考える時間を増やす」方向だったのに対し、Fusionは「複数のモデルに並列で考えさせ、別のモデルで束ねる」方向で同じことをやっている。どちらも「学習を終えたあと、推論の瞬間にコストを積んで賢さを買う」という発想で一致している。Fusionの意義は、この発想を研究の実験ではなく、openrouter/fusionという1つの名前で誰でも呼べる製品にした点にある。
現場のエンジニアにとっての実践的な含意はシンプルだ。「どのモデルが最強か」を追い続けるより、手持ちのタスクごとに「単体で十分か/合議で質を取りに行くか」を切り分ける設計力の方が、これからは効いてくる。高stakesなリサーチにはFusion、即応が要る対話には単体、という使い分けを前提に、アーキテクチャを組めるかどうか。Fusionはその選択肢を、追加のインフラを一切持たずに手に入れられるようにした。
総じて、Fusionは「どのモデルが最強か」という問いを「どのモデルをどう合議させるか」という設計問題に置き換えた。2026年のLLM活用は、単体性能のチャンピオン探しから、複数モデルのオーケストレーション設計へと重心を移しつつある。その流れを、設定不要のAPIとして誰でも触れる形にしたのがFusionの意義だ。
まとめ
OpenRouter Fusion APIは、複数モデルを並列実行しjudgeで合議させる複合モデルだ。DRACOベンチでFable 5+GPT-5.5の融合が69.0%と単体を上回り、安価な予算パネルはFable 5に1%差・半額で迫った。openrouter/fusion を呼ぶだけで使え、料金はパネル次第で「半額」にも「4〜5倍」にもなる。深層リサーチや高stakeな批評には強く、リアルタイム用途には不向き——この見極めが導入の鍵になる。
参照ソース
・OpenRouter公式X(@OpenRouter)「Introducing the Fusion API」 — https://x.com/OpenRouter/status/2065856853989270011
・OpenRouter Blog「Surpassing Frontier Performance with Fusion」 — https://openrouter.ai/blog/announcements/fusion-beats-frontier/
・OpenRouter Docs「Fusion Router」 — https://openrouter.ai/docs/guides/routing/routers/fusion-router
・OpenRouter Docs「Quickstart / Models」 — https://openrouter.ai/docs





