
janhqが公開するIchigoは、「ローカルでリアルタイムに動く音声AI(Local realtime voice AI)」を掲げるオープンソースの音声パッケージだ。音声の文字起こしから、テキストLLMに「耳」を生やす実験的な音声言語モデルまでを、pip install 一発と数行のPythonで扱えるようにまとめている。GitHubのスター数は約2,484(2026年6月時点)。
開発元のjanhqは、ローカルでLLMを動かすデスクトップアプリ「Jan」やローカル推論エンジン群を手がけるチームで、Ichigoはその音声側を担うコンポーネントにあたる。音声処理の煩雑な前処理を肩代わりし、開発者が「モデルを動かして改善する」ことに集中できる状態を目指している。
本記事は、Ichigoの公式リポジトリ(README)、技術論文(arXiv:2410.15316)、開発元の公式チェックポイント解説(menlo.ai)という一次ソースだけを根拠に、Ichigoの正体・しくみ・導入・公称ベンチマーク・類似OSSとの違い・制限を整理する。READMEに記載のない数値や挙動は「公式未記載」として扱い、推測を事実として書かない。

30秒で理解する Ichigo
・何者か:janhq製のローカル音声AIパッケージ。pip install ichigo で導入でき、ASR(文字起こし)・音声LLM・TTS(近日)の3機能を1つにまとめる
・核となる発想:音声を「連続的な埋め込み」ではなく「離散トークン」に変換し、テキストLLMと同じ土俵に乗せる。これによりLlama 3に直接「聞く」能力を与えられる
・実力と注意:多言語WER(viVoice 11.68)でベースのWhisperを上回る一方、純英語ではベースに及ばない。Ichigo-LLMは実験段階で、リポジトリにLICENSEファイルがなく商用利用は要確認
Ichigoとは——音声タスクを1つの表現に統一する音声パッケージ
Ichigoは「音声技術の急速な進化が求める、シンプルで統一された解」を標榜する。READMEの言葉を借りれば、煩雑な音声処理の内部事情を切り離し、直感的なPythonインターフェースかスケーラブルなFastAPIサービスを通じて、強力な音声モデルへ手軽にアクセスさせることがねらいだ。
このパッケージが担うのは次の3タスクで、いずれも推論コードのみを含む。学習用コードは同梱されず、ローカル推論のユースケースに焦点を絞っている。
・Ichigo-ASR:自動音声認識(Automatic Speech Recognition)。音声をテキストや離散トークンへ変換する
・Ichigo-TTS:Text to Speech。READMEでは「Coming Soon(近日公開)」とされる
・Ichigo-LLM:音声言語モデル(実験的)。テキストLLMに「聞く」能力を持たせる研究プロジェクト
ここで重要なのは、Ichigoが単なる「便利ラッパー」ではなく、音声タスクを単一の表現フレームワークへ統一するという思想で設計されている点だ。今日の多くの音声モデルは、1タスク向けにエンドツーエンドで学習されたモノリシックな構成になっている。しかしIchigoのチームは、ASRとTTSの部品は本来共有・再利用できると考える。
アーキテクチャ:ASRとTTSが「同じ言葉」を話す
下の図はREADMEに掲載された俯瞰図で、Ichigoが「あなたのおじいちゃんの音声パッケージではない(Not your grandfather’s speech package)」と称する理由を示している。ASRとTTSをモジュール化し、共通コンポーネントを共有させることで、両者が同じ表現言語を話すようにしている。
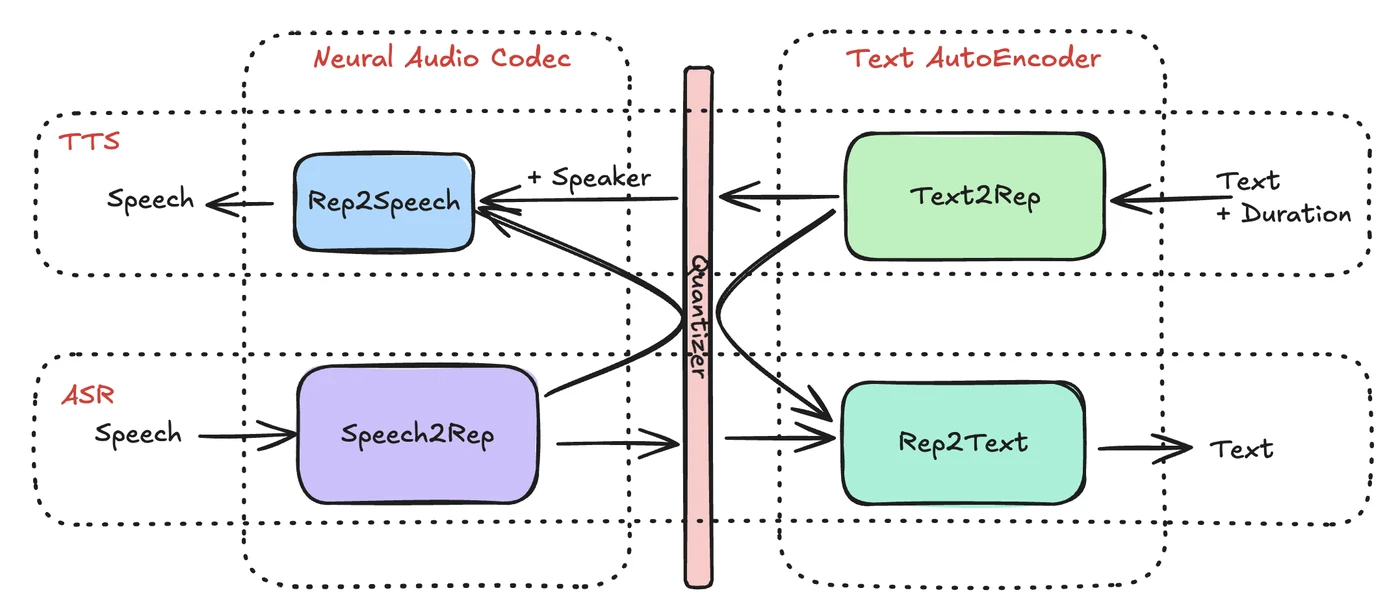
この設計の利点は明快だ。ASR用のデータでTTSを学習させたり、その逆を行ったりできる。READMEは「ASRのファインチューニングがTTSの事前学習になり得る」と説明し、限られた学習データでもモデルをブートストラップできるとする。さらにチーム独自の「Speechless」というモデルを使えば、音声を一切使わずに音声言語モデルを学習できる(論文は準備中)という。
Ichigo-LLM側の中核は「早期融合(early fusion)」だ。音声を離散トークンに変換し、テキストと同じ語彙空間へ混ぜ込んでから、単一のTransformerで両モダリティをまとめて推論する。アダプタを後付けするのではなく、入力段階で融合する点が特徴で、Metaの「チャメレオン(Chameleon)」論文の混合モーダル早期融合の考え方に着想を得ている。
(WAVなど)"] --> B["Ichigo-ASR
Whisper-medium ベースの
22M音声トークナイザー"] B --> C["離散・音トークン列
<|sound_1012|> ..."] C --> D["早期融合
テキストと同じ語彙空間へ"] D --> E["Llama 3
単一Transformerで推論"] E --> F["テキスト応答
(オンデバイスSiri相当)"] C -.S2T.-> G["文字起こしテキスト"]
論文「Ichigo: Mixed-Modal Early-Fusion Realtime Voice Assistant」(Dao, Vu, Ha, 2024)によれば、この早期融合構成はアダプタを使わずにモダリティ横断の推論・生成を実現し、最初のトークン生成まで111msと、既存モデルより大幅に低いレイテンシを報告している。音声質問応答(speech QA)ベンチマークでは、オープンソースの音声言語モデルを上回り、カスケード型システムに匹敵する性能を示したとされる。
3つのコンポーネントを個別に見る
Ichigo-ASR:Whisperを離散トークン化する22Mモデル
Ichigo-ASRは、Whisper-medium モデル向けのコンパクト(22Mパラメータ)なオープンソース音声トークナイザーだ。多言語性能を高めつつ、元の英語能力への影響を最小限に抑えることを目的に設計されている。
Whisperのような一般的なモデルが連続的な埋め込みを出力するのに対し、Ichigo-ASRは音声を離散トークンへ圧縮する。これがLLMとの相性を決定的に良くする。LLMはもともと離散トークン(語彙)を扱う仕組みなので、音声も離散トークンで渡せば、画像や音声用の特別なアダプタを噛ませずに「音声をそのまま読む」ことができる。学習データは英語約400時間・ベトナム語約1,000時間で、多言語を意識した構成だ。
Ichigo-LLM:Llama 3に「耳」を与える実験
Ichigo-LLMは、テキストベースのLLMにネイティブな「聞く」能力を持たせる、進行中のオープンな研究実験だ。READMEはこれを「オープンデータ・オープンウェイトのオンデバイスSiri」と表現する。ベースはLlama 3系で、開発元の公式解説(v0.3)ではLlama 3.1 8Bを軸にした構成が示されている。
v0.3チェックポイントの公式解説(menlo.ai)では、実用上重要な4つの改良が挙げられている。
・多言語化:英語のみからMultilingual LibriSpeechを用いた7言語データセットへ拡張
・汎用能力の回復:MMLUがPhase 1後の0.42から0.63まで回復し、劣化を約10%に抑制
・非音声の扱い:聞き取れない入力に対する「拒否(refusal)」挙動を実装
・マルチターン対応:会話のターンをまたいだ文脈理解を強化(Phase 3は15万サンプル。うち90%が2ターン、10%が4ターン以上)
非音声の扱いは設計が面白い。WhisperVQのコードブックにある513個の音トークンを「似たパターンの並び」にランダム生成し、合成の「聞き取れないデータ」を作る。意味のある音声は 513の50乗という膨大な並びのごく一部にすぎない——だからこそ、混沌としたトークン列を「非音声」と判別し、「I cannot hear(聞き取れません)」と応答できるようになる、という発想だ。
Ichigo-TTS:Coming Soon
音声合成(TTS)はREADME上で「Coming Soon」とされ、現時点では未提供だ。ただし前述のとおり、ASRとTTSが部品を共有する設計のため、ASR側の資産がTTS実装の土台になることが見込まれている。
インストールと基本的な使い方
導入はパッケージのインストール1行から始まる。
pip install ichigo
単一ファイルの文字起こしは、transcribe をワンライナーで呼ぶだけだ。同じフォルダに transcription.txt も書き出される。
# 単一ファイルの文字起こし
from ichigo.asr import transcribe
results = transcribe("path/to/your/file")
# 期待される出力: "{filename: transcription}"
フォルダを渡せばバッチ処理になり、各ファイルの結果がサブフォルダ内に filenameN.txt として保存される。
# フォルダ単位のバッチ文字起こし
from ichigo.asr import transcribe
results = transcribe("path/to/your/folder")
# 期待される出力: "{filename1: transcription1, ... filenameN: transcriptionN}"
フロントエンド連携には、同梱のFastAPIサーバーを使う。バッチ処理に対応する一方、ストリーミングは現時点で未対応である。
# Uvicornで起動
cd api && uvicorn asr:app --host 0.0.0.0 --port 8000
# または Docker
docker compose up -d
APIは3種類のエンドポイントを持つ。S2T(音声→テキスト)に加え、Ichigoらしい S2R(音声→表現=音トークン列)と R2T(音トークン列→テキスト)が分かれているのが特徴だ。離散トークンを中間表現として外に出せるため、LLMへの受け渡しを自前で組める。
# S2T: 音声を文字起こし
curl "http://localhost:8000/v1/audio/transcriptions" \
-H "accept: application/json" \
-H "Content-Type: multipart/form-data" \
-F "[email protected]" -F "model=ichigo"
# S2R: 音声を音トークン列(表現)に変換
curl "http://localhost:8000/s2r" \
-H "accept: application/json" \
-H "Content-Type: multipart/form-data" \
-F "[email protected]"
# R2T: 音トークン列をテキストへ復号
curl "http://localhost:8000/r2t" -X POST \
-H "accept: application/json" \
-H "Content-Type: application/json" \
--data '{"tokens":"<|sound_start|><|sound_1012|><|sound_1508|> ... <|sound_end|>"}'
APIドキュメントは起動後 http://localhost:8000/docs で確認できる。
ベンチマーク:公称値で見る実力と弱点
まずIchigo-ASRの音声認識精度(WER=単語誤り率、低いほど良い)。READMEの公式表をそのまま再現する。比較対象は同系統のwhispervq、およびベースとなるOpenAIのwhisper medium.enだ。
| モデル | LS Clean | LS Other | Earnings22 | LargeScaleASR | viVoice(多言語) |
|---|---|---|---|---|---|
ichigo-asr-2501-en | 4.28 | 9.35 | 35.55 | 16.09 | 11.68 |
whispervq-2405-en | 9.79 | 14.40 | 38.45 | 18.38 | — |
whisper medium.en | 2.88 | 6.04 | 16.64 | 8.21 | 18.30 |
この表は正直に読む必要がある。純粋な英語(LibriSpeech Clean/Other、Earnings22)では、ベースのmedium.enがなお最良で、Ichigo-ASRは及ばない。一方で多言語のviVoiceでは、Ichigo-ASRの11.68がmedium.enの18.30を明確に上回る。つまりIchigo-ASRの価値は「英語で最高精度を出すこと」ではなく、「離散トークン化でLLM連携を可能にしつつ、多言語で素のWhisperを上回る」点にある。同系統のwhispervqに対しては全項目で優位だ。
次にIchigo-LLMの音声理解。AudioBench(GPT-4oを審査者とする0〜5スコア、高いほど良い)の公称値が公式解説に示されている。
| モデル | Open-Hermes | Alpaca |
|---|---|---|
| Ichigo v0.3-phase3 | 3.64 | 3.68 |
| Ichigo v0.2 | 3.45 | 3.53 |
| Qwen2-Audio-7B | 2.63 | 2.24 |
v0.3はv0.2から着実に伸び、同じ音声理解タスクでQwenのAudio版を上回ると報告されている。あわせて、汎用知識のMMLUがPhase 1後の0.42から0.63まで戻った点も、「音声を足したら言語能力が落ちる」という典型的な副作用を抑えられたことを示している。
ベンチマークの読み方(注意)
・WERは低いほど良い、AudioBenchは高いほど良い。指標の向きが逆なので混同しない
・いずれも開発元による公称値で、第三者の独立検証ではない
・英語単体の精度を最優先するなら素のWhisperが堅実。Ichigoの強みは「離散トークン化によるLLM連携」と「多言語」にある
ユースケース:どんなときに刺さるか
Ichigoが向くのは、クラウドの音声APIに頼らずローカル完結で音声を扱いたい場面だ。具体的には次のような用途が考えられる。
・ローカル文字起こしの組み込み:pip install とワンライナーで、議事録・インタビュー・録音メモのバッチ文字起こしを自前アプリへ組み込む
・プライバシー重視の音声処理:音声を外部送信せず、オンプレ/端末内で完結させたいケース
・音声対応LLMの研究・試作:早期融合でテキストLLMに「聞く」能力を足す実験。離散トークン(S2R/R2T)を中間表現として取り出し、独自パイプラインを組める
・多言語の音声認識:英語以外(ベトナム語など)を含む環境で、素のWhisperより誤りを減らしたい場合
逆に、英語のみで最高精度を求める用途や、リアルタイムのストリーミング文字起こしが必須の用途では、現時点のIchigoは最適解になりにくい。後者はストリーミング未対応のためだ。
類似OSSとの比較
音声をLLMにつなぐOSSは増えている。Ichigoのポジションを、代表的なプロジェクトと並べて整理する。
| プロジェクト | 主な役割 | LLM連携の方式 | 特徴 |
|---|---|---|---|
| Ichigo(janhq) | ASR+音声LLM+TTS(近日) | 早期融合・離散トークン | 音声を離散トークン化しLlama 3に直接融合。ローカル完結志向 |
| OpenAI Whisper | ASR(文字起こし) | 連続埋め込み | 英語精度が高く定番。LLM連携は別途実装が必要 |
| WhisperSpeech | TTS(音声合成) | Whisper反転 | Ichigoが合成音声生成・謝辞で参照する基盤の一つ |
| Qwen2-Audio | 音声理解LLM | 音声エンコーダ+LLM | 汎用の音声対話。AudioBenchでIchigo v0.3が上回ると報告 |
Ichigoの差別化点は、音声を「LLMが読める離散トークン」に変換する設計を中核に据えていることだ。Whisperが「文字起こしまで」を担うのに対し、Ichigoは文字起こし(S2T)に加えて、音声→トークン(S2R)とトークン→テキスト(R2T)を分離して提供し、その上でLLMへの早期融合まで一気通貫で扱おうとする。
OpenAI Whisper"] R --> B["音声合成
WhisperSpeech"] R --> C["音声理解LLM
Qwen2-Audio"] R --> D["離散トークンで早期融合
Ichigo (janhq)"] D --> D1["S2T: 文字起こし"] D --> D2["S2R / R2T: 音トークンを外出し"] D --> D3["Llama 3 にネイティブな聴覚"]
制限と注意点
導入前に押さえておきたい制約を、READMEと公式解説の記載ベースで挙げる。
・ライセンスが明示されていない:2026年6月時点でリポジトリにLICENSEファイルがなく、GitHub APIでもライセンスは未検出。商用利用・再配布の前に、Hugging Face(homebrewltd配下)の各モデル表記とベースのLlama 3条件を必ず確認する
・Ichigo-LLMは実験段階:READMEは「ongoing research experiment」「すべて進行中(work in progress)」と明記。本番採用には慎重な検証が要る
・ストリーミング未対応:FastAPIはバッチ処理対応だが、逐次ストリーミングはサポートされない
・TTSは未提供:Ichigo-TTSは「Coming Soon」。現状はASRと音声LLMが中心
・英語単体ではベースに及ばない:純英語のWERはwhisper medium.enが上。Ichigoの優位は多言語とLLM連携にある
・更新状況:リポジトリの最終更新は2025年11月(pushed)。活発な日次更新が続くフェーズかは導入時に確認したい
公称ベンチマークはいずれも開発元の自己申告であり、自分のデータ・言語・録音環境での実測が最終的な判断材料になる。まずはIchigo-ASRをバッチ文字起こしで試し、要件に合えばS2R/R2TやIchigo-LLMへ踏み込む、という順序が現実的だ。
まとめ
Ichigoは、「音声をLLMが読める離散トークンに変える」という一点に賭けたローカル音声AIパッケージだ。pip install ichigo とワンライナーで多言語のバッチ文字起こしが動き、その先には早期融合でLlama 3に「耳」を与えるIchigo-LLM、そしてASR/TTSが部品を共有する統一フレームワークの構想が広がる。
実力は領域で割れる。純英語の文字起こし精度では素のWhisperに譲るが、多言語WER(viVoice 11.68)とLLM連携のしやすさ、最初のトークンまで111msという低レイテンシは明確な武器だ。一方でライセンス未明示・実験段階・ストリーミング未対応といった制約もあり、用途を選ぶ。クラウドに音声を出さずローカルで音声AIを試したい開発者にとって、まず触ってみる価値のあるOSSである。
参照ソース
・janhq/ichigo — GitHub(公式リポジトリ・README)(機能・インストール・API・WERベンチマーク・謝辞の出典)
・Ichigo: Mixed-Modal Early-Fusion Realtime Voice Assistant — arXiv:2410.15316(早期融合アーキテクチャ・111msレイテンシ・speech QA性能の出典)
・Llama Learns to Talk(Ichigo v0.3 Checkpoint Writeup)— menlo.ai(v0.3の改良点・MMLU回復・非音声拒否・マルチターン・AudioBench値の出典)
・Chameleon: Mixed-Modal Early-Fusion Foundation Models — arXiv:2405.09818(早期融合の着想元として論文が参照)
・WhisperSpeech — GitHub(collabora/LAION)(Ichigoが謝辞・合成音声生成で参照する基盤)
参考
・本文中の数値・挙動は、上記の公式リポジトリREADME・arXiv論文・開発元公式解説(menlo.ai)に記載のもののみを採用した。READMEに記載のないレイテンシ・ライセンス・運用挙動は本文中で「公式未記載」「要確認」と明示している
・GitHubスター数(約2,484)・最終更新(2025年11月)はGitHub API実測値(2026年6月時点)





