
30秒で理解する oh-my-mermaid
- 何をするツールか:コードベースをAIに解析させ、Mermaid図つきのアーキテクチャドキュメントを
.omm/に自動生成するCLI+スキル - 誰のためか:AIが量産したコードの全体像を見失った開発者、新規参画者にコードを説明したいチーム
- 使い方:
npm install -g oh-my-mermaid && omm setup→ AIツールで/omm-scan→omm view - 正体:MIT・TypeScript製・約1,367星。Claude Code / Codex / Cursor / OpenClaw / Antigravity 対応
- 既存ツールとの差:Mermaidを「描く」のではなくAIに「生成させる」。出力はGit管理できるローカルファイル
AIは数秒でコードを書く。だが人間がそれを理解するには数時間かかる。理解を後回しにしたまま機能を積み増していくと、コードベースは書いた本人にとってさえブラックボックスになる。oh-my-mermaid(コマンド名はomm)は、このギャップを埋めるために生まれた。コードベースをAIに解析させ、人間が読むためのアーキテクチャドキュメントを自動生成する。
特徴は「図を描くツール」ではなく「図を生成させるツール」である点だ。Mermaid Live EditorやVSCodeのプレビュー拡張は、人間が書いたMermaid記法を描画してくれる。oh-my-mermaidは逆で、コードベースをAIに読ませて図そのものを作り出す。生成された図とドキュメントは.omm/ディレクトリにMarkdownとMermaidファイルとして残り、Gitで履歴管理できる。
Claude Code全体の使い方は Claude Code完全ガイド2026:インストールから本番運用まで をご覧ください。
oh-my-mermaidとは——AIで構成図を生成するOSS
oh-my-mermaidは、2026年3月に公開されたTypeScript製のオープンソースツールだ。GitHub上の組織アカウントoh-my-mermaidが開発し、2026年6月時点でスター数は約1,367、フォーク122、ライセンスはMITとなっている。package.jsonの説明文では自らを「Architecture mirror for vibe coding — CLI + Claude Code skills」と位置づけている。vibe coding、つまりAIに任せて書かせる開発スタイルで失われがちな「全体像」を映し出す鏡、という意味合いだ。
このツールの中心にある問いはシンプルだ。AIエージェントに任せてコードを量産すると、動くものはできる。だが「どこで認証しているのか」「このデータはどこから来てどこへ行くのか」という構造的な理解は置き去りになる。レビューも引き継ぎも、結局は人間が構造を理解していないと成立しない。oh-my-mermaidは、その構造理解の部分をAIに肩代わりさせる。
主要スペック
oh-my-mermaid 基本情報(2026-06時点)
- リポジトリ:oh-my-mermaid/oh-my-mermaid(GitHub)
- スター / フォーク:約1,367 / 122
- ライセンス:MIT
- 言語:TypeScript(一部 HTML / JavaScript、生成物に Mermaid)
- パッケージ:npm
oh-my-mermaid(CLIコマンドはomm)、v0.2.0系 - 必要環境:Node.js 18以上
- 対応AIツール:Claude Code / Codex / Cursor / OpenClaw / Antigravity
ポイントは、oh-my-mermaid自体はモデルを内蔵していないことだ。コードの解析は、あなたが普段使っているAIコーディングツール(Claude Codeなど)に任せる。ommはそのツールに「コードを構造的に読んでMermaid図とドキュメントに落とせ」という手順(スキル)を登録し、生成物を整理された.omm/ツリーとして保存・可視化する役割を担う。LLMを抱え込まない薄いレイヤーだからこそ、複数のAIツールに横展開できている。
デモで見る——/omm-scanからビューアまで
公式リポジトリには「omm scanned itself(ommが自分自身をスキャンした)」というデモが置かれている。下のGIFは、生成されたアーキテクチャをインタラクティブビューア(omm view)で閲覧している様子だ。
GIFの左側に並ぶツリーが、生成された「perspective(視点)」とその要素だ。command-surface配下にはCLIのサブコマンド群(init・login・push・scan・view…)、overall-architecture配下にはPlatforms・Commands・Server・Storeといったモジュールが並ぶ。キャンバス側ではそれぞれのMermaid図がノードグラフとして描かれ、ズームやパンで全体と詳細を行き来できる。文字起こしのドキュメントではなく、構造そのものを地図として歩ける点がこのツールの体験の核だ。
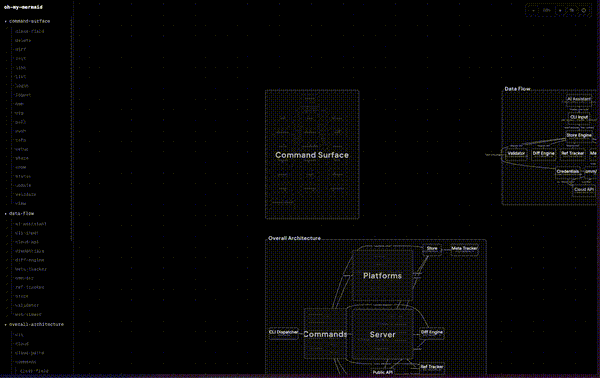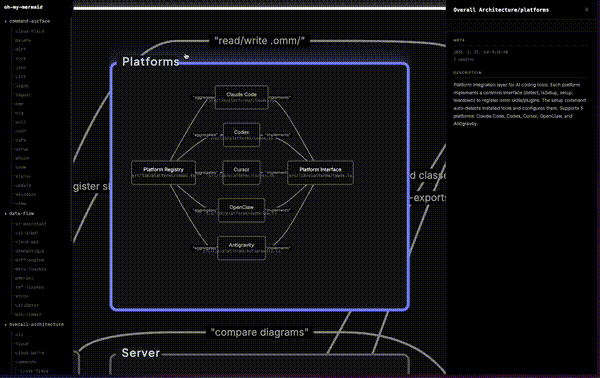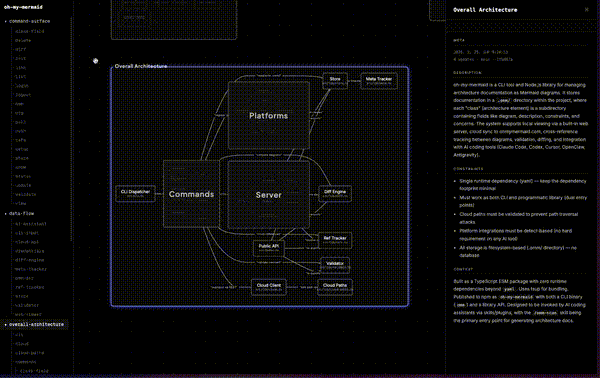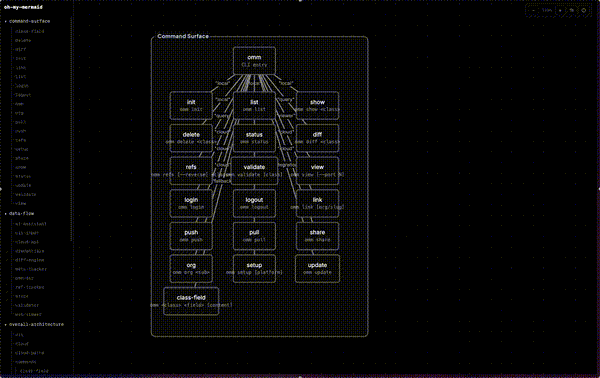
下の静止画は「Overall Architecture」視点を拡大したものだ。CLI DispatcherからCommandsへ、そしてServer内の各エンジン(Diff Engine・Ref Tracker・Validator)やStore・Public APIへと、依存と呼び出しの関係が線で結ばれている。
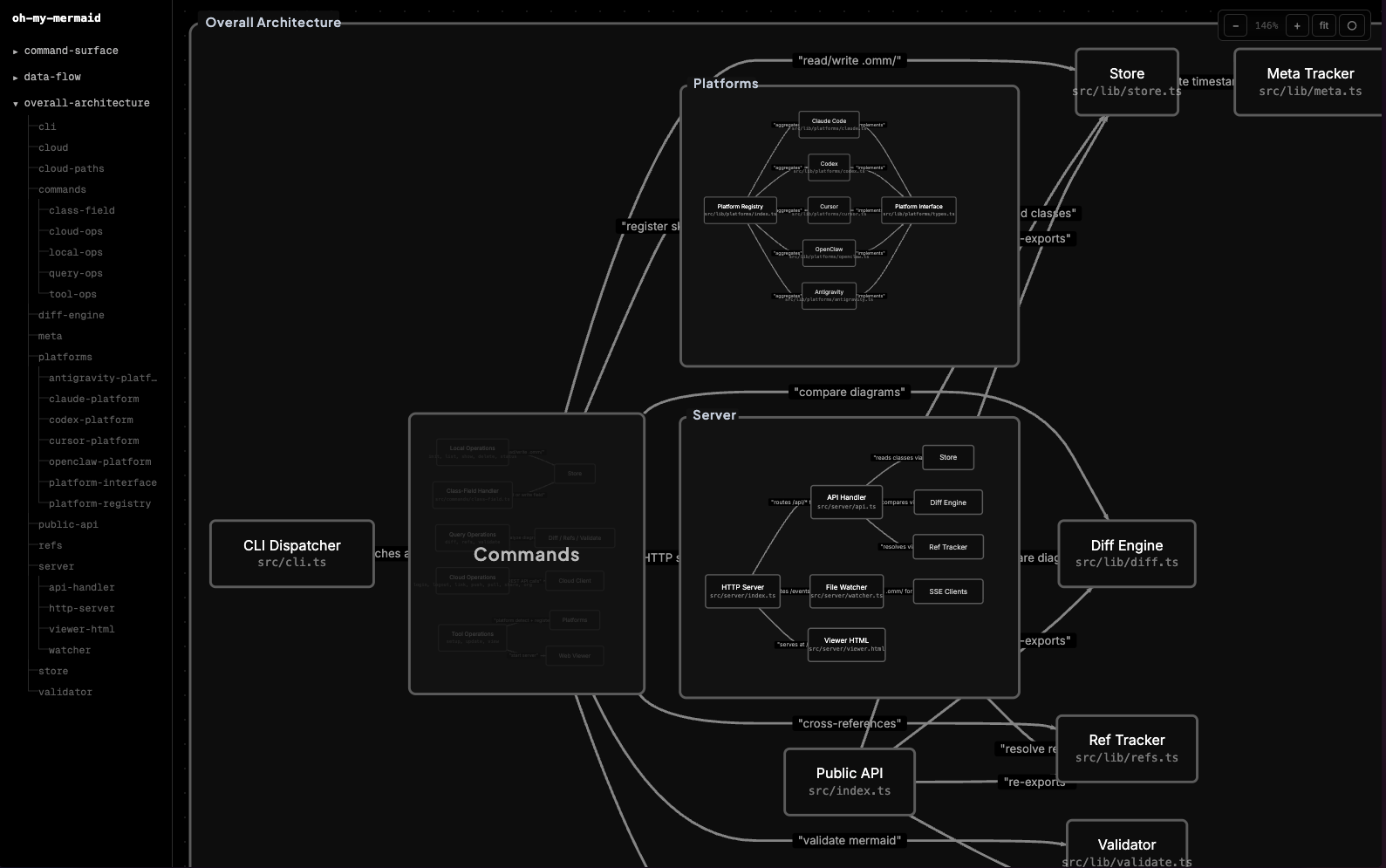
生成例を読む——omm自身のスキャン結果
上の静止画は、ommが自分自身のコードベースをスキャンして生成した「Overall Architecture」だ。読み解くと、このツールの図がどの粒度まで踏み込むかが分かる。中央のCommandsから放射状にCLI Dispatcher・Server・Store・Public APIが伸び、Serverの内部にはさらにDiff Engine・Ref Tracker・Validatorといった子要素が描かれている。各ノードの下に小さく添えられているのが実体のファイルパスで、図のノードがコードのどこに対応するかを追えるようになっている。
左サイドバーにはcommand-surface・data-flow・overall-architectureという3つのperspectiveが並び、それぞれを展開すると配下の要素にジャンプできる。command-surfaceを開けばinit・login・push・scan・viewなどのサブコマンドが、data-flowを開けばAI AssistantからCLI Input・Store Engine・Validator・Cloud APIへと流れるデータの経路が見える。同じコードベースでも、見たい関心事に応じて図を切り替えられるのがperspective設計の利点だ。文章の設計書なら章を行き来して読み解くところを、ommは図のレイヤーを切り替えるだけで済む。
仕組み——perspectiveと再帰的ドリルダウン
oh-my-mermaidの生成ロジックは「perspective(視点)」と「再帰分析」の2つで説明できる。
perspectiveとは、アーキテクチャを見るためのレンズだ。同じコードベースでも「全体構造」で見るのと「データフロー」で見るのとでは描くべき図が変わる。ommのスキル定義(/omm-scan)には視点カタログが用意されていて、AIはコードベースに実在するものだけを選んで図を起こす。
perspectiveカタログ(抜粋)
・overall-architecture:常に作成。何が存在しどう関係するか
・request-lifecycle:サーバー/APIがある場合。リクエストの入口から処理完了まで
・data-flow:データ処理・DB利用がある場合。データの発生・変換・着地点
・dependency-map:複雑なモジュールグラフ。何が何に依存し、何が共有されるか
・external-integrations:外部API/サービス連携。何にどんな目的で接続するか
・command-surface:CLIツール。コマンド階層とディスパッチ
・state-transitions:ステートフルな機能。状態が何をきっかけにどう変わるか
もう一つの柱が再帰的ドリルダウンだ。AIは図の中の各要素を順に分析し、内部構造を持つ要素は独自の図を持つ「子要素」へと展開する。単純な要素はそのままリーフ(葉)として残る。この階層がそのままファイルシステムのツリーになる点が、ommの設計のユニークなところだ。
.omm/
├── overall-architecture/ ← perspective(視点)
│ ├── description.md
│ ├── diagram.mmd
│ ├── context.md
│ ├── main-process/ ← ネストされた子要素
│ │ ├── description.md
│ │ ├── diagram.mmd
│ │ └── auth-service/ ← さらに深いネスト
│ │ └── ...
│ └── renderer/
│ └── ...
├── data-flow/
└── external-integrations/
ビューアはこのファイルツリーからネストを自動検出する。子を持つ要素は展開可能なグループとして、それ以外はノードとして描画される。各要素は最大7つのフィールド——description・diagram・context・constraint・concern・todo・note——を持てる。単なる図ではなく、制約(constraint)や懸念(concern)、TODOまで構造に紐づけて残せるのが、設計ドキュメントとしての強みだ。
各要素が持てる7フィールド
・description:その要素が何であるかの説明
・diagram:その要素の内部構造を表すMermaid図(.mmd)
・context:背景・前提・なぜこうなっているかの文脈
・constraint:守るべき制約(変えてはいけない仕様・依存関係)
・concern:懸念点・リスク・技術的負債のメモ
・todo:今後の作業・改善の宿題
・note:その他の補足
注目したいのはconstraint・concern・todoの3つだ。多くの図ツールは「構造を描く」ところで止まるが、ommは「この箇所はこの制約があるから触るな」「ここに負債が溜まっている」「ここは後で直す」といった、レビューや引き継ぎで本当に必要になる情報を、図の各ノードに直接ぶら下げられる。図が陳腐化しがちな理由は構造とメモが分離しているからだが、ommはそれを同じツリーに統合している。
なぜファイルとして残すのか
oh-my-mermaidが生成物をクラウドのDBではなくローカルのファイルツリーに置くのには理由がある。第一にGitに乗ること。.omm/をコミットすれば、コードの変更とアーキテクチャドキュメントの変更が同じ履歴に並ぶ。PRのdiffで「この変更で構造がどう変わったか」を一緒にレビューできる。第二にプレーンテキストであること。diagram.mmdはMermaid、各フィールドはMarkdownなので、専用ビューアがなくてもエディタで読めるし、他ツールへの移植も効く。第三に、要素IDと子ディレクトリ名が一致する規約により、図のノードと実体のドキュメントが機械的に対応する。ビューアはこの対応をファイルシステムから解決するだけでよく、状態を二重管理しない。
入力から出力までの流れを図にすると次のようになる。
src / package.json] --> B{/omm-scan
AIコーディングツールが解析} B --> C[perspective選定
overall-architecture など] C --> D[各要素を再帰分析
複雑なら子要素へ展開] D --> E[.omm/ ツリー生成
diagram.mmd + *.md] E --> F[omm view
インタラクティブ図ビューア] E --> G[Git管理 / omm push
チーム共有]
インストールと基本的な使い方
導入は3ステップで完了する。まずグローバルインストールとセットアップを一度に行う。
npm install -g oh-my-mermaid && omm setup
omm setupはインストール済みのAIコーディングツールを自動検出し、各ツールにスキルを登録する。特定のツールだけに入れたい場合は引数で指定できる。
omm setup claude # Claude Code に登録
omm setup codex # Codex に登録
omm setup cursor # Cursor に登録
次に、AIコーディングツール(ターミナルではなくツール内)でスキルを実行する。スキルは/で始まるコマンドとして登録されている。
/omm-scan
これでコードベースが解析され、.omm/にドキュメントが生成される。あとはビューアを開くだけだ。
omm view # インタラクティブビューアをブラウザで開く
日本語でドキュメントを生成したい場合は、スキャン前に言語を設定しておく。要素のID・ディレクトリ名・ノードIDは常に英語のkebab-caseのままだが、descriptionやcontextなどの本文フィールドが指定言語で書かれる。
omm config language ja # 本文フィールドを日本語に
omm config language # 現在の設定を確認
主要なCLIコマンドは次の通りだ。フルリストはomm helpで確認できる。
主要CLIコマンド
・omm setup:AIツールにスキルを登録(自動検出)
・omm view:インタラクティブビューアを開く
・omm config language <lang>:本文フィールドの言語を設定
・omm update:最新バージョンに更新
・omm login / omm link / omm push:クラウド保存・共有
・omm help:全コマンド一覧
/omm-scanは中で何をしているか
/omm-scanは単に「AIに図を描かせる」だけのスキルではない。公開されているSKILL.mdを読むと、解析が再現性を持つように手順が段階化されている。中身を理解しておくと、出力をレビューするときの目の付けどころが分かる。
/omm-scan の処理ステップ(SKILL.mdより要約)
・Step 0:言語確認——omm config languageで本文フィールドの出力言語を確認する
・Step 1:コードベース探索——package.json等のマニフェスト、トップレベルのディレクトリ、主要エントリポイント、ルート定義・サービス層・DB接続・外部連携を読む
・Step 2:perspective選定——視点カタログから、このコードベースに実在する視点だけを選ぶ(存在しない視点を無理に作らない)
・Step 3:再帰ドリルダウン——各perspectiveの図を書き、要素ごとに内部構造があれば子要素へ展開していく
ここで効いているのが「実在しない視点を作らない」という指示だ。たとえばCLIツールならcommand-surfaceが、APIサーバーならrequest-lifecycleが選ばれるが、該当しないものは生成されない。コードの実態に合わない汎用テンプレを貼り付けるのではなく、リポジトリごとに必要な視点だけを起こすため、生成物が現実と乖離しにくい。前提としてSKILL.mdは冒頭でommコマンドの存在を確認し、未インストールなら「npm install -g oh-my-mermaidを実行してから再試行して」とユーザーに促す設計になっている。
なお、要素のID・ディレクトリ名・図のノードIDは設定言語に関わらず常に英語のkebab-caseで統一される。日本語化されるのはdescriptionやcontextなどの本文だけだ。これにより、日本語チームでも図の構造(IDの対応)は崩れず、本文だけが読みやすくなる。
主要機能——スキル・マルチツール対応・クラウド共有
oh-my-mermaidの機能は、大きく「スキル」「マルチAIツール対応」「クラウド共有」の3つに分けられる。
まずスキルだ。ommが提供するスキルはAIコーディングツール内で実行するコマンドで、ターミナルのCLIとは別物だ。現状の主なスキルは2つある。
oh-my-mermaid のスキル
- /omm-scan:コードベースを解析し、アーキテクチャドキュメントを生成・更新する
- /omm-push:ログイン+リンク+クラウドへのプッシュを一括で実行する
/omm-scanのスキル定義(SKILL.md)を読むと、AIへの指示が丁寧に設計されているのが分かる。最初にomm config languageで出力言語を確認し、package.jsonなどのマニフェストを読み、トップレベルのディレクトリからモジュール境界を把握する。そのうえで視点カタログから「このコードベースに実在する視点」だけを選び、要素ごとに再帰的に図を起こす。AIに丸投げするのではなく、解析の手順を構造化して渡しているのが、出力が安定する理由だ。
次にマルチAIツール対応。oh-my-mermaidは特定のツールに縛られない。omm setupを実行すれば、インストール済みのツールをまとめて設定してくれる。
| プラットフォーム | セットアップコマンド |
|---|---|
| Claude Code | omm setup claude |
| Codex | omm setup codex |
| Cursor | omm setup cursor |
| OpenClaw | omm setup openclaw |
| Antigravity | omm setup antigravity |
そしてクラウド共有だ。生成したアーキテクチャはohmymermaid.com経由でクラウドに保存できる。
omm login && omm link && omm push
デフォルトは非公開で、チームへの共有や公開リンクとしての公開も選べる。クラウドを使わず、.omm/をそのままGitリポジトリにコミットしてレビューやPRに載せる運用も可能だ。生成物がプレーンなMarkdown+Mermaidファイルである強みがここで効いてくる。クラウドに上げればURLひとつで最新のアーキテクチャを共有でき、Gitに乗せればコードの変更と同じPRで構造の変化をレビューできる。チームの運用スタイルに合わせて、ローカル完結・Git共有・クラウド共有の3つを選べるのは実務上ありがたい。
実践ユースケース——どこで効くか
oh-my-mermaidが本当に効くのは、コードの量が人間の理解の速度を追い越した場面だ。代表的な使いどころを挙げる。
oh-my-mermaidが効く場面
・AIで量産したコードの棚卸し:vibe codingで一気に作った後、全体像を取り戻す
・新規参画者のオンボーディング:「どこで認証している?」を図で先に渡す
・レビュー前の構造把握:PRの前に対象モジュールのdata-flowを生成して論点を整理
・引き継ぎドキュメントの土台:constraint / concern / todo フィールドに注意点を残す
・リファクタ計画:dependency-mapで依存の集中点(god node)を見つける
たとえば新メンバーのオンボーディングなら、流れはこうなる。リポジトリをクローンしてもらい、/omm-scanを一度走らせ、omm viewで全体像を一緒に眺める。テキストの設計書を読ませるより、構造を歩きながら説明したほうが圧倒的に速い。生成物はGitに乗るので、コードが変わったら再スキャンしてドキュメントを更新すればよい。
公式のdocs/ROADMAP.mdには、今後の方向性として「サブエージェントによる並列スキャンパイプライン」「変更ファイルだけを検出する差分解析(incremental analysis)」「ビューア内の自然言語検索(”where does auth happen?”で該当要素を探す)」「新規開発者向けの/omm-guideオンボーディングスキル」が挙げられている。差分解析が入れば、毎回フルスキャンせずに変わった部分だけ更新できるようになり、運用コストはさらに下がる見込みだ。
なお、コードベースの探索そのものを軽くしたいなら、知識グラフ系のアプローチも併用できる。Claude Codeのツールコール削減を狙うなら CodeGraph完全解説|Claude Codeのツールコール71%削減・コスト35%節約するローカル知識グラフOSS が参考になる。CodeGraphは「エージェントの探索を速くする」ためのインデックスで、oh-my-mermaidは「人間が読む構成図を残す」ためのドキュメント生成と、狙う層が異なる。
スキル自体の仕組みをもっと知りたい場合は Claudeスキル(Skills)とは?仕組み・作り方・活用例を図解 もあわせて読むと、/omm-scanがどう動いているか理解しやすい。
既存のMermaidツールとの比較
「Mermaid」と名がつくツールは多いが、oh-my-mermaidの立ち位置は他とはっきり違う。多くは「人間が書いたMermaidを描画する」レンダラーであり、ommは「AIにMermaidを生成させる」ジェネレーターだ。代表的なツールと比較する。
| ツール | 種別 | 図の作り方 | コードベース解析 | 出力の保存 | 主な用途 |
|---|---|---|---|---|---|
| oh-my-mermaid | CLI+AIスキル | AIが自動生成 | あり(再帰分析) | .omm/にmd+mmd(Git可) |
コード全体の構成ドキュメント化 |
| Mermaid Live Editor | Webエディタ | 人間が手書き | なし | 手元で保存/共有リンク | 単発の図を素早く作る |
| VSCode Mermaid Preview | エディタ拡張 | 人間が手書き | なし | Markdown内に埋め込み | 執筆中のプレビュー |
| Mermaid CLI(mmdc) | CLI | 既存の.mmdを画像化 | なし | PNG/SVG出力 | CIで図を画像化 |
| 汎用AIチャットに依頼 | 手動プロンプト | AIが生成(都度) | 限定的(貼った範囲) | チャット履歴のみ | アドホックな図出し |
差別化の軸を整理すると次のようになる。
oh-my-mermaidを選ぶ理由 / 選ばない理由
- 選ぶ:コードベース全体を構造的にドキュメント化したい/生成物をGitで管理・レビューしたい/複数AIツールで使い回したい
- 選ぶ:再帰的な階層(perspective → 要素 → 子要素)で大規模コードを整理したい
- 選ばない:単発の図を1枚さっと描きたいだけ(Live Editorで十分)
- 選ばない:既に手書きした.mmdをCIで画像化したいだけ(mmdcで十分)
ポイントは、これらは競合というより役割分担だということだ。日々の図はLive EditorやVSCodeプレビューで書き、コードベース全体の構成ドキュメントはoh-my-mermaidでAIに生成させる、という併用が現実的な使い分けになる。
制限事項と注意点
導入前に押さえておきたい制約もある。誇張せず事実ベースで挙げる。
注意しておきたい点
・解析品質はAIツール依存:ommはモデルを内蔵せず、解析はClaude Codeなど外部ツールが行う。出力の精度は使うモデルに左右される
・生成物は要レビュー:AI生成のドキュメントである以上、図やdescriptionが実装と食い違う可能性がある。鵜呑みにせず確認する
・スキャンのコスト:大規模コードベースの再帰分析はトークンを消費する。差分解析(incremental)はロードマップ段階で、現状はフルスキャン中心
・バージョンは発展途上:npmはv0.2.0系で、機能や出力フォーマットが今後変わる可能性がある
・クラウド機能は別管理:CLI本体はMITのOSSだが、ohmymermaid.comのクラウド共有は別サービス。共有範囲(非公開/公開)を必ず確認する
特に意識したいのは「AI生成ドキュメントは初稿である」という前提だ。oh-my-mermaidは構造把握の出発点を高速に作ってくれるが、最終的な正確さは人間のレビューで担保する必要がある。生成物がGit管理できるプレーンファイルなのは、まさにこのレビューと修正を前提にした設計といえる。生成→確認→必要なら手で直す、というワークフローに乗せると安全だ。
まとめ——AIに任せた時代の「読むためのドキュメント」
oh-my-mermaidは、AIがコードを書く時代に欠けがちな「人間が読むためのアーキテクチャドキュメント」を、AI自身に生成させるという発想のツールだ。npm install -g oh-my-mermaid && omm setupの一行で導入し、/omm-scanで解析、omm viewで全体像を歩く——この流れの軽さが魅力だ。
押さえるべき要点を最後に整理する。
- oh-my-mermaid(omm)はコードベースをAIに解析させMermaid図つきドキュメントを生成するCLI+スキル(MIT・約1,367星・TypeScript)
- 図を「描く」のではなく「生成させる」。出力は.omm/にmd+mmdとして残りGit管理できる
- perspective(視点)×再帰分析で、ファイルツリーがそのままアーキテクチャの階層を反映する
- Claude Code / Codex / Cursor / OpenClaw / Antigravity に対応。クラウド共有も可能
- 解析品質はAIツール依存・生成物は要レビューという前提で、構造把握の出発点として使うのが現実的
AIに任せて量産したコードの「全体像が見えない」という悩みに、oh-my-mermaidは具体的な答えを出す。まずは手元のリポジトリで一度/omm-scanを走らせ、生成された.omm/を眺めてみるのがいちばん早い。導入コストはコマンド一行、生成物はGitに乗るプレーンファイル——試して合わなければ.omm/を消すだけだ。リスクの低さも、最初の一歩を踏み出しやすい理由になっている。
参照ソース
・oh-my-mermaid/oh-my-mermaid — GitHubリポジトリ(README / README.ja.md / package.json / docs/ROADMAP.md / skills/omm-scan/SKILL.md)
・oh-my-mermaid — npm パッケージページ
・ohmymermaid.com — 公式クラウド共有サービス



{kind=link}
{kind=link}