RAG(Retrieval-Augmented Generation)は、LLMの知識制限を外部の情報源と組み合わせることで突破する技術だ。「ChatGPTは2021年以降の情報を知らない」「社内ドキュメントを参照できない」という問題は、RAGによって解決される。2024年から2026年にかけてエンタープライズAI導入の標準パターンとなり、企業の知識管理・カスタマーサポート・コード支援など広範な用途で採用が進んでいる。
ただし、RAGは一種類ではない。最もシンプルなNaive RAGから、検索精度を高めるAdvanced RAG、コンポーネントを組み合わせるModular RAG、知識グラフを活用するGraph RAG、そして自律的に反復検索を行うAgentic RAGまで、用途や要件によって選ぶアーキテクチャが異なる。本記事では各パラダイムの仕組み・コード例・比較表を通じて、自分のユースケースに最適なRAGの構築方法を理解できるよう解説する。
- RAGはNaive→Advanced→Modular→Graph→Agenticの5世代に進化。「ベクトル検索+プロンプト挿入」で止まる時代は終わった
- Advanced RAGはHyDE・Multi-Query・Re-Rankingで検索精度を底上げ。ModularはRAGをLEGOブロックのように再構成可能にする
- Graph RAGは知識グラフで関係性を保持、Agentic RAGはLLM自身が検索戦略を判断する。用途別の使い分け表で選択できる
要点まとめ
- RAGはドキュメントをベクトル化してDBに保存し、質問と類似した情報を検索してLLMのプロンプトに付加する仕組みで、知識カットオフとhallucinationを大幅に緩和する
- Naive RAGは実装が容易だが「検索ミス」「チャンク断片化」「無関係な上位チャンク」の3つの問題を抱える
- Advanced RAGはクエリ拡張・HyDE・ハイブリッド検索・rerankingで検索精度を改善し、Naive RAGの主要課題を解決する
- Graph RAGはドキュメントからエンティティと関係性を抽出して知識グラフを構築し、複数ドキュメントにまたがる情報の統合に強い
- Agentic RAGはエージェントが検索→評価→再検索を自律的に繰り返す最も高度な形態で、複雑な多段階推論に対応するが、レイテンシとコストが高い
RAGとは:LLMの限界を外部検索で補う構築の基本
LLMは訓練データの範囲内でのみ回答できる。訓練後に公開された情報、企業内部のドキュメント、リアルタイムデータは原理的に知ることができない。また、訓練データに存在した情報でも、確率的なサンプリングによって事実と異なる回答を生成する「hallucination」が発生する。
RAGはこの問題を「検索してから生成する」アーキテクチャで解決する。ユーザーの質問に対して、まず外部の知識ベース(ドキュメント、DB、Web)から関連情報を取得し、その情報をプロンプトに付加した上でLLMに回答させる。Fine-tuningとは異なり、モデルの重みを変更しないため、知識の更新が容易でコストも低い。
RAGの基本パイプラインは2フェーズで構成される。
オフライン(インデキシング)フェーズ
- ドキュメントを読み込む(PDF、Markdown、HTML等)
- テキストをチャンク(断片)に分割する
- 各チャンクを埋め込みモデルでベクトル化する
- ベクトルをベクトルDBに保存する
オンライン(クエリ)フェーズ
- ユーザーの質問をベクトル化する
- ベクトルDBから類似チャンクを検索する(Top-k)
- 検索結果とユーザー質問をプロンプトに付加する
- LLMがプロンプトを受け取り回答を生成する
以下のアニメーションで5ステップの流れを確認できる。
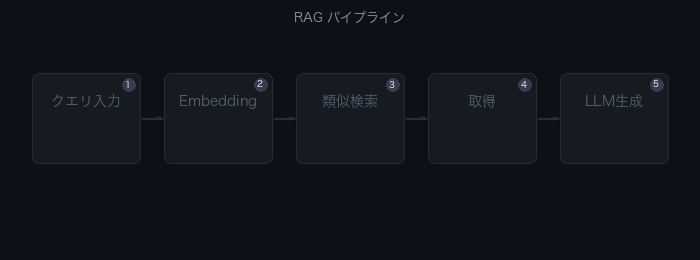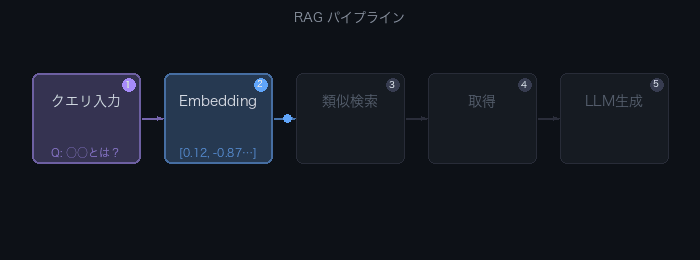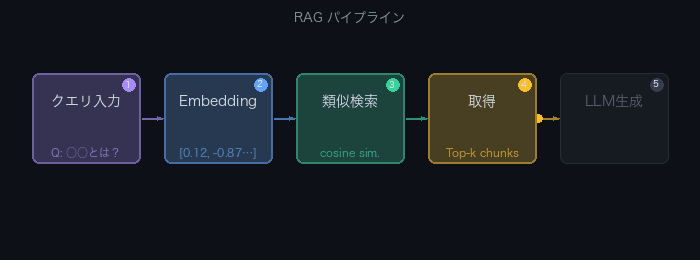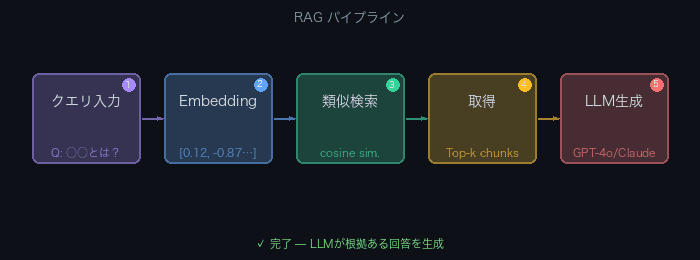
PDF/MD/HTML"] --> C["チャンク分割"] C --> E["埋め込みモデル
text-embedding-3-small等"] E --> V["ベクトルDB
Chroma/Qdrant等"] end subgraph online["オンラインフェーズ(クエリ)"] Q["ユーザーの質問"] --> EQ["埋め込みモデル"] EQ --> S["類似検索
コサイン類似度"] V --> S S --> R["Top-k チャンク取得"] R --> P["プロンプト構築
質問 + 取得コンテキスト"] P --> L["LLM
GPT-4o/Claude等"] L --> A["回答生成"] end
RAGが対応するLLMの課題を整理すると以下の通りだ。
| 課題 | Fine-tuning | RAG |
|---|---|---|
| 知識カットオフ(最新情報なし) | ✗(再訓練が必要) | ✓(DB更新のみ) |
| 社内ドキュメント参照 | △(大量データが必要) | ✓(インデキシングのみ) |
| Hallucination | △(多少改善) | ✓(ソース参照で抑制) |
| 出典の提示 | ✗ | ✓(チャンクURLを付与可能) |
| 更新コスト | 高(GPU必要) | 低(DBに追加するだけ) |
知識のアップデートや社内ドキュメント参照が目的ならRAGが適切。Fine-tuningはRAGで追加できない「文体・応答スタイル・専門的な推論パターン」を学習させたい場合に有効。多くのケースではRAGを先に試し、限界に達してからFine-tuningを検討するのが効率的だ。
Naive RAGで理解するRAGの基本構築ステップ
Naive RAGは最もシンプルなRAGの実装形態だ。LangChainとChromaDBを使った基本構成のコードを示す。
# Naive RAG: LangChain + ChromaDB の基本実装
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import DirectoryLoader
# 1. ドキュメントの読み込み
loader = DirectoryLoader("./docs", glob="**/*.md")
documents = loader.load()
# 2. チャンク分割(500文字、オーバーラップ50文字)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "、", " ", ""]
)
chunks = text_splitter.split_documents(documents)
# 3. ベクトルDB構築
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectordb = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 4. RAGチェーンの構築
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectordb.as_retriever(search_kwargs={"k": 5}),
return_source_documents=True
)
# 5. 質問応答
result = qa_chain.invoke({"query": "RAGの構築方法を教えてください"})
print(result["result"])
この実装は動作するが、Naive RAGには3つの根本的な問題がある。
問題1: 検索ミス(Low Recall) コサイン類似度に依存するため、質問と関連チャンクの表現が異なると検索に失敗する。例えば「価格」と「料金」、「LLM」と「大規模言語モデル」は意味的に同じだが、ベクトル空間での距離が大きい場合がある。
問題2: チャンクの断片化(Context Loss) ドキュメントを機械的にチャンク分割すると、関連する情報が異なるチャンクに分断される。「前のチャンクの続き」を参照する必要がある回答はNaive RAGでは生成できない。
問題3: 無関係チャンクのノイズ(Low Precision) Top-kで取得した複数のチャンクの中に、実際には無関係なチャンクが混入していると、LLMの回答精度が低下する。コンテキスト窓内のノイズは「Lost in the Middle」問題を悪化させる。
2024年時点でNaive RAGの実装をそのままプロダクション投入するケースが多いが、検索精度が低い状態ではユーザー体験が著しく低下する。「RAGを入れたのに回答が的外れ」という事象の大半は、Advanced RAGの技法を適用することで改善できる。
Advanced RAGとModular RAGが解決する検索精度問題
Advanced RAGはNaive RAGの3つの問題を、パイプラインの3段階(Pre-Retrieval・Retrieval・Post-Retrieval)で体系的に解決する。
Pre-Retrieval:クエリを最適化する
クエリ拡張(Query Expansion) ユーザーの質問を複数のバリエーションに展開してから検索を行う。「LLMの料金が知りたい」というクエリを「LLM 価格」「大規模言語モデル コスト」「GPT-4 API pricing」など複数に展開し、それぞれの検索結果を統合することでリコールを改善する。
HyDE(Hypothetical Document Embeddings) 質問に対して「仮の回答ドキュメント」をLLMに生成させ、その仮ドキュメントのベクトルで検索する手法。質問のベクトルより、回答に近い文体のベクトルで検索する方が精度が上がることが多い。
# HyDE(仮想ドキュメントでの検索)の実装例
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# HyDE: 仮の回答を生成してから検索
hyde_prompt = ChatPromptTemplate.from_template("""
以下の質問に対して、詳細なドキュメントの一節として回答してください。
実際の知識がなくても構いません。回答のスタイルと形式が重要です。
質問: {question}
仮の回答ドキュメント:
""")
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.3)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectordb = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
# HyDE チェーン
hyde_chain = (
hyde_prompt
| llm
| StrOutputParser()
| (lambda x: vectordb.similarity_search(x, k=5))
)
# 実行
hypothetical_docs = hyde_chain.invoke({"question": "RAGの構築に必要なコンポーネントは?"})
for doc in hypothetical_docs:
print(doc.page_content[:200])
Retrieval:ハイブリッド検索でリコールを改善する
ベクトル検索(セマンティック検索)とキーワード検索(BM25)を組み合わせるハイブリッド検索は、リコールを大幅に改善する。ベクトル検索は意味的類似性に強く、BM25は固有名詞や専門用語の完全一致に強い。
# ハイブリッド検索(BM25 + ベクトル検索)の実装例
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# BM25リトリーバー(キーワード検索)
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 5
# ベクトルリトリーバー(セマンティック検索)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectordb = Chroma.from_documents(chunks, embeddings)
vector_retriever = vectordb.as_retriever(search_kwargs={"k": 5})
# アンサンブルリトリーバー(BM25 60% + ベクトル 40%)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.6, 0.4]
)
# 検索実行
results = ensemble_retriever.invoke("RAGの仕組みを教えてください")
Post-Retrieval:Rerankingでノイズを除去する
取得したTop-kチャンクに対して、Cross-Encoderモデルを使ったReranking(再ランキング)を適用する。Cross-Encoderは質問とチャンクのペアを同時に評価するため、双方向の文脈を考慮したスコアリングができる。
Advanced RAGはNaive RAGと比較して、Recall(リコール)で平均20〜40%、Precision(精度)で15〜30%の改善が報告されている。(論文Survey of RAG、Gao et al. 2024による)
Modular RAGの考え方
Advanced RAGをさらに発展させたModular RAGは、検索・ルーティング・メモリ・フュージョンなどの機能を独立したモジュールとして設計する。各モジュールは独立して最適化・交換できるため、複雑なマルチソース検索や条件分岐を柔軟に構築できる。
| モジュール | 役割 | 例 |
|---|---|---|
| 検索モジュール | 複数ソースから取得 | ベクトルDB + 検索エンジン + SQL |
| ルーティングモジュール | クエリを適切な検索先に振り分け | 「最新情報→Web」「社内情報→DB」 |
| メモリモジュール | 過去の会話履歴を参照 | 複数ターンの対話 |
| フュージョンモジュール | 複数クエリの結果を統合 | RAG Fusion |
Graph RAGとAgentic RAGが開く次世代の知識検索
Graph RAG:ドキュメント間の関係性を活用する
従来のRAGはドキュメントを独立したチャンクとして扱う。しかし実際のビジネス知識は「エンティティ間の関係性」で構成されている。「プロジェクトAの担当者が過去に実施した全施策」を知るには、複数のドキュメントにまたがる関係性を辿る必要があるが、チャンクベースのRAGではこれを直接処理できない。
Graph RAGはドキュメントからエンティティ(人物・組織・概念)と関係性(動詞・述語)を抽出し、知識グラフを構築する。検索時にはグラフトラバーサルを行うため、複数ドキュメントにまたがる情報を統合して取得できる。
Microsoftが2024年に公開した研究では、Graph RAGはナレッジグラフ構築後、グローバル質問(全体を俯瞰する質問)においてNaive RAGを大幅に上回ることを示した。一方、ローカル質問(特定の事実を問う質問)ではNaive RAGと同程度かやや劣る場合もある。
# 概念的なGraph RAG: NetworkXを使ったシンプルな知識グラフ構築例
import networkx as nx
from langchain_openai import ChatOpenAI
import json
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def extract_entities_and_relations(text: str) -> list[dict]:
"""LLMでエンティティと関係性を抽出する"""
prompt = f"""以下のテキストからエンティティと関係性をJSONで抽出してください。
テキスト: {text}
出力形式:
entities
]
}}"""
response = llm.invoke(prompt)
return json.loads(response.content)
# 知識グラフ構築
G = nx.DiGraph()
# サンプルドキュメントから抽出
sample_text = "LangChainはLangChain社が開発したLLMフレームワークで、RAGパイプラインの構築に広く使われる。"
extracted = extract_entities_and_relations(sample_text)
for entity in extracted["entities"]:
G.add_node(entity)
for rel in extracted["relations"]:
G.add_edge(rel["subject"], rel["object"], relation=rel["predicate"])
# グラフ検索: "LangChain"に関連する全情報を取得
def graph_search(G, entity: str, depth: int = 2):
"""エンティティに関連するノードとエッジを深さdepthまで取得"""
subgraph_nodes = nx.single_source_shortest_path(G, entity, cutoff=depth)
return G.subgraph(subgraph_nodes)
subgraph = graph_search(G, "LangChain")
print(f"関連ノード数: {subgraph.number_of_nodes()}")
Graph RAGはLightRAGやMicrosoftのGraphRAGライブラリとして実装されている。詳しい実装についてはLightRAGの知識グラフRAGガイドを参照のこと。
• 法務・コンプライアンス文書: 条項間の参照関係をトラバーサルで解決
• 研究論文DB: 引用関係や著者間の共著ネットワークを活用
• 製品マニュアル: 部品間の依存関係や互換性情報の統合
• 組織ナレッジ: 人物・プロジェクト・スキルの関係図を検索
Agentic RAG:自律的に反復する検索エージェント
Agentic RAGは、RAGパイプライン全体をLLMエージェントが自律的に制御する最も高度な形態だ。エージェントは以下のループを繰り返す。
- ユーザーの質問を受け取る
- 検索クエリを設計して知識ベースを検索する
- 取得した情報で回答を試みる
- 回答が不十分なら、クエリを修正して再検索する
- 十分な情報が揃ったら回答を生成する
(LLM)"] A --> D{"回答に
十分な情報か?"} D -->|"No: 情報不足"| R["検索クエリを
設計・修正"] R --> S["知識ベース検索
(RAG / Web / SQL)"] S --> C["取得情報を
コンテキストに追加"] C --> A D -->|"Yes: 情報充足"| G["回答生成"] G --> U["ユーザーへの回答
(出典付き)"] style A fill:#1a1d27,stroke:#4a6fa5,color:#fff style D fill:#1a1d27,stroke:#f0a500,color:#fff style G fill:#1a1d27,stroke:#28a745,color:#fff
Agentic RAGはLangGraphやLlamaIndexのAgentフレームワークで実装できる。単純なRAGと比較して、複雑な多段階推論に有効だが、ループ回数に応じてAPIコストとレイテンシが増加する点に注意が必要だ。
エンタープライズRAGの構築にはRAGFlowのエンタープライズRAG機能も参考になる。RAGFlowはGraph RAGとAgentic RAGの要素を組み合わせた本番向けフレームワークだ。
RAGアーキテクチャの比較と用途別の選び方
5つのRAGパラダイムを多角的に比較する。
| アーキテクチャ | 実装難易度 | 検索精度 | コスト | 主な用途 |
|---|---|---|---|---|
| Naive RAG | ★☆☆☆☆ | △ | 低 | プロトタイプ・学習目的 |
| Advanced RAG | ★★★☆☆ | ○ | 中 | 本番環境の一般用途 |
| Modular RAG | ★★★★☆ | ○〜◎ | 中〜高 | マルチソース・複雑なルーティング |
| Graph RAG | ★★★★☆ | ◎(複数ドキュメント統合) | 高 | 法務・研究・組織ナレッジ |
| Agentic RAG | ★★★★★ | ◎(多段階推論) | 非常に高 | 複雑な推論・リサーチタスク |
ベクトルDBの選び方
RAG構築でもう一つの重要な選択がベクトルDBだ。ベクトルDBの選択はスケール・コスト・インフラ統合の3要素で決まる。
| ベクトルDB | 特徴 | 推奨ユースケース |
|---|---|---|
| Chroma | ローカル実行可、Python親和性高い | プロトタイプ・小規模 |
| Pgvector | PostgreSQL拡張、インフラ統合容易 | 既存PostgreSQL環境 |
| Qdrant | 高速・スケーラブル、フィルタリング強力 | 本番中〜大規模 |
| Weaviate | ハイブリッド検索内蔵、マルチモーダル対応 | マルチモーダルRAG |
| Pinecone | フルマネージド、高可用性 | エンタープライズ |
| Milvus | 大規模ベクトル検索、オープンソース | 大規模本番環境 |
ユースケース別の選択ガイド
→ Advanced RAG + Pgvector が最適解。HyDE とハイブリッド検索でリコールを確保し、reranking で精度を上げる。既存PostgreSQLがあればPgvectorで統合コストを最小化できる。
→ Graph RAG + LightRAG を検討。複数の条項・契約書間の参照関係をグラフトラバーサルで解決できる。インデキシングコストが高いため、ドキュメント規模に応じて判断する。
→ Agentic RAG + Web検索ツール統合 が適切。LangGraphでエージェントループを構築し、不十分な情報はWeb検索でリアルタイム補完する。コストとレイテンシの許容範囲を事前に設定すること。
「とりあえずGraph RAGを使えば精度が上がる」は誤りだ。Graph RAGはインデキシングに大量のLLM APIコールが必要で、コストと処理時間が大幅に増加する。単純な事実検索(「〇〇の価格は?」)ではNaive RAGやAdvanced RAGの方が高速・低コストで同等以上の精度を出せる。
RAGの評価指標
どのアーキテクチャを選んでも、定量的な評価なしに「精度が上がった」という判断はできない。RAGの評価には以下の指標を使う。
| 指標 | 意味 | 評価ツール |
|---|---|---|
| Context Recall | 正解情報が検索で取得できているか | RAGAs |
| Context Precision | 取得チャンクに不要な情報が少ないか | RAGAs |
| Faithfulness | 回答がコンテキストに忠実か(hallucination測定) | RAGAs |
| Answer Relevance | 回答がユーザーの質問に関連しているか | RAGAs |
| MRR / NDCG | 検索ランキングの精度 | BEIR Benchmark |
RAGのゼロから実装と評価方法についてはLangChain公式のRAG from Scratchが体系的なリファレンスになる。
まとめ
RAGは単一の技術ではなく、用途と要件に応じて選択するアーキテクチャパターンだ。
- プロトタイプ・PoC: Naive RAGで素早く動作確認
- 本番環境の一般用途: Advanced RAG(クエリ拡張 + ハイブリッド検索 + reranking)
- マルチソース・複雑ルーティング: Modular RAG
- エンティティ関係の複雑な知識: Graph RAG(LightRAG等)
- 多段階推論・リサーチタスク: Agentic RAG
RAGの「失敗の9割は検索の問題」と言われている。LLMの能力を過大評価して「とりあえずGPT-4に渡せば解決する」という発想では、検索精度の根本問題は解消されない。Advanced RAGの技法(クエリ拡張・ハイブリッド検索・reranking)を段階的に適用し、RAGAsで定量評価しながらイテレーションするアプローチが現場では最も効果的だ。
LangChainのエコシステムはNaive RAGからModular RAGまで一貫してサポートしており、学習コストを最小化しながらAdvanced RAGへの移行ができる。まずはLangChainでNaive RAGを構築し、評価指標で課題を特定してから段階的にAdvanced RAGの技法を追加するのが推奨パスだ。
参照ソース
- RAG Survey: A Comprehensive Survey of Retrieval-Augmented Generation for Large Language Models (arXiv 2024)
- Daily Dose of Data Science: RAG Paradigms — Naive, Advanced, Modular
- Microsoft GraphRAG 公式リポジトリ
- LangChain RAG From Scratch
- LightRAG: Simple and Fast Graph-based RAG (EMNLP 2025)
- RAGAs: Evaluation Framework for RAG Pipelines