E2E(エンドツーエンド)テストを書いたことがある人なら、この徒労を知っているはずです。せっかく書いたテストが、UIをちょっと変えただけで壊れる。ボタンのセレクタが変わった、要素の階層が動いた——それだけで真っ赤になり、原因を調べて直す作業に時間を溶かす。結果、E2Eテストは「壊れやすくて、書くのも直すのも重い」お荷物になり、放置されて形骸化していきます。この悪循環を断ち切るのが、「壊れたら自分で直る」E2Eテスト=自己改善ループという発想です。本記事は、NAVER Financialのエンジニアが公開した実践記事に着想を得つつ、誰でも再現できる形に、Playwrightの公式AIエージェント(Planner・Generator・Healer)を軸に手順として再構成した実践ガイドです。
この記事を読むと、①自己改善ループとは何か(E2Eテストを生成→実行→自動修復のループで回す仕組み)、②なぜ必要か(E2Eの「壊れやすい・重い・形骸化」を解決する)、③どう作るか(環境構築からCIでの自動修復まで、コマンド付きで再現)が分かります。AI時代の開発自動化ツール全体の地図を先に押さえたい方は、AI自動化ツール|ノーコードからコードまで2026年版の比較と選び方を合わせて読むと、このループがどの流れの中にあるのかが立体的に掴めます。

- ・自己改善ループ=E2Eテストを「生成→実行→失敗を分析して自動修復→再実行」で回す仕組み。
- ・中核はPlaywright v1.56+の公式エージェント。Planner(計画)・Generator(生成)・Healer(修復)の3役。
- ・導入は「npx playwright init-agents --loop=claude」など1コマンド。Claude Code/VS Code/OpenCode対応。
- ・Healerが失敗をデバッグ再現し、原因を分析してテストを自動修復。直らなければスキップ印。
- ・自動化しつつ、生成・修復は必ず人間がレビュー。CIで回して“生き続けるテスト資産”にする。
1. 自己改善ループとは:E2Eテストが「壊れたら自分で直る」仕組み
自己改善ループ(self-improvement / self-healing loop)とは、E2Eテストを「作って終わり」にせず、生成・実行・修復のサイクルとして回し続ける仕組みのことです。従来、テストの「生成」も「失敗の調査」も「修正」も、すべて人間の手作業でした。自己改善ループは、この各工程をAIエージェントに担わせ、閉じたループにします。
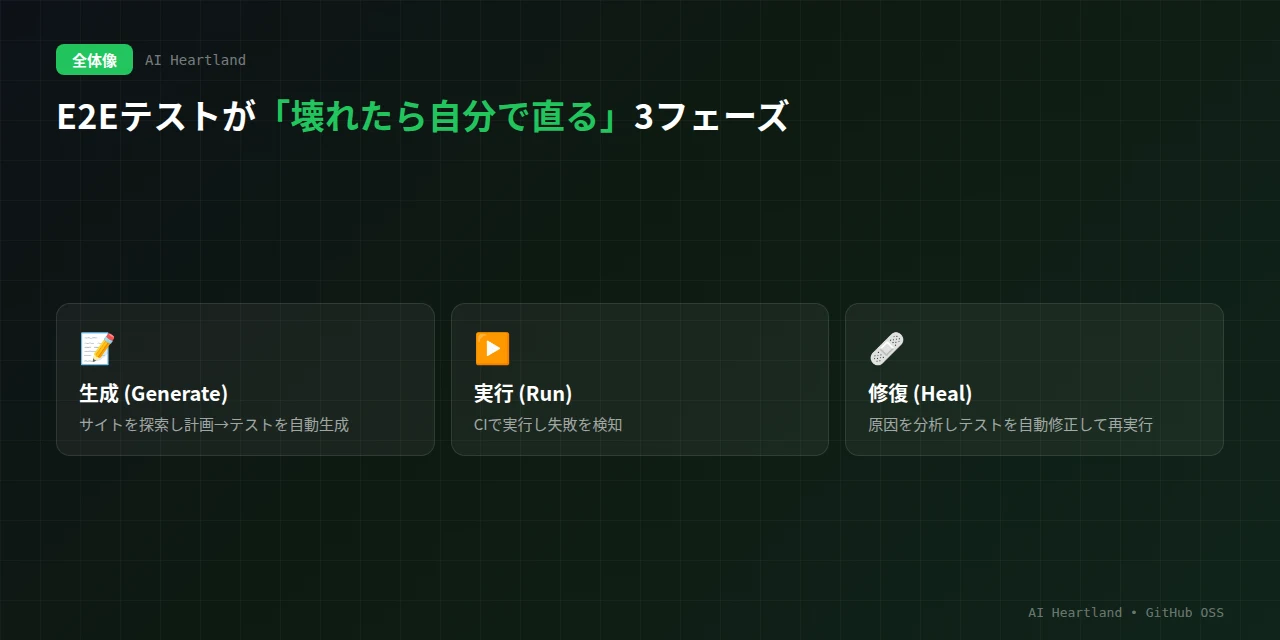
ループは、大きく3つのフェーズで構成されます。
・生成(Generate):アプリを探索して「何をテストすべきか」の計画を立て、そこからテストコードを自動生成する
・実行(Run):CIなどでテストを実行し、失敗を検知する
・修復(Heal):失敗の原因を分析し、テストを自動で修正して再実行する
ここで肝になるのが、3フェーズ目の修復(Heal)です。普通のテストは、失敗したらそこで止まり、人間の出番になります。自己改善ループでは、失敗をトリガーにAIが自動で直しにいく。UIが変わってセレクタが効かなくなっても、変更後の画面から意味的に近い要素を探し直して、テストを通るように修正する——この自己修復こそが「自己改善」の核心です。
- ・自己改善ループ=「生成→実行→自動修復」を回し続け、壊れても自分で直るE2Eテスト。
- ・従来との違いは、失敗を人が直すのではなく、AIエージェントが直す点。
なお、この「作る→評価する→直す」を反復して品質を上げるという発想は、テストに限らずAI開発全般で広がっているパターンです。実装面でこのループを支えるのがPlaywrightの公式エージェント機能で、その実行系としてClaude Codeなどを使います(詳しくは第4章)。土台となるClaude Codeの全体像はClaude Code完全ガイド2026で押さえておくと、後半の手順がスムーズです。
2. なぜ必要か:E2Eの「壊れやすい・重い・形骸化」を解決する

自己改善ループが解決するのは、E2Eテストが構造的に抱える「維持できない」問題です。E2Eは「ユーザーの実際の操作を丸ごと検証できる」強力なテストですが、その強さの裏返しとして、次の弱点があります。
・壊れやすい(flaky):UIの些細な変更で落ちる。セレクタ・待機・タイミングに敏感
・書くのが重い:シナリオを1本ずつ手で書くのは手間がかかる
・直すのが重い:失敗のたびに人が原因を調査し、修正する必要がある
・形骸化しやすい:維持コストに耐えかね、いつしか誰もメンテしなくなる
自己改善ループは、これらを「各工程をAIエージェントに肩代わりさせる」ことで解決します。従来の課題と、ループによる解決を対応させると、次のようになります。
| 従来のE2Eの課題 | 自己改善ループでの解決 |
|---|---|
| UI変更ですぐ壊れる(flaky) | Healerが変更に追従してテストを修復 |
| シナリオを1本ずつ手書き | Planner+Generatorで計画から自動生成 |
| 失敗のたびに人が調査・修正 | 失敗をAIが分析し、自動で修正 |
| 維持コストで形骸化 | CIで回り続け、テストが“生き続ける” |
- ・「テストを一切見なくてよくなる」わけではない。AIの生成・修復は必ずレビューする前提。
- ・Healerは「テストを通す」のが目的。仕様として正しいかの判断は人間が持つ。
この必要性が効いてくるのは、UIの変化が速く、E2Eが壊れやすいプロダクトほどです。UIがほぼ固定なら維持コストは小さく、ループの恩恵も限定的です。しかし、頻繁に画面が変わる現場では、「壊れる→直す」の繰り返しがテストを殺していきます。自己改善ループは、その「直す」を自動化して、テストを延命させる——維持コストの高さこそが、このループの価値の源泉です。
3. 全体像:Planner→Generator→Healerの3エージェントで回す
Playwrightは、v1.56からこの自己改善ループを支える3つの公式AIエージェントを導入しました。それぞれが、ループの1フェーズを担当します。
| エージェント | 役割 | やること |
|---|---|---|
| Planner | 計画 | サイトを探索し、機能を分析して、テスト計画をMarkdownで作成する |
| Generator | 生成 | 計画からテストファイル(specコード)を生成する |
| Healer | 修復 | テストをデバッグ実行し、失敗の原因を分析して、通るまで修正する |
この3エージェントがループを形成します。全体像を図にすると次のようになります。
探索→テスト計画(Markdown)"] P --> Review1{"人がレビュー"} Review1 --> G["Generator
計画→テストコード生成"] G --> Run["CIで実行"] Run --> Q{"結果は?"} Q -->|"合格 ✅"| Keep["テスト資産として維持"] Q -->|"失敗 ❌"| H["Healer
デバッグ再現→原因分析→修正"] H --> Q2{"直った?"} Q2 -->|"はい"| Review2{"修正をレビュー"} Review2 --> Run Q2 -->|"いいえ(機能が壊れている)"| Skip["skip印を付け人間に委ねる"] Keep -.->|"UIが変わったら"| Run
この図で押さえるべきは、2箇所の「人がレビュー」ゲートです。Plannerの計画とHealerの修正には、人間の確認を挟みます。ループは自動で回りますが、「AIが叩き台を作り、人間が要所で承認する」という分業にすることで、AIの誤りをそのまま本番に流さずに済みます。完全自動と完全手動の中間、いわば「監督付きの自動化」が、実務では最も現実的で安全です。エージェントの実行を支える仕組みとしては、AIとブラウザを繋ぐMCPサーバー構築ガイドの考え方(後述のPlaywright MCP)も関わってきます。
4. 実践①:環境構築(Playwright 1.56+ / init-agents / seed)

ここから実践です。まず前提として、Playwright v1.56以上が必要です。エージェント機能はこのバージョンから入りました。
# Playwrightを最新化(v1.56以上)
npm install -D @playwright/test@latest
npx playwright install
次に、エージェント定義を生成します。init-agentsコマンドで、使いたいAIツール(実行ループ)を指定します。Claude Codeを使うなら --loop=claude、VS Code(GitHub Copilot)なら --loop=vscode、OpenCodeなら --loop=opencode です。
# Claude Code を使う場合
npx playwright init-agents --loop=claude
# VS Code (GitHub Copilot) を使う場合
# npx playwright init-agents --loop=vscode
# OpenCode を使う場合
# npx playwright init-agents --loop=opencode
これを実行すると、3つのエージェント定義ファイル(planner・generator・healer)が生成されます。--loop=claudeならば .claude/agents/ 配下に、それぞれの指示とツール定義を記したMarkdownファイルが置かれます。あわせてシード(seed)ファイルが用意されます。
シードファイル(seed.spec.ts)は、生成されるテストの「ひな型」です。ログイン状態やベースURL、共通のフィクスチャなど、全テストに共通する前提をここに書いておくと、Generatorが生成する各テストにその前提が引き継がれます。たとえば次のようなイメージです。
// seed.spec.ts(生成テストの共通前提の例)
import { test, expect } from '@playwright/test';
test.beforeEach(async ({ page }) => {
// 共通の前提:ベースURLへ移動し、ログイン済み状態にする等
await page.goto('/');
});
// このファイルの作法・前提が、生成される各テストに引き継がれる
環境構築の流れをまとめると、こうなります。
・Playwright v1.56以上を導入する(npm install -D @playwright/test@latest)
・npx playwright init-agents --loop=claude でエージェントとseedを生成する
・seed.spec.ts に共通前提(ベースURL・ログイン等)を書く
・必要に応じてPlaywright MCPを接続し、ブラウザ操作をAIに開放する
- ・Playwright MCPは、AIエージェントにブラウザ操作(クリック・入力・スナップショット取得等)を開放するMCPサーバー。
- ・Plannerのサイト探索や、Healerのデバッグ再現が、実ブラウザ越しに自然言語で回しやすくなる。
「Playwrightを最新化 → init-agents → seedを整える」——ここまでで、ループを回す土台が完成します。
5. 実践②:Planner→Generatorでテストを自動生成する
土台ができたら、テストを生成します。ここはPlanner→Generatorの2段です。
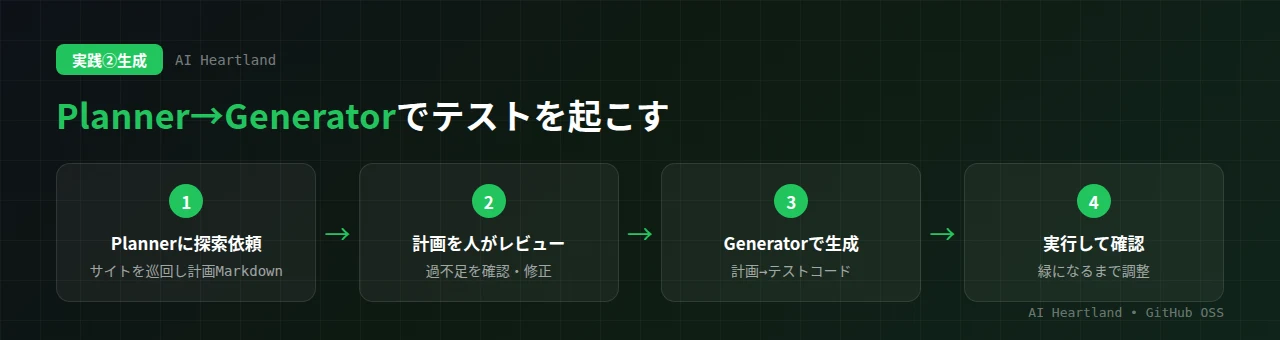
ステップ1:Plannerに探索・計画を依頼する。使っているAIツール(Claude Code等)でPlannerエージェントを起動し、対象のアプリやページを伝えて「テスト計画を作って」と依頼します。Plannerはサイトを探索し、機能を洗い出し、テスト計画をMarkdownで出力します。この計画には「どの画面で・何を・どう検証するか」が構造化されて並びます。
ステップ2:計画を人がレビューする。ここが品質の分かれ目です。Plannerの計画に、テストすべきなのに漏れているケースは無いか、逆に不要なケースが混ざっていないかを確認し、必要なら手で調整します。計画の段階で人が目を通すことで、後段の生成テストの精度が大きく上がります。
ステップ3:Generatorでテストを生成する。承認した計画をGeneratorエージェントに渡すと、計画の各項目を実際のテストコード(specファイル)に変換します。このとき、前章で用意したseedの作法・前提が各テストに引き継がれます。
ステップ4:実行して確認する。生成されたテストを実行し、緑(合格)になることを確認します。
# 生成されたテストを実行して確認
npx playwright test
# 特定のテストだけ実行する場合
npx playwright test tests/generated/login.spec.ts
もし最初から失敗する場合は、後述のHealerに直させることもできますが、生成直後の段階では、Plannerの計画かseedの前提を見直すのが早いことも多いです。生成の流れをまとめると、こうなります。
・Plannerにアプリを探索させ、テスト計画(Markdown)を得る
・計画を人がレビューし、過不足を調整する
・Generatorに計画を渡し、テストコードを生成する
・npx playwright test で実行し、緑になることを確認する
これで、手書きせずにテストの初版が揃う状態になります。ゼロからシナリオを起こす重さが消え、人間は「計画のレビュー」という一段上の作業に集中できます。
6. 実践③:HealerでCIの失敗を自動修復する(自己改善の核心)
ここが自己改善ループの心臓部、Healerによる自動修復です。テストは、UIの変更などでいつか必ず壊れます。その「壊れた」を人手ゼロ(または最小限)で直すのがHealerの役割です。
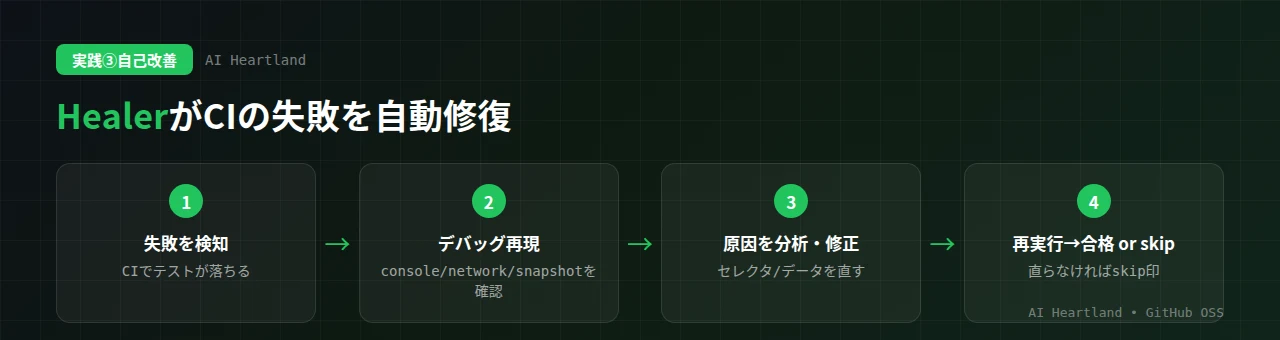
Healerの動きはこうです。まず、失敗したテストをデバッグモードで実行します。そして、コンソールログ・ネットワークリクエスト・ページのスナップショットを確認して、なぜ失敗したのかを分析します。原因が特定できたら、テストが通るまで修正を試みます。典型的なのがセレクタの修復で、UI変更で #login-btn が効かなくなったとき、変更後の画面から意味的に最も近い要素を見つけ直して差し替える、といった修正を行います。そして、どうしても直らない場合——たとえば機能そのものが壊れている場合——は、無理に緑にせずテストにskip印を付けて人間に委ねます。
この「壊れているのに緑にしない」判断が重要です。もしHealerが何でも通してしまうと、バグを見逃すテストが量産されてしまいます。Healerが「これは自分では直せない(機能が壊れている)」と判断してskipすることで、テストの信頼性が保たれます。
実運用では、これをCIに組み込みます。GitHub Actionsなら、テスト実行のワークフローに、失敗時にHealerを走らせる段を足すイメージです。
# .github/workflows/e2e.yml(概念例)
name: E2E with self-healing
on: [pull_request]
jobs:
e2e:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20 }
- run: npm ci
- run: npx playwright install --with-deps
# 1) まず通常実行
- run: npx playwright test
# 2) 失敗したら Healer を起動して修復を試みる(実行系はClaude Code等)
# 修復結果はPRの差分として人間がレビューする
- ・Healerの修正は「自動でmainに反映」しない。必ずPRの差分として人間がレビューする。
- ・skipされたテストを放置しない。skip=「機能が壊れている疑い」の通知として扱う。
CIでの自己改善の流れをまとめると、こうなります。
・PRごとにCIでE2Eを実行する
・失敗したテストをHealerがデバッグ再現し、原因を分析する
・セレクタ・待機・データ等を修正し、再実行する
・直れば修正差分をPRに出し、人がレビューしてマージ
・直らなければskip印を付け、機能側の不具合として人間に通知
「失敗を、人の割り込みでなく、AIの修復タスクに変える」——これが自己改善ループがE2Eの維持コストを劇的に下げる理由です。UIが変わるたびに真っ赤になっていたテストが、CIの中で静かに直り続けるようになります。
7. 運用のコツと注意点:過信しない・レビューを残す・コストを見る

最後に、実務で失敗しないための運用のコツと注意点を整理します。
このループが効く現場
・UIの変更が速いプロダクト(壊れやすいE2Eの維持に困っている)
・回帰テストを継続的に回したいチーム
・テストの維持コストが高くて形骸化しがちな現場
・Claude Code等のAIコーディング環境をすでに使っているチーム
慎重に判断すべきケース
・UIがほぼ固定の小規模サイト(導入オーバーヘッドが上回る)
・トークンコストをシビアに抑えたい(生成・修復のたびに消費する)
・テストの完全な手動管理を貫きたい方針
そのうえで、運用のベストプラクティスを挙げます。①自動修正は必ずレビューする。Healerの目的は「テストを通すこと」であり、その修正が仕様として正しい保証はありません。修正はPRの差分として人間が承認するフローにします。②skipを放置しない。skipは「機能が壊れているかも」という重要なシグナルです。skip一覧を定期的に棚卸ししましょう。③計画(Planner)の段階でレビューする。上流で品質を担保するほど、下流の生成・修復が安定します。④コストを監視する。エージェントの実行回数とトークン消費を可視化し、暴走しない歯止めを設けます。
- ・生成・修復は「叩き台」。最終判断は人間が持つ(要所にレビューゲートを残す)。
- ・skipされたテスト=機能不具合の疑い。通知として扱い、放置しない。
- ・トークンコストを監視し、CIでの実行回数に上限を設ける。
このループは、AIに「テストを丸投げ」するものではありません。AIに単調な作業(生成・調査・修正)を任せ、人間は判断(計画のレビュー・修正の承認)に集中する——という役割分担の設計です。この「監督付きの自動化」を守る限り、自己改善ループはE2Eテストを“お荷物”から“生き続ける資産”へと変えてくれます。より広い自動化ツールの中での位置づけは、AI自動化ツール2026年版の比較と選び方を、ループを動かすAIコーディング環境はClaude Code完全ガイド2026を合わせて参照してください。
まとめ
Playwright E2Eの自己改善ループは、「壊れたら自分で直るテスト」という発想を、公式のAIエージェント(Planner・Generator・Healer)で現実にする仕組みです。テストの生成から、失敗の自動修復までを閉じたループにすることで、E2Eの「壊れやすい・書くのが重い・すぐ形骸化」という三重苦を解きほぐし、CIの中でテストを生かし続けます。
- ・自己改善ループ=E2Eを「生成→実行→自動修復」で回し、壊れても直り続ける仕組み。
- ・Playwright v1.56+の3エージェント(Planner/Generator/Healer)が各フェーズを担う。
- ・導入は `npx playwright init-agents --loop=claude` など1コマンドから。seedで前提を共有。
- ・Healerが失敗をデバッグ再現・分析して自動修復。直らなければskipで人間に委ねる。
- ・生成・修復は必ずレビュー。skipを放置せず、コストを監視する「監督付き自動化」で運用する。
「E2Eは書いても維持できない」という諦めは、自己改善ループで過去のものになりつつあります。まずはPlaywrightを最新化し、init-agentsで3エージェントを呼び出して、小さなページ1つからループを回してみてください。着想元であるNAVER Financialの実践記事や、公式のPlaywright Test Agentsも合わせて読むと、理解がさらに深まります。
参照ソース
・Playwright E2Eテストで自己改善ループを構築する(NAVER Financial / Medium) — 本記事の着想元。NAVER FinancialのエンジニアによるPlaywright自己改善ループの実践記事。
・Playwright Test Agents(公式ドキュメント) — Planner・Generator・Healerの公式仕様とinit-agentsコマンドの一次ソース。
・Playwright MCP(GitHub) — AIにブラウザ操作を開放するMCPサーバーの一次ソース。