AIコーディングのために書いたCLAUDE.mdは、コードをリファクタした瞬間に古くなる。 存在しないパスをエージェントが参照し、追加した依存に気づかず、昨日のアーキテクチャを前提に助言を返す。 ai-setup(製品名はCaliber)は、この設定ファイルの陳腐化をコード変更への追従で抑えにいくOSSだ。
Claude Code全般の運用は Claude Code|2026年版・インストールからCLAUDE.md・Hooks・本番運用までの実装手引き にまとめてある。 本記事はそのうち、設定ファイルの生成と同期を専門に担うCaliberを、公式リポジトリの情報だけで整理する。
30秒で理解する ai-setup(Caliber)
30秒で理解するCaliber
・何? CLAUDE.md・Cursorルール・AGENTS.md・Copilot指示書を、コードの変化に合わせて生成・同期するCLI
・作者 caliber-ai-org(リポジトリ名は ai-setup、npmパッケージ名は @rely-ai/caliber)
・規模 スター1,138・Fork111・MIT・TypeScript製(2026-06-18時点、GitHub API実測)
・対応ツール Claude Code / Cursor / Codex / OpenCode / GitHub Copilot の5種
・入口 npx @rely-ai/caliber bootstrap の1コマンド。続けてエージェント内で /setup-caliber を実行
・安全設計 上書き前にバックアップ、差分レビュー、caliber undo で全戻し、スコア低下時は自動revert
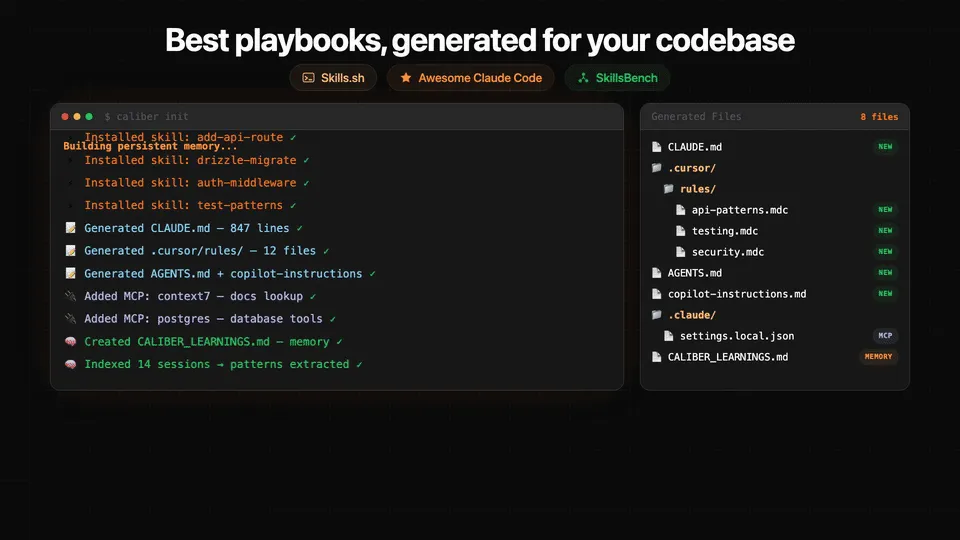
ai-setup(Caliber)とは — caliber-ai-org製のMITライセンスOSS
Caliberは、AIエージェント用の文脈ファイルを生成・保守するためのCLIツールだ。
GitHub上のリポジトリ名は caliber-ai-org/ai-setup、配布されるnpmパッケージ名は @rely-ai/caliber、コマンド名は caliber という対応になっている。
名前が3つに分かれているのは初見で戸惑うところなので、最初に押さえておきたい。
READMEは問題提起から始まる。
手書きの CLAUDE.md はコードを書き換えた瞬間に実態とずれ、エージェントが古い前提で動くという指摘だ。
Caliberはこの文脈ファイルを生成し、コードの進化に合わせて更新し続けることで、Claude Code・Cursor・Codex・OpenCode・GitHub Copilotを使うチーム全員のAIを同じ理解に保つことを狙う。
公開情報を実測した主な数値は次のとおりだ。
リポジトリの実測値(2026-06-18 GitHub API)
・スター 1,138/Fork 111/未解決Issue 22
・ライセンス MIT、主要言語 TypeScript
・作成 2026-03-10、最新リリース v1.49.6(2026-05-06)、最終push 2026-05-20
・デフォルトブランチ master、公式サイト caliber-ai.dev
・主なコントリビュータ apeslin・alonp98・Shweta-Mishra-ai ほか17名
設計思想の近い先行プロジェクトとしては、Claude Code向けの初期化システムである Claude Bootstrap:AIエージェントチーム・TDD・コードグラフを標準装備したClaude Code初期化システム がある。 あちらがエージェントチームやTDDまで含めた「開発基盤の一括構築」なのに対し、Caliberは設定ファイルの生成と継続同期に範囲を絞っている。 似て見える両者だが、解こうとしている問題の層が違う。
Caliberが自動化するもの — CLAUDE.md陳腐化への対処
Caliberが生成するのは、各AIツールが読む文脈ファイルそのものだ。 プラットフォームごとに出力先と形式が決まっている。
Claude Code向けには CLAUDE.md(プロジェクト文脈・ビルド/テストコマンド・アーキテクチャ・規約)に加え、AIセッションから学んだパターンを蓄える CALIBER_LEARNINGS.md、.claude/skills/*/SKILL.md(OpenSkills形式)、自動検出したMCPサーバ設定の .mcp.json、権限とフックの .claude/settings.json を作る。
Cursor向けにはフロントマター付きの .cursor/rules/*.mdc と .cursor/skills/*/SKILL.md、.cursor/mcp.json。
OpenAI Codexには AGENTS.md と .agents/skills/*/SKILL.md、OpenCodeには AGENTS.md と .opencode/skills/*/SKILL.md、GitHub Copilotには .github/copilot-instructions.md を出力する。
ここで効いてくるのが「managed block injection」という挙動だ。 CHANGELOG(v1.49.2)によれば、Caliberは自分が管理する区画をマーカーで囲んで注入し、利用者が手書きした区画とは混ぜない。 再生成のたびに同じ内容が重複追記されないよう、印のないインライン区画を検出してスキップする仕組みも入っている。 CLAUDE.mdのベストプラクティス集を体系的に知りたい場合は awesome-claude-md 入門|CLAUDE.mdベストプラクティス集の歩き方と取り込み手順 が参考になる。
スキルもCaliberの生成対象だ。
リポジトリの skills/ には setup-caliber・find-skills・save-learning・scoring-checks・llm-provider・writers-pattern といった内蔵スキルが並ぶ。
生成される各プラットフォーム向けスキルは、Anthropicが定めたSKILL.md形式(OpenSkills)に沿う。
コミュニティのスキルを探して取り込む caliber skills コマンドも用意され、設定ファイルだけでなく再利用可能な手順書まで含めて環境を整える発想になっている。
プロジェクトのデータベースやAPIといった依存を検出し、対応するMCPサーバ設定を自動で組む点も、手書きでは抜けやすい部分を補う。
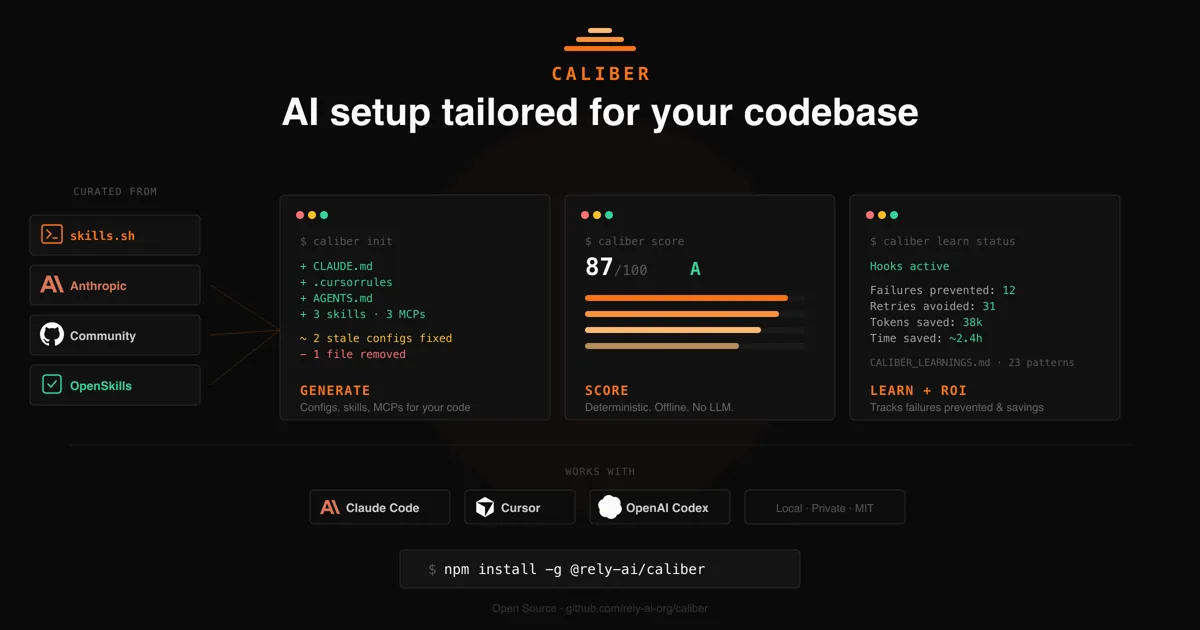
生成・同期される構成ファイルの全体像
プラットフォームと出力ファイルの対応を表にまとめる。 1つのプロジェクトに複数のエージェントが混在しても、同じ情報源から各形式へ展開されるのがCaliberの基本姿勢だ。
| プラットフォーム | 主な生成・管理ファイル | 役割 |
|---|---|---|
| Claude Code | CLAUDE.md / CALIBER_LEARNINGS.md / .claude/skills/*/SKILL.md / .mcp.json / .claude/settings.json | 文脈・学習・スキル・MCP・権限 |
| Cursor | .cursor/rules/*.mdc / .cursor/skills/*/SKILL.md / .cursor/mcp.json | ルール・スキル・MCP |
| OpenAI Codex | AGENTS.md / .agents/skills/*/SKILL.md | 文脈・スキル |
| OpenCode | AGENTS.md / .opencode/skills/*/SKILL.md | 文脈・スキル(Codexと共有可) |
| GitHub Copilot | .github/copilot-instructions.md | 文脈 |
依存関係を図にすると、1つのコードベース解析結果から各プラットフォーム向けの設定が枝分かれする構造になる。
言語・依存・構成・既存設定"] C --> CL["Claude Code
CLAUDE.md / skills
.mcp.json / settings.json"] C --> CU["Cursor
.cursor/rules/*.mdc
.cursor/mcp.json"] C --> CX["Codex / OpenCode
AGENTS.md / skills"] C --> CP["GitHub Copilot
copilot-instructions.md"] C --> LN["CALIBER_LEARNINGS.md
セッションから学んだパターン"]
言語やフレームワークの判定はLLM任せで、ハードコードされたマッピングを持たないとREADMEは説明している。 TypeScript・Python・Go・Rust・Java・Ruby・Terraformなどを例示しており、特定言語に縛られない設計を意図している。
スコアリングの仕組み — LLMを使わない決定論的評価
Caliberの特徴は、設定ファイルの品質を caliber score で数値化する点にある。
この採点はLLMを呼ばない。
設定ファイルを実際のプロジェクトのファイルシステムと突き合わせ、参照先パスが存在するか、コードブロックがあるか、git履歴に対して設定が古くないか、を機械的に判定する。
同じ入力なら同じ点が出る決定論的な評価という位置づけだ。
配点は6カテゴリ100点満点で定義されている。
| カテゴリ | 配点 | チェック内容 |
|---|---|---|
| Files & Setup | 25 | 設定ファイルの有無、skills、MCPサーバ、クロスプラットフォーム整合 |
| Quality | 25 | コードブロック、トークン量の節約、具体的な指示、見出し構造 |
| Grounding | 20 | 設定が実在のディレクトリ・ファイルを参照しているか |
| Accuracy | 15 | 参照パスがディスク上に存在するか、git履歴に対する鮮度 |
| Freshness & Safety | 10 | 最近更新されたか、秘密情報の漏れがないか、権限設定 |
| Bonus | 5 | 自動refreshフック、AGENTS.md、OpenSkills形式 |
READMEのBefore/After例では、手書きのCLAUDE.mdだけがある状態の35点が、/setup-caliber 実行後に94点(グレードA)へ上がる様子が示される。
失敗した各チェックには構造化された修正データが付き、caliber init のときにLLMへ「何がどう間違っているか」がそのまま渡される。
既存設定が95点以上なら全面再生成を省き、落ちているチェックだけを狙って直す。
ブランチ単位の差分は caliber score --compare main で確認できる。
caliber score # 現在の設定を採点(LLM不使用・ローカル完結)
caliber score --compare main # mainブランチに対する増減を表示
caliber score --json --quiet # CIで使える機械可読出力

導入手順 — bootstrap と /setup-caliber
前提はNode.js 20以上だ。
最短経路はbootstrapで、npx @rely-ai/caliber bootstrap を1回叩く。
これはエージェントに /setup-caliber スキルを渡すだけの処理で、100%ローカル、LLM呼び出しもコード送信もない。
# 1) スキルを導入(2秒・ローカル完結)
npx @rely-ai/caliber bootstrap
次に、IDEのチャット欄ではなくターミナルでClaude CodeかCursorのCLIセッションを開き、スラッシュコマンドを実行する。
/setup-caliber
このコマンドが、スタック検出・各プラットフォーム向け設定の生成・pre-commitフックの設定・継続同期の有効化までを、普段の作業フローの中で進める。
Claude CodeもCursorも使っていない場合は、CLIウィザードの caliber init が同じ役割を果たす。
こちらはAnthropic・OpenAI・Vertex AIのいずれかのキーを持ち込んで動かせる。
同梱の skills/setup-caliber/SKILL.md には、毎回の起動時に走る診断手順が定義されている。
caliberが入っているか、pre-commitフックが有効か、各エージェントの設定が存在するか、スコアが鮮度を保てているかを順に確かめ、足りないものだけを補う流れだ。
書き込みの順序にも思想がある。 READMEは「Audits first, writes second」とうたい、コードレビューに似た5段階を踏む。 まず読み取り専用の採点(Score)、次に生成や改善の提案(Propose)、変更ごとの受け入れ・修正・却下(Review)、書き込み前のバックアップ(Backup)、そして全戻しの取り消し(Undo)だ。
主なコマンドを一覧にまとめる。
| コマンド | 役割 |
|---|---|
caliber bootstrap | エージェントスキルを導入する最短の入口 |
caliber init | 解析・生成・レビュー・フック導入まで通すウィザード |
caliber score | 設定品質を採点(決定論的・LLM不使用) |
caliber regenerate | 再解析して設定を作り直す(別名 regen / re) |
caliber refresh | 最近のコード変更に基づき設定を更新 |
caliber skills | コミュニティのスキルを探索・導入 |
caliber learn | セッション学習のフック導入・状態確認・解析 |
caliber hooks | 自動refreshフックの管理 |
caliber config | LLMプロバイダ・APIキー・モデルの設定 |
caliber status | 現在のセットアップ状態を表示 |
caliber uninstall | Caliberが追加した資源を削除 |
caliber undo | Caliberによる変更をすべて取り消し |
全体像を図にすると、一度の導入のあとはコミットごとの同期ループに入る。
一度きり・約2秒"] --> B["agent が /setup-caliber を実行"] B --> C["設定ファイル生成"] C --> D["コードが進化
依存追加・改名・構成変更"] D --> E["caliber refresh
コミット時に自動実行"] E --> C
ローカル動作を強調する一文がREADMEにある。 「Your code stays on your machine.」で、bootstrapは完全ローカル、生成は利用者自身のAIサブスクかAPIキーを使い、Caliber自体はコードを見ないという主張だ。
自動同期と継続運用 — フック・GitHub Action・セッション学習
Caliberの価値は一度生成して終わりではなく、コミットのたびに設定を追従させる継続運用にある。 同期は3種類のフックで成り立つ。
| フック | 発火タイミング | 動作 |
|---|---|---|
| Git pre-commit | 各コミット前 | ドキュメントをrefreshし、更新分をステージング |
| Claude Code session end | セッション終了時 | caliber refresh を実行して設定を更新 |
| Learning hooks | セッション中 | ツール使用・失敗・修正イベントを記録 |
caliber refresh は、コミット済み・ステージ済み・未ステージのgit差分を解析し、変わった内容を設定ファイルへ反映する。
フックの導入と解除は caliber hooks --install / caliber hooks --remove で行う。
CHANGELOG(v1.49.0)では、pre-commitフックの区画がバージョン管理され(# caliber:pre-commit:v2:start)、古いフックを入れ直すとクリーンに更新されると説明されている。
gitleaksやhuskyなどcaliber以外のフック内容は保持される設計だ。
セッション学習は caliber learn 系のサブコマンドで扱う。
フックがツール使用・失敗・利用者の修正を捕捉し、LLMが運用パターンを CALIBER_LEARNINGS.md に蒸留する。
学習項目は [correction]・[gotcha]・[fix]・[pattern]・[env]・[convention] に分類され、自動で重複排除される。
caliber learn install # Claude Code / Cursor 用フックを導入
caliber learn status # フック状態・イベント数・ROI要約を表示
caliber learn finalize # 解析を手動実行(セッション終了時に自動でも走る)
caliber learn remove # フックを削除
CI向けには公式GitHub Action(action.yml)が用意されている。
PRに対してスコアをコメントし、しきい値未満で失敗させ、設定が古ければrefreshして同期PRを作る sync モードを持つ。
# .github/workflows/caliber.yml の例
- uses: caliber-ai-org/ai-setup@v1
with:
agent: claude # claude / cursor / codex
fail-below: '80' # 80点未満でCIを失敗させる
comment: 'true' # PRにスコアをコメント
mode: 'score' # score(採点)または sync(同期PR作成)
出力は score(0-100)・grade(A-F)・delta(基準ブランチからの増減)・sync-pr(同期PRのURL)が定義されている。
設定ファイルをコードと同じくレビュー対象に載せる発想で、この継続同期の考え方は ループエンジニアリングとは|AIエージェントの反復制御を設計する5つの軸と主要OSS実装 で扱う反復制御の一形態とも読める。
自動で動く仕組みだからこそ、取り消し可能性が担保されている。
書き込みのたびに元ファイルが .caliber/backups/ へ退避され、caliber undo で直前の状態へ戻せる。
再生成がスコアを下げた場合は変更が自動でrevertされる「スコア退行ガード」が働き、--dry-run を付ければ適用前に差分だけを確認できる。
やめるときは caliber uninstall がフック・生成区画・スキル・学習を取り除き、利用者自身が書いた内容は保持する。
入れて試し、合わなければきれいに抜けられる作りが、既存リポジトリへ持ち込む際の心理的なハードルを下げている。
LLMプロバイダ設定とカスタマイズ
生成処理に使うLLMは、既存のAIツールのサブスクをそのまま流用できる。 APIキーを持たなくても、Claude CodeやCursorのシートで動かせるのが導入の敷居を下げている。
| プロバイダ | 設定方法 | 既定モデル |
|---|---|---|
| Claude Code(シート) | caliber config → Claude Code | Claude Codeから継承 |
| Cursor(シート) | caliber config → Cursor | Cursorから継承 |
| Anthropic | export ANTHROPIC_API_KEY=sk-ant-... | claude-sonnet-4-6 |
| OpenAI | export OPENAI_API_KEY=sk-... | gpt-5.4-mini |
| Vertex AI | export VERTEX_PROJECT_ID=my-project | claude-sonnet-4-6 |
| カスタムエンドポイント | OPENAI_API_KEY + OPENAI_BASE_URL | gpt-5.4-mini |
モデル選択には2階層のモデルシステムが使われる。
分類やスコアリングのような軽い処理は自動で高速モデルへ振り、生成や修正のような重い処理は既定モデルを使う。
任意のプロバイダで export CALIBER_MODEL=<model> や caliber config からモデルを上書きできる。
設定は ~/.caliber/config.json に権限 0600 で保存され、APIキーがプロジェクトファイルに書き込まれることはないと公称されている。
プロバイダ解決の優先順位はFLOW.mdに記載があり、環境変数(ANTHROPIC_API_KEY → VERTEX_PROJECT_ID → OPENAI_API_KEY → Cursorシート → Claude CLIの順)が先に評価され、なければ設定ファイルが使われる。
匿名の利用解析(コマンド名と実行時間。コードやファイル内容は含まない)はPostHog経由で収集される。
オプトアウトは実行ごとの caliber --no-traces <command> か、環境変数 export CALIBER_TELEMETRY_DISABLED=1 で行う。
既存のセットアップ手法との対比
設定ファイルを管理する手段は他にもある。 手書きで都度直す方法、dotfilesリポジトリで使い回す方法、そしてCaliberのように生成と同期を機械化する方法だ。
| 観点 | 手書きCLAUDE.md | dotfiles管理 | Caliber |
|---|---|---|---|
| コード変化への追従 | 手動で書き直し | テンプレ更新が手動 | refresh / フックで自動 |
| 複数AIツールへの展開 | 形式ごとに手作業 | ファイルごとにコピー | 同じ情報源から各形式へ生成 |
| 品質の可視化 | なし | なし | caliber score で100点満点採点 |
| 上書き安全性 | git任せ | git任せ | バックアップ+diff+undo |
| 導入コスト | 低(その場限り) | 中(整備が要る) | 低(bootstrap 1コマンド) |
手法ごとの位置づけを図にすると、手間と追従性のトレードオフが見えてくる。
放置で陳腐化"] D --> D2["再利用は効くが
個別プロジェクト追従は弱い"] CB --> CB2["コミットで自動refresh
scoreで品質を数値化"]
dotfilesが「自分の環境を再現する」道具なのに対し、Caliberは「個々のプロジェクトの実態に設定を合わせ続ける」方向に振れている。
役割が競合するというより、補完関係に近い。
MCPサーバの自動検出も持つため、MCPの基礎を押さえたい場合は MCPサーバーとは|仕組み・代表的なサーバー一覧・自作手順を2026年最新で解説 と併せて読むと、Caliberが生成する .mcp.json の意味がつかみやすい。
想定ユースケース
個人開発では、CLAUDE.mdを手で書く時間をbootstrapに置き換え、コミットのたびに設定が追従する状態を作れる。 リファクタのあとに設定だけ古く残る、という典型的なずれを抑えにいく使い方だ。
チーム展開では、リポジトリにCaliberが入っていると、新しいメンバーの初回セッションでセットアップを促す仕組みが働く。 軽量なセッションフックがpre-commitフックの有無を確かめ、未導入ならセットアップを案内する。 手作業の連絡なしに、チーム全員の設定形式がそろう運用を想定している。
monorepoにも対応する。
caliber init は任意のディレクトリから実行でき、caliber refresh は親ディレクトリから走らせると複数リポジトリの設定をまとめて更新できると説明されている。
CIでは前述のGitHub Actionで、PRごとにスコアのしきい値を品質ゲートとして使える。
複数のAIツールを横断するチームでは、設定形式の不一致がそのままレビューコストになる。
Claude Codeを使う人はCLAUDE.mdを、Cursorを使う人は .cursor/rules を、Codex派はAGENTS.mdを別々に手入れすると、同じプロジェクトでもエージェントごとに前提がずれていく。
Caliberは1つの解析結果から各形式へ展開するため、この形式分断を1コマンドにまとめられる。
スコアをコミット履歴に残せば、設定品質の推移を後から追えるのも運用上の利点だ。
制限事項・注意点
導入前に正直に押さえておきたい点を、公式情報の範囲で挙げる。
確認できる制約(2026-06-18時点)
・生成にはLLMが要る:bootstrapとscoreはローカル完結だが、設定の生成・修正にはAIサブスクかAPIキーが必要
・プロジェクト要約は外部送信:生成時、言語・構成・依存などの要約は設定したLLMプロバイダへ送られる(ソースコード本体は送らないと公称)
・Windowsは注意点あり:IDEチャットではなくターミナルから実行し、Git Bashが推奨。PowerShellのみだとフックが黙ってスキップされる場合がある
・匿名テレメトリが既定で有効:PostHogへコマンド名と実行時間を送信。--no-traces か CALIBER_TELEMETRY_DISABLED=1 で停止
・開発速度が速い:v1.49系まで短期間で多数のリリース。本番採用ではバージョン固定が無難
スコアの「20倍」「10倍」といった効果数値はCaliber自身の公称であり、本記事では独立検証していない。 公式が「公称」する範囲と、本記事がGitHub APIで「実測」したスター数などの数値は区別して読みたい。 未確認の事項は推測で補わず、確認できなかったものは未確認と明記している。
まとめ
Caliber(caliber-ai-org/ai-setup)は、AIエージェント用の設定ファイルを生成し、コードの変化に追従して同期し続けるためのOSSだ。 手書きのCLAUDE.mdが陳腐化する問題に対し、bootstrapでの導入、決定論的なスコアリング、コミット時のrefreshフック、5プラットフォームへの一括展開という具体策で応える。
入口の npx @rely-ai/caliber bootstrap と /setup-caliber はローカル完結で、生成のときだけ手元のAIサブスクを使う。
上書き前のバックアップ、差分レビュー、caliber undo、スコア低下時の自動revertと、設定ファイルをコードレビューと同じ慎重さで扱う作りになっている。
複数のAIツールをチームで併用していて、設定ファイルの形式と鮮度をそろえたいなら、まず caliber score で現状を測るところから試す価値がある。
最新の正確な仕様は、本記事末尾の典拠に挙げた公式リポジトリを正典として確認してほしい。
参照ソース
・caliber-ai-org/ai-setup(公式README・GitHub) — 最終アクセス2026-06-18
・Caliber CHANGELOG(公式)
・Caliber Score GitHub Action(action.yml)
・Caliber install/init flow(docs/FLOW.md)
・@rely-ai/caliber on npm
・Caliber 公式サイト