「音声入力は便利だけど、話した内容や書き起こしたテキストが全部クラウドのサーバーに送られているのは、仕事の内容によっては使いづらい」——そんなもやもやに、完全ローカルで応えるのがFluidVoiceです。FluidVoiceは、音声もテキストも端末の外に出さず、オンデバイスAIで整形(スマートな後処理・文脈に応じた大文字化)まで行う、macOS向けの音声入力(音声→テキストのディクテーション)アプリです。GitHubで約5,700スター(2026年7月時点)を集め、商用のクラウド型ディクテーション「Wispr Flow」のローカル代替として注目されています。
この記事を読むと、①FluidVoiceで結局何ができるのか(ホットキーひとつで話した言葉が整形済みテキストになり、そのまま使っているアプリへ挿入される)、②どんな課題を解決するのか(音声とテキストをクラウドに預けたくない、というプライバシー上の不安)、③何を代替できるのか(Wispr Flowをはじめとするクラウド型・サブスク前提の音声入力の、ローカルで完結する代替になり得る)が分かります。そもそも「AI整形」を担う大規模言語モデルの全体像が曖昧な方は、先にLLM完全ガイド2026を読んでおくと、FluidVoiceが手元で動かす”文章を整える頭脳”の位置づけが掴みやすくなります。

- ・FluidVoiceは音声もテキストもクラウドに送らず、完全ローカルで動かせるmacOS向けの音声入力(ディクテーション)アプリ。
- ・仕組みは「音声入力 → STT(文字起こし)→ AI整形 → アプリへ挿入」の4段パイプライン。各段を差し替えられる。
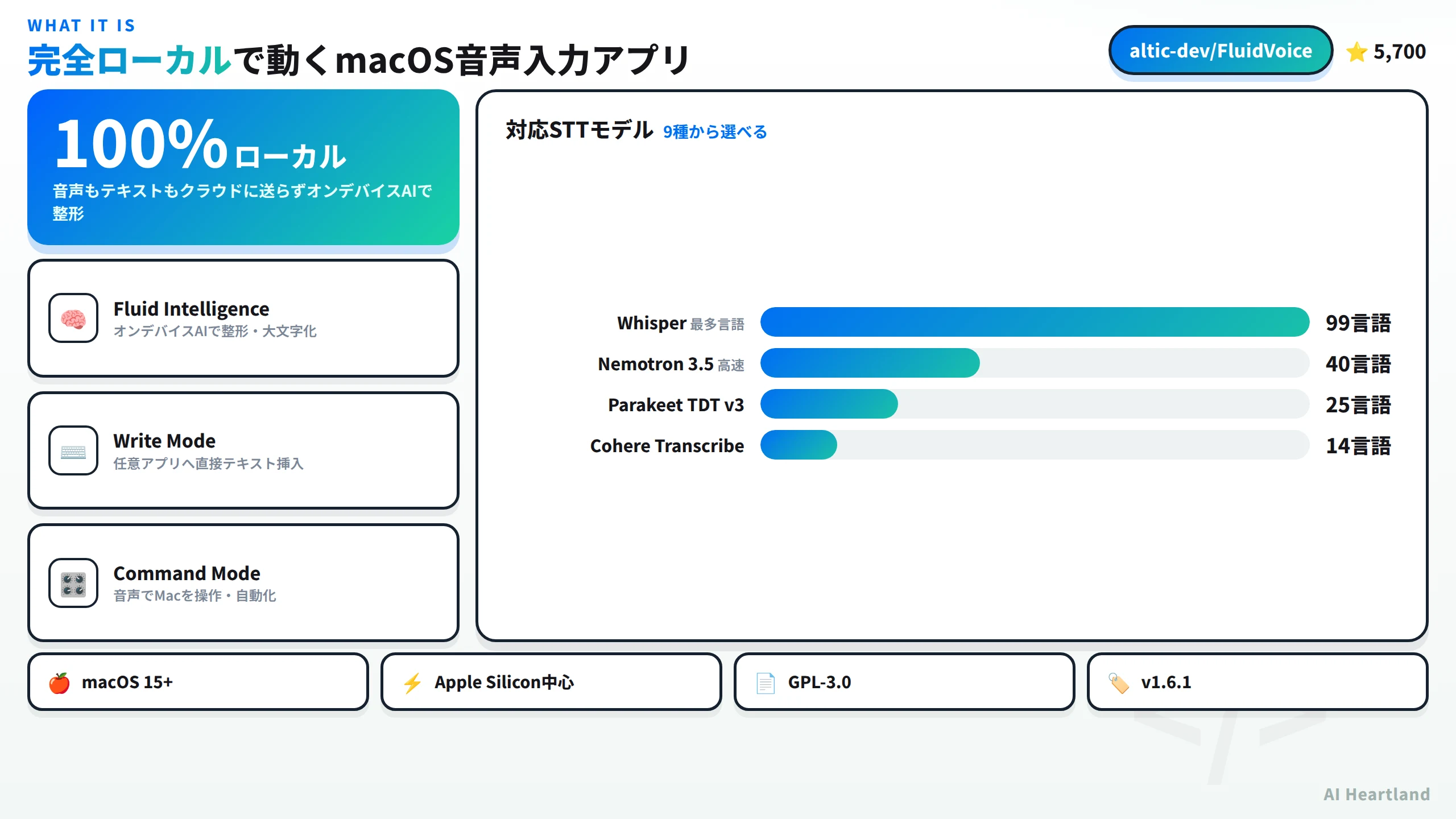
- ・STTは9種のモデルから選べ、AI整形はローカルの「Fluid Intelligence」/OpenAI/Groqから選択できる。
- ・Command Mode(音声でMac操作)、Write Mode(任意アプリへ直接挿入)、Live Preview(リアルタイム表示)まで揃う。
- ・ライセンスはGPL-3.0、最新はv1.6.1。対応はmacOS 15以降で、多くのモデルはApple Silicon前提(IntelはWhisperで対応)。
1. FluidVoiceとは:完全ローカルで動くmacOS音声入力アプリ
FluidVoiceは、話した言葉をその場で文字に変え、AIで整えて、使っているアプリに流し込むまでを、すべて自分のMacの中だけで完結できる音声入力アプリです。ジャンルとしては「ディクテーション(口述筆記)」「音声認識ユーティリティ」「ローカルAIで動く音声入力ツール」に当てはまります。開発は altic-dev、リポジトリは altic-dev/FluidVoice で、実装はSwiftが99.7%を占める、Xcode/SwiftPMベースのネイティブmacOSアプリです。
一番の特徴は名前が示すとおりで、「Fluid(なめらかに)× Voice(声で入力する)」を、クラウドに頼らずオンデバイスで実現している点にあります。一般的なクラウド型の音声入力は、マイクで拾った音声を外部サーバーへ送って文字起こしし、さらにテキストを整える処理もクラウドで行います。便利ですが、中身はブラックボックスで、話した内容も書き起こしたテキストも外に出ていきます。FluidVoiceはその逆で、音声認識(STT)もAIによる整形も、端末内のローカルモデルで賄えるため、ネットにつながなくても入力が成立します。プライバシーを重視する人、機密性の高い文章を扱う人、そして「サブスクに頼らず手元で完結させたい」人のための道具です。
FluidVoiceが立っている位置を整理すると、次の3つの性質を1つにまとめた点が新しいと言えます。
・完全ローカル動作:STTとAI整形をローカルモデルで構成でき、音声もテキストも外に出さずに音声入力を完結できる
・AIによる整形まで含む:ただ文字起こしするだけでなく、オンデバイスの「Fluid Intelligence」でスマートな後処理・文脈に応じた大文字化まで行う
・入力の枠を超えた操作性:音声でMacそのものを操作する「Command Mode」や、任意アプリへ直接テキストを挿入・書き換える「Write Mode」まで備える
これまでも、OS標準の音声入力や、クラウド型の高機能ディクテーションはありました。しかしそれらは「ローカルだが整形が弱い」「整形は賢いがクラウド依存」といった具合に、どこかで妥協が生じます。FluidVoiceが新しいのは、プライバシー(ローカル完結)と、整形の賢さ(オンデバイスAI)を、macOSネイティブの快適さのもとで同時に満たそうとしている点です。「サービスを契約する」というより「自分のMacに音声入力エンジンを一式インストールする」感覚に近いと言えます。
- ・クラウド型音声入力=便利だが音声もテキストも預けきり。FluidVoice=手元で完結する音声入力。
- ・「文字起こし」だけでなく「AIで整える」までをローカルで行うのが、このアプリの核心。
なお、ライセンスには注意点があります。FluidVoiceは2026年2月23日以降、GPL-3.0で提供されています(それ以前はApache-2.0でした)。GPL-3.0はコピーレフト型のライセンスで、改変して再配布する場合の条件がApache-2.0とは異なります。個人利用や社内利用で「そのまま使う」ぶんには気にする場面は多くありませんが、フォークして再配布・組み込みを考える場合は、ライセンスの条件を必ず確認してください。フォーク数は341、最新リリースはv1.6.1(2026年6月28日)と、開発が活発に続いているプロジェクトです。
2. FluidVoiceが解決する課題:クラウド型音声入力(Wispr Flow)の代替

FluidVoiceが解決するのは、クラウド前提の音声入力に付きまとう「預けきり」の不安です。音声入力は、メール・議事録・チャット・コード補助と、日常のあらゆる文章の入り口になります。だからこそ、その入り口がすべて外部サーバーを経由していることに、抵抗を感じる人は少なくありません。
具体的な不満はこうです。
・話した音声や、書き起こしたテキストがクラウドに送られるのが、業務内容によっては使いづらい
・多くのクラウド型ディクテーションは月額サブスクリプションが前提で、使い続けるほどコストがかさむ
・サービスが仕様変更・終了・値上げをすると、入力環境ごと影響を受ける
・ネットが不安定な環境やオフラインでは使えない
こうした課題を、Wispr Flowに代表されるクラウド型ディクテーションは十分には解けません。整形の賢さや使い勝手は優秀でも、その裏側で音声とテキストがクラウドを通る構造は変わらないからです。一方、OS標準の音声入力はローカル寄りですが、AIによる整形や、アプリをまたいだ操作性の面で物足りなさが残ります。
- ・音声入力は最も個人的・機密的なテキスト(下書き・社内情報・アイデア)を生む入り口。その全量がクラウドを通る前提は、人や業務によっては受け入れがたい。
- ・サブスク型は使うほど費用が積み上がり、サービス終了・値上げの影響も避けられない。
FluidVoiceはこの課題に対し、処理の場所そのものを端末内へ引き戻すことで答えます。STTとAI整形をローカルモデルで固めれば、音声もテキストも外に出ません。OSS(GPL-3.0)なので、アプリ自体の利用料はかからず、サブスクの継続コストからも解放されます。ネットが切れていても、ローカルモデルでの文字起こしと整形は動きます。つまり「プライバシー」「コスト」「オフライン耐性」という、クラウド型が構造的に抱える3つの弱点を、まとめて裏返す設計です。
ここで整理しておくと、FluidVoiceは「ローカルで動く音声AIツール」という大きな流れの一員でもあります。声で対話するAIコンパニオンを完全オフラインで動かすOpen-LLM-VTuber(ローカル音声AI)や、音声合成(テキスト→音声)をローカルで担うVibeVoiceと同じく、「クラウドに預けていた音声処理を手元に取り戻す」という発想を、FluidVoiceは”音声入力(音声→テキスト)”の側から実現していると捉えると、位置づけが立体的に見えてきます。
- ・機密性の高い文書を扱う職種(法務・医療・開発など)で、音声入力の内容を外部に出したくない人。
- ・サブスク型ディクテーションの継続コストや、サービス終了リスクを避けたい人。
- ・出張・移動中・ネットワークが制限された環境でも、安定して音声入力を使いたい人。
3. FluidVoiceの主な機能:Fluid Intelligence・Command Mode・Write Mode
FluidVoiceの機能は「音声入力として必要十分」を超えて、Macの操作そのものにまで踏み込んでいます。主要機能を整理します。
Fluid Intelligence(オンデバイスAI整形):FluidVoiceの中核です。文字起こしされた生のテキストを、ローカルのAIモデルがスマートに整形します。フィラー(「えーと」「あの」)の除去や、文脈に応じた大文字化・句読点の調整といった後処理を、クラウドに送らずに行えます。ただ音声を文字にするだけでなく、「読める文章」に仕上げるところまでを端末内で完結できるのが、単なる音声認識ツールとの決定的な違いです。
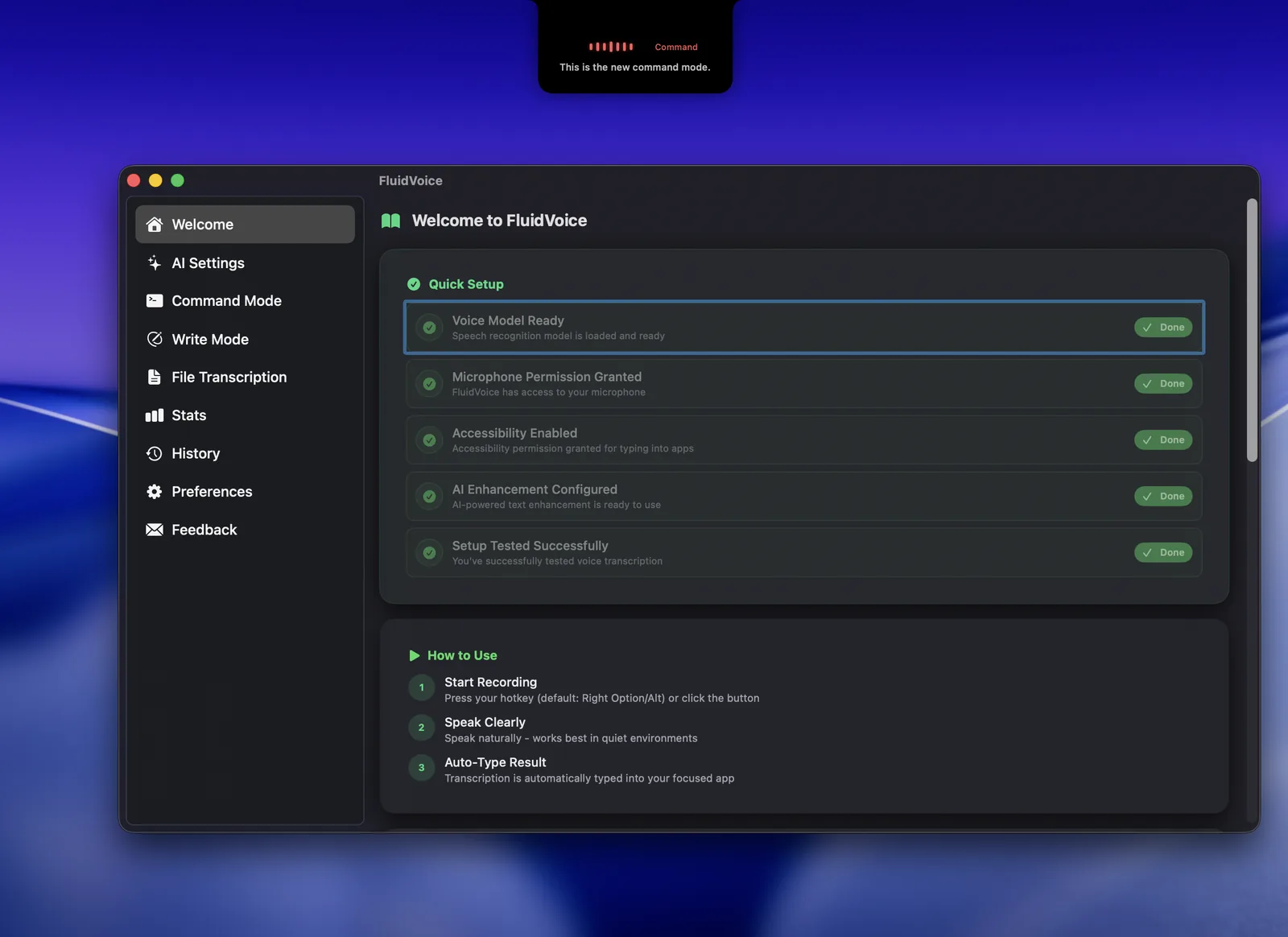
Command Mode(音声でMacを操作):音声でアプリを起動したり、ショートカットを実行したり、システムの自動化を走らせたりできるモードです。上のスクリーンショット上部のノッチに見える赤いオーバーレイが、Command Modeが待機・認識している状態を示します。「文字を入力する」だけでなく「Macに指示する」ところまで音声でカバーします。
Write Mode(任意アプリへ直接挿入・書き換え):文字起こし結果を、いま使っているアプリの入力欄へ直接挿入したり、既存のテキストを書き換えたりできます。エディタ・メール・チャット・ブラウザのフォームなど、フォーカスされているアプリに対してそのまま流し込めるため、コピー&ペーストの手間が要りません。
Live Preview(リアルタイム表示・ノッチ対応):話した内容がリアルタイムで文字起こしされ、オーバーレイとして画面に表示されます。MacBookのノッチ(画面上部の切り欠き)に対応した表示にも配慮されており、認識の様子を見ながら話せます。
これらに加えて、次のような機能が揃っています。
・複数STTモデル(9種):用途に応じて音声認識エンジンを選べる(詳細は第5章)
・AI整形の選択肢:整形はローカルの「Fluid Intelligence」のほか、OpenAI・Groq・カスタムのプロバイダも選べる
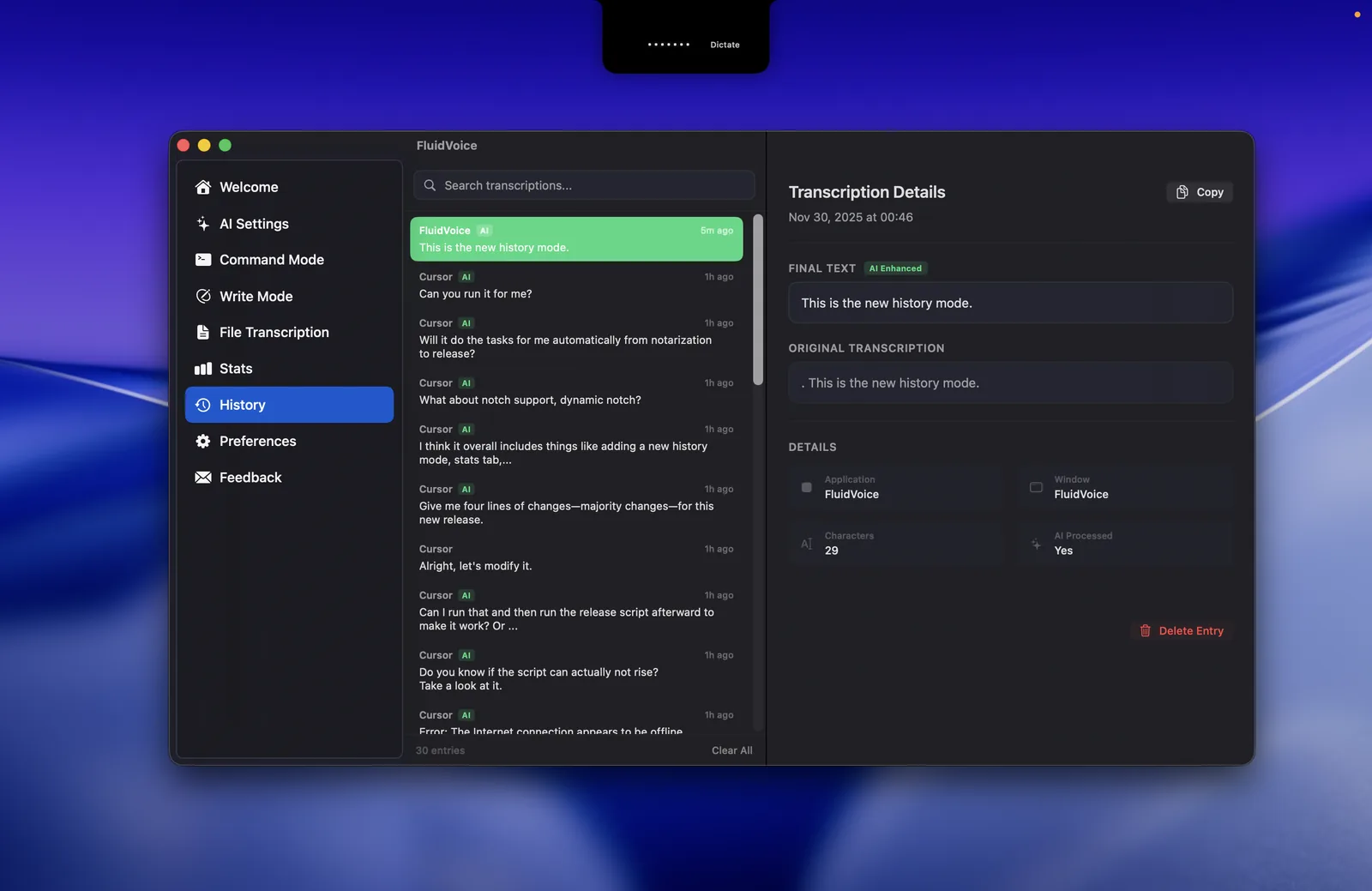
・Audio History(音声履歴):任意でローカルに録音を保存し、エクスポートできる。上のスクリーンショット第2枚(第6章)のように、過去の文字起こしを検索・確認できる
・使用統計(Stats):どれだけ入力したかなどの利用状況を確認できる
・アプリ別プロンプト設定:使っているアプリごとに、AI整形の指示(プロンプト)を変えられる
・グローバルホットキー/メニューバー常駐:どのアプリを使っていても、ホットキーひとつで録音を開始でき、メニューバーに常駐する
・ライト/ダークテーマ・自動更新(ベータチャネル任意):見た目や更新チャネルも選べる
・アクセシビリティ対応:キーボードを使わない操作にも配慮されている
「文字起こし」だけでなく「整形」「操作」「挿入」まで音声で担うことで、FluidVoiceは"入力ツール"から"音声で完結する作業環境"へと踏み込んでいます。とりわけ、Fluid Intelligenceによる整形がローカルで動く点は、プライバシーと実用性を両立させるうえで大きな意味を持ちます。生の音声認識結果は、そのままだと読みづらいことが多いためです。
- ・「認識 → 整形 → 挿入」を1本に束ねているため、別ツールを組み合わせる手間がいらない。
- ・アプリ別プロンプトにより、メールでは丁寧に、コードコメントでは簡潔に、といった文脈適応が効く。
4. FluidVoiceの仕組み:音声→STT→AI整形→アプリ挿入のパイプライン
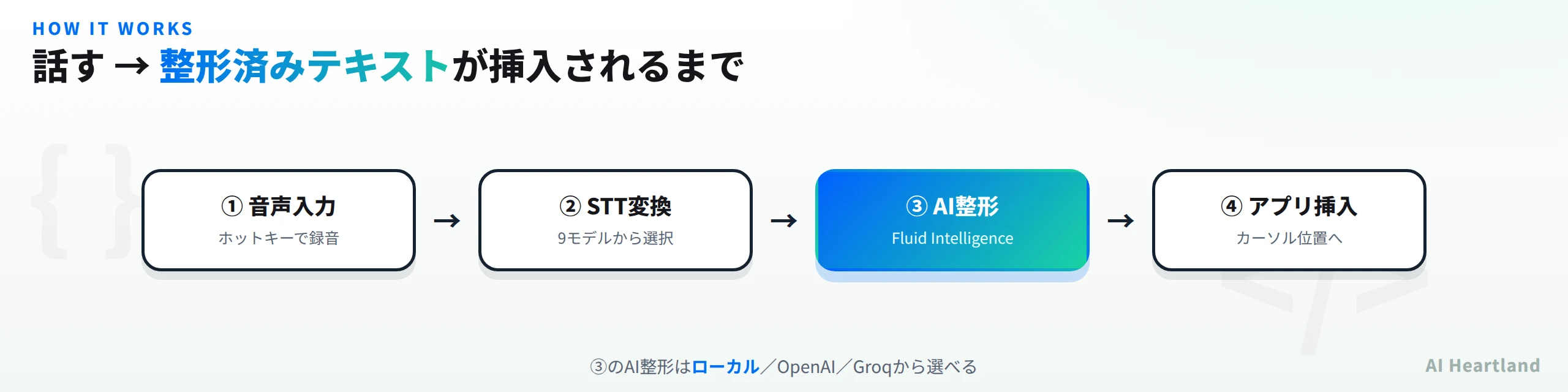
FluidVoiceの内部は、4つの段が直列につながったパイプラインとして理解すると分かりやすくなります。順に、①音声入力 → ②STT(音声認識)→ ③AI整形 → ④アプリへ挿入です。
・①音声入力:グローバルホットキー(初期設定では右Option/Altキーなど)で録音を開始する。メニューバー常駐なので、どのアプリを使っていても即座に呼び出せる。
・②STT(Speech-To-Text):拾った音声を文字に起こす段。Whisper・Parakeet・Nemotron・Cohere Transcribe・Apple Speechなど、9種のモデルから選べる(詳細は第5章)。ここはローカルモデルで動かせる。
・③AI整形:起こされた生テキストを、読める文章へ整える段。ローカルの「Fluid Intelligence」のほか、OpenAI・Groq・カスタムのプロバイダを選べる。フィラー除去・大文字化・句読点調整などの後処理を担う。
・④アプリへ挿入:整形後のテキストを、フォーカスされているアプリのカーソル位置へ挿入する(Write Mode)。
この流れを図にすると次のようになります。ポイントは、②と③がそれぞれ独立して差し替え可能な点です。
グローバルホットキー"] --> STT["② STT変換
9モデルから選択"] STT --> AI["③ AI整形
ローカル / OpenAI / Groq"] AI --> APP["④ アプリへ挿入
Write Mode でカーソル位置へ"] AI --> HIST["Audio History
任意でローカル保存"] MIC -.-> CMD["Command Mode
音声でMac操作へ分岐"]
このパイプライン構造には、実用上の意味があります。各段が疎結合だからこそ、「音声認識の精度・速度だけ変えたい」「整形の賢さだけ上げたい」といった部分最適が容易です。たとえば、まずはOS標準のApple Speechで手軽に試し、精度が欲しくなったらWhisperの大型モデルに変える。整形はプライバシー優先でローカルのFluid Intelligenceに固定しておくが、より高度な言い回しの調整が欲しいときだけOpenAIやGroqに切り替える——といった段階的な調整が、パイプラインの各段を差し替えるだけで済みます。
もう1つ重要なのが、Command Modeへの分岐です。①の音声入力は、必ずしも「文字にして挿入する」だけではありません。Command Modeを使えば、同じ音声入力を「Macへの指示」として解釈させ、アプリ起動やショートカット実行、システム自動化へつなげられます。つまりFluidVoiceは、「声を文字にするパイプライン」と「声を操作にするパイプライン」の両方を、1つのホットキー起点の仕組みとして束ねているわけです。
- ・②STTと③AI整形の両方をローカルにすれば、音声もテキストも端末から出ない(完全オフライン)。
- ・③AI整形にOpenAI/Groqを選ぶと、そこでテキストが外部に送られる。プライバシー重視ならローカルのFluid Intelligenceを選ぶ。
- ・④の挿入・Audio Historyはローカル処理。録音の保存は任意で、エクスポートも手元で行える。
なお、この仕組みを支える前提として、マイクの利用権限と、テキストを他アプリへ挿入するためのアクセシビリティ権限が必要になります。第3章のスクリーンショットのQuick Setupに「Microphone Permission Granted」「Accessibility Enabled」という項目があるのは、このパイプラインを成立させるための土台だからです。権限の付与は初回セットアップで案内されます。
5. STT/ASR 9モデルの比較:言語数・サイズで選ぶ音声認識
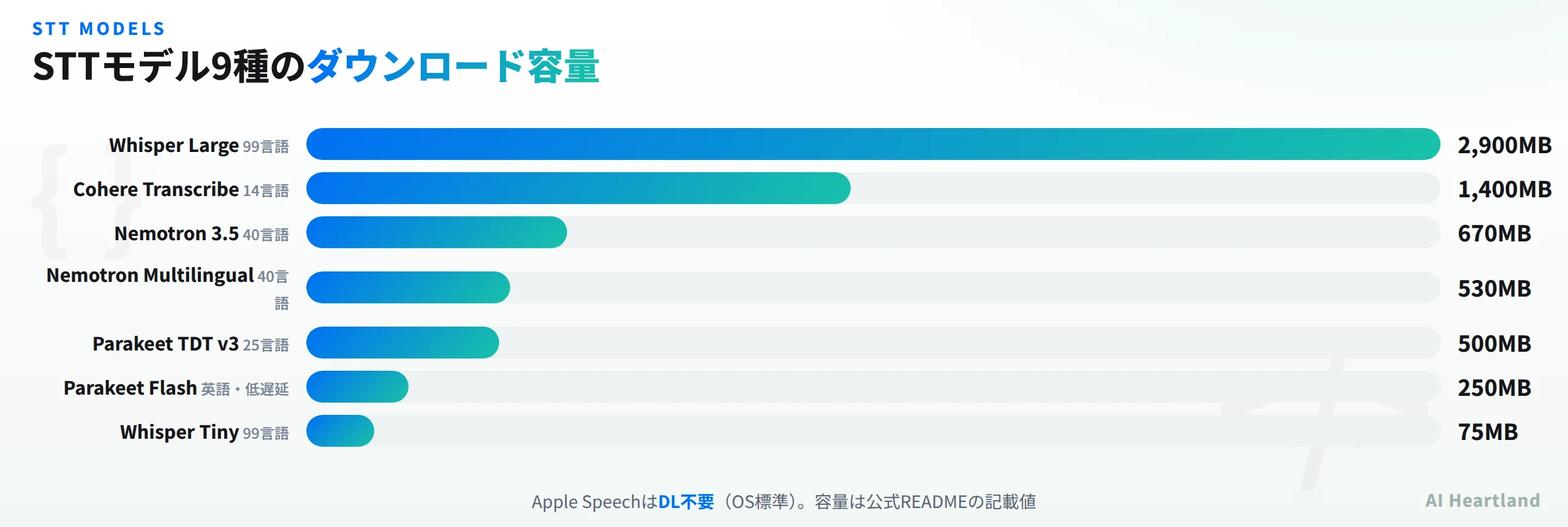
FluidVoiceの音声認識(STT/ASR)は、9種のモデルから用途に合わせて選べるのが大きな強みです。速さ・対応言語数・ダウンロード容量が異なるため、「何を優先するか」で選び分けます。主なモデルを表に整理します。
| STTモデル | 対応言語 | ダウンロード容量 | 向いている用途 |
|---|---|---|---|
| Nemotron Speech 3.5 | 約40言語 | 約670MB | 超高速・多言語を広く扱いたい |
| Nemotron 3.5 Multilingual | 約40言語 | 約530MB | 多言語を軽量に扱いたい |
| Parakeet Flash | 英語 | 約250MB | 最低遅延・英語中心 |
| Parakeet TDT v3 | 25言語 | 約500MB | 多言語をバランス良く |
| Parakeet TDT v2 | 英語 | 約500MB | 英語を安定して |
| Cohere Transcribe | 14言語 | 約1.4GB | 精度重視・主要言語 |
| Apple Speech | OS標準 | DL不要 | まず試す・軽く使う |
| Whisper(Tiny〜Large) | 99言語 | 75MB〜2.9GB | 対応言語の広さ最優先 |
選び方の指針はシンプルです。とにかく速く・低遅延で英語中心なら Parakeet Flash(250MB)。多言語を高速に扱いたいなら Nemotron 系(約40言語)。対応言語の広さを最優先するなら 99言語の Whisper で、精度が欲しければ Large(2.9GB)、軽さが欲しければ Tiny(75MB)と、同じWhisperでもサイズで調整できます。まずダウンロードなしで試したいなら、OS標準の Apple Speech から始めるのが手軽です。
容量の大小は、上のグラフのとおりモデルによって40倍近い開きがあります(Whisper Tiny の75MBに対し、Whisper Large は2.9GB)。ストレージに余裕がなければ軽量モデルを、認識精度を最優先するなら大型モデルを選ぶ、というトレードオフです。多言語モデルほど容量が大きくなる傾向があり、Cohere Transcribe は14言語で約1.4GBとやや大きめです。
- ・速度・低遅延(英語) → Parakeet Flash(250MB)。
- ・多言語を高速に → Nemotron Speech 3.5(約40言語・670MB)/Multilingual(約40言語・530MB)。
- ・対応言語の広さ最優先 → Whisper(99言語、Tiny 75MB〜Large 2.9GB でサイズ調整)。
- ・DL不要でまず試す → Apple Speech(OS標準)。
日本語での音声入力を考えている場合は、多言語対応モデル(Whisper・Nemotronの多言語版・Parakeet TDT v3・Cohere Transcribe)が候補になります。Whisperは99言語対応で日本語を含むことが広く知られていますが、各モデルが日本語をどの精度で扱えるかは、実際に手元の話し方・専門用語で試してみるのが確実です。まずは軽いモデルで認識の傾向を確かめ、精度が足りなければ大型モデルへ、というアプローチが現実的です。なお、Fluid Intelligenceを別途有効化する場合は約3.5GBが追加で必要になるため、音声モデルの容量(約1GB前後)とあわせてストレージを見積もっておくとよいでしょう。
6. FluidVoiceのインストールと設定:brew・権限・モデル選択
FluidVoiceの導入方法は3つあります。Homebrew Cask・リリースからの直接ダウンロード・Xcodeでのソースビルドです。最も手軽なのはHomebrewです。
# 方法1: Homebrew Cask でインストール(最も手軽)
brew install --cask fluidvoice
# 直接ダウンロードしたい場合は GitHub の Releases から
# 最新版(v1.6.1)の .app / .dmg を取得する
# https://github.com/altic-dev/FluidVoice/releases
ソースからビルドしたい場合は、リポジトリをクローンしてXcodeで開きます。実装はSwift(Xcode/SwiftPM)なので、Xcodeがあればビルドできます。
# 方法2: ソースからビルド(Xcode / SwiftPM が必要)
git clone https://github.com/altic-dev/FluidVoice.git
cd FluidVoice
# Xcode で開いてビルド・実行する
open Package.swift
# もしくは Xcode プロジェクトを開いて Run(⌘R)
インストール後、初回起動で行うのが権限の付与です。FluidVoiceは、マイクから音声を拾うための「マイク権限」と、文字起こし結果を他のアプリへ挿入するための「アクセシビリティ権限」を必要とします。第3章のスクリーンショットにあったQuick Setupが、この準備状況(Voice Model Ready/Microphone Permission Granted/Accessibility Enabled/AI Enhancement Configured)をチェックリスト形式で案内してくれます。権限は、macOSの「システム設定 → プライバシーとセキュリティ」から確認・変更できます。
続いてSTTモデルの選択とダウンロードです。第5章で見たとおり、用途に応じて9種から選びます。設定の考え方は、おおむね次のようなイメージです(実際のUIは設定画面で操作します。以下は設定内容を言語化した擬似的な整理です)。
# FluidVoice の設定イメージ(実際はGUIの設定画面で選ぶ)
STTモデル: Parakeet Flash # 速度重視・英語中心なら。多言語ならWhisper等
AI整形: Fluid Intelligence # ローカル完結。OpenAI / Groq も選択可
グローバルホットキー: Right Option # どのアプリでも録音を開始するキー
Audio History: 保存する(任意) # ローカルに録音を残しエクスポート可能
アプリ別プロンプト: Mail → 丁寧な文体で整形 / Code → 簡潔に
FluidVoiceの面白いところは、アプリ別にAI整形のプロンプトを変えられる点です。上の擬似設定のように「メールでは丁寧な文体に、コードコメントでは簡潔に」といった具合に、フォーカスしているアプリごとに整形の方針を切り替えられます。同じ話し方でも、出力先に合わせて仕上がりが変わるため、実務での使い勝手が上がります。
導入時に押さえておきたいのがマシン要件とストレージです。対応OSはmacOS 15.0(Sequoia)以降。多くのSTTモデルはApple Silicon必須で、Intel Macはv1.5.1以降のWhisperで対応します。ストレージは、音声モデルで約1GB前後、オプションのFluid Intelligenceを使う場合はさらに約3.5GBが必要です。上のHistory画面のように、整形前(ORIGINAL TRANSCRIPTION)と整形後(FINAL TEXT・AI Enhanced)を並べて確認できるので、AI整形がどう効いているかを見ながら設定を詰めていくとよいでしょう。
- ・macOS 15.0(Sequoia)以降が必須。それ未満のバージョンでは動かない。
- ・多くのモデルはApple Silicon前提。Intel MacはWhisper(v1.5.1+)で対応するが、選択肢は限られる。
- ・ストレージは音声モデルで約1GB、Fluid Intelligence利用時はさらに約3.5GB。マイク・アクセシビリティ権限の付与も必要。
7. FluidVoiceの導入判断:対応環境・向いている人・注意点

最後に、FluidVoiceを導入すべきかの判断材料を整理します。この音声入力アプリは、明確に向く人とそうでない人が分かれます。
FluidVoiceが向いている人
・プライバシーを重視し、音声入力の内容(音声・テキスト)を外部に出したくない
・クラウド型ディクテーションのサブスク費用を避けたい、あるいはOSSを自前で運用したい
・Apple Silicon搭載のMac(macOS 15以降)を使っていて、快適にローカルモデルを動かせる
・文字入力だけでなく、音声でMacの操作まで自動化したい(Command Mode)
・オフラインや通信が制限された環境でも、安定して音声入力を使いたい
慎重に判断すべきケース
・macOS 15未満のMacを使っている(動作対象外)
・Intel Macで多様なモデルを使いたい(Whisperには対応するが、多くのモデルはApple Silicon前提)
・iOS・Windows・Linuxで使いたい(iOS/Windowsは待機リスト、Linuxは予定で、現状はmacOS専用)
・ストレージに余裕がない(音声モデル約1GB+Fluid Intelligence約3.5GBの容量を要する)
特に注意したいのが対応環境の制約です。FluidVoiceは現状macOS専用で、iOSやWindowsは「待機リスト」、Linuxは「予定」という段階です。したがって、複数OSをまたいで同じ音声入力環境を揃えたい、という用途には現時点では向きません。また、Intel Macでは動く範囲がWhisper中心に限られるため、Nemotronやパラキート系の高速モデルを試したい場合はApple Silicon機が前提になります。
- ・macOS 15.0以降が必須。iOS/Windowsは待機リスト、Linuxは予定で、現状はMac専用。
- ・多くのモデルはApple Silicon必須。Intel MacはWhisper(v1.5.1+)で対応。
- ・ライセンスはGPL-3.0(2026-02-23以降)。フォークして再配布・組み込みを考えるならライセンス条件を要確認。
とはいえ、「音声もテキストもクラウドに送らずに、AI整形まで含めたディクテーションを手元で完結させたい」というニーズに、これほど正面から応えるmacOSアプリは多くありません。GitHubで約5,700スター・341フォークを集め、v1.6.1まで開発が続いていることからも、コミュニティの支持と勢いがうかがえます。クラウド型音声入力に感じていた「預けきり」のもやもやを、根本から解消したい人にとって、FluidVoiceは有力な選択肢です。まずはApple SiliconのMacで、Homebrew経由で入れて、Apple SpeechとローカルのFluid Intelligenceの組み合わせから試してみるのがよいでしょう。
まとめ
FluidVoiceは、「音声入力を、丸ごと自分のMacの中に取り戻す」ためのOSSです。話した言葉を文字に起こし、オンデバイスAIで整え、使っているアプリへ挿入する——その一連を、音声もテキストもクラウドに送らずに完結できるという一点で、クラウド前提のディクテーションから明確に一歩踏み込みました。
- ・FluidVoiceは音声もテキストもクラウドに送らず、完全ローカルで動くmacOS向けの音声入力(ディクテーション)アプリ。
- ・仕組みは「音声入力 → STT → AI整形 → アプリ挿入」の4段パイプライン。STTは9モデル、AI整形はローカル/OpenAI/Groqから選べる。
- ・Fluid Intelligence(AI整形)・Command Mode(音声操作)・Write Mode(直接挿入)・Live Previewまで揃い、Wispr Flow等クラウド型音声入力の代替になり得る。
- ・ライセンスはGPL-3.0、最新はv1.6.1、約5,700スター。対応はmacOS 15以降で、多くのモデルはApple Silicon前提(IntelはWhisperで対応)。
- ・iOS/Windowsは待機リスト、Linuxは予定という開発段階。対応環境の制約を踏まえて選ぶ。
「クラウドに預けきりの音声入力に、どこか落ち着かなさを感じていた」なら、まずはApple SiliconのMacに brew install --cask fluidvoice で入れて、Apple SpeechとローカルのFluid Intelligenceで一言、話しかけてみてください。整形を担うAIの全体像を掴みたい方はLLM完全ガイド2026を、ローカルで動く音声AIの広がりを知りたい方はOpen-LLM-VTuber(ローカル音声AI)やVibeVoiceを、あわせて読むと理解が立体的になります。
参照ソース
・altic-dev/FluidVoice (GitHub) — 公式リポジトリ。README・機能一覧・対応STTモデル・対応環境・ライセンス(GPL-3.0)の一次ソース。
・FluidVoice Releases (GitHub) — v1.6.1(2026-06-28)などリリースノートの一次ソース。バージョンごとの変更点はここで確認できる。
・FluidVoice インストール(Homebrew Cask) — brew install --cask fluidvoice によるインストール手順は公式READMEに記載。