「クラウドの音声アシスタントは便利だけど、話しかけた内容が全部サーバーに送られているのはどうも落ち着かない」「自分だけの、声で話せて、しかも画面の中で表情を変えてくれるAIの相棒がほしい」——そんな願いに、完全にローカルで応えるのがOpen-LLM-VTuberです。Live2Dのアバターが画面に現れ、あなたの声を聞き取り、考え、声で返してくる。しかもその処理を丸ごと自分のPCの中だけで完結できる、音声対話AIコンパニオンのOSSです。GitHubで約12,200スター(2026年7月時点)を集め、ローカルAIコンパニオンというジャンルの代表格になりつつあります。
この記事を読むと、①Open-LLM-VTuberで結局何ができるのか(Live2Dのキャラと声でリアルタイムに会話し、割り込みや視覚認識まで扱える)、②どんな課題を解決するのか(クラウド依存とプライバシー不安、そして「自分好みに作り込めない」もどかしさ)、③何を代替できるのか(クラウド音声アシスタントや有料キャラチャットの、ローカルで自由な代替になり得る)が分かります。そもそもLLMという土台の全体像が曖昧な方は、先にLLM完全ガイド2026を読んでおくと、Open-LLM-VTuberが担う”対話の頭脳”の位置づけが掴みやすくなります。
- ・Open-LLM-VTuberはLive2Dアバターと声で会話できる音声対話AIコンパニオンを、完全オフラインで動かせるOSS。
- ・仕組みはASR(音声→文字)→LLM(応答生成)→TTS(文字→音声)の3段パイプライン。各段を自由に差し替えられる。
- ・割り込み対応のリアルタイム会話、感情に応じた表情、カメラ/画面による視覚認識、デスクトップペット化まで揃う。
- ・LLMはOllama/OpenAI/Claude/Gemini等、ASR/TTSも多数のエンジンから選べる。設定は conf.yaml の編集のみ。
- ・ライセンスはMIT。ただし長期記憶は一時的に無効化中で、v2.0リライトも計画中の活発な開発段階。
1. Open-LLM-VTuberとは:完全オフラインで動く音声対話AIコンパニオン
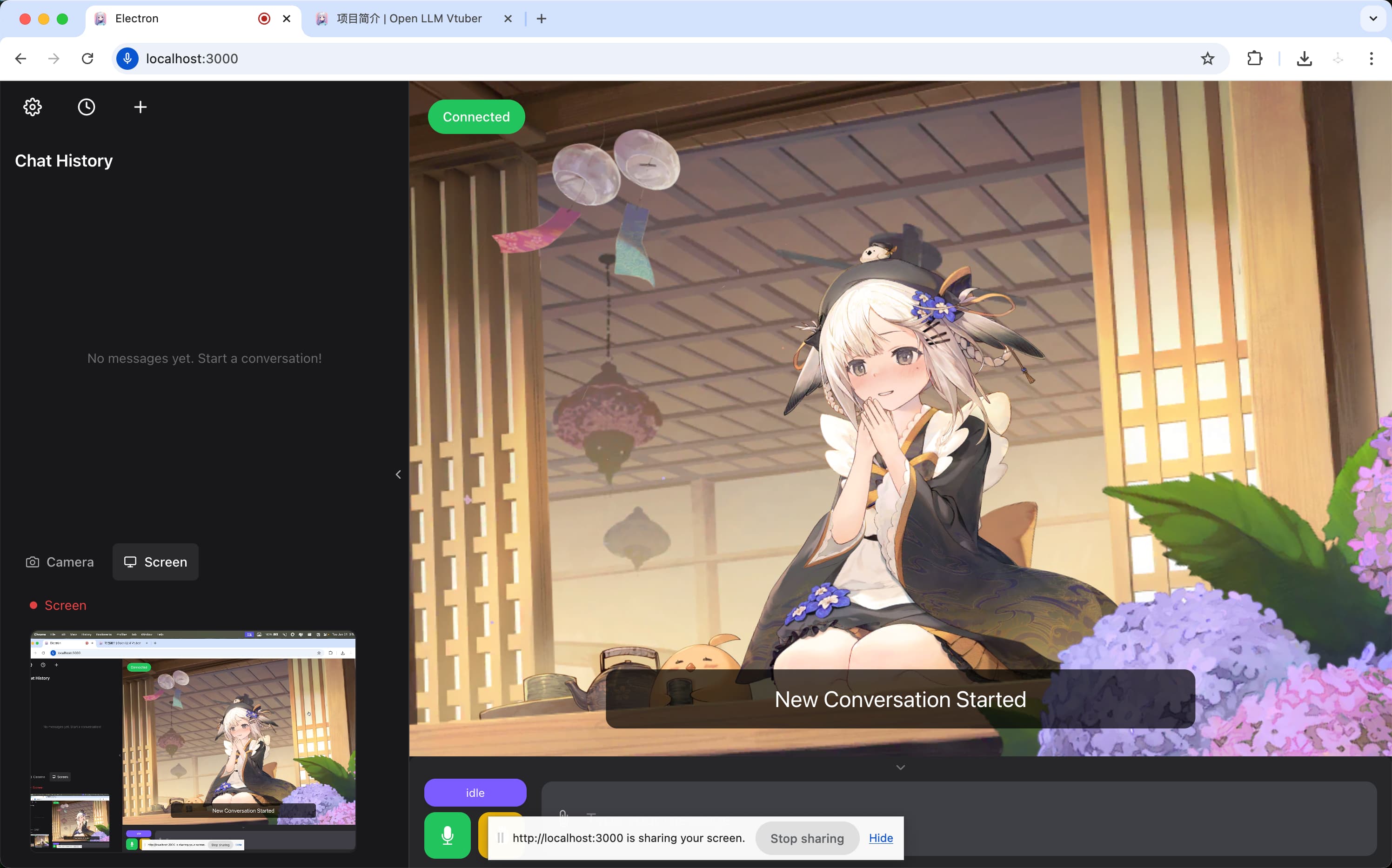
Open-LLM-VTuberは、Live2Dのアバターと声で会話できるAIコンパニオンを、自分のマシンの中だけで動かすためのOSSです。ジャンルとしては「ローカルAIコンパニオン」「デスクトップペット」「音声アシスタント」のどれにも当てはまります。Windows・macOS・Linuxのデスクトップに加え、Webブラウザでも動作します。実装は約96.6%がPythonで、残りをJavaScript(2.8%)やHTMLが占める構成です。
一番の特徴は、名前が示すとおり「Open(オープンで自由)× LLM(大規模言語モデル)× VTuber(アバターで表現する)」を1つに束ねている点です。クラウドの音声アシスタントは便利ですが、中身はブラックボックスで、話した内容はサーバーへ送られます。Open-LLM-VTuberは真逆で、音声認識・思考・音声合成のすべてをローカルエンジンで賄えるため、ネットにつながなくても会話が成立します。プライバシーを重視する人、ネットワークが不安定な環境で使いたい人、そして「自分だけのキャラを作り込みたい」人のための道具です。
Open-LLM-VTuberが立っている場所を整理すると、次の3つの性質を1つにまとめた点が新しいと言えます。
・完全オフライン動作:ASR・LLM・TTSをすべてローカルエンジンで構成でき、クラウド依存を切れる
・アバターによる表現:Live2Dのキャラが感情に応じて表情を変え、「読み上げるだけ」でない存在感を出す
・自由なカスタマイズ:使うモデルやエンジン、キャラクターの人格までを設定ファイルで自在に組み替えられる
これまでも、クラウドのキャラチャットサービスや、単体のTTS読み上げツールはありました。しかしそれらは「表情豊かだがクラウド依存でプライバシーに不安」「ローカルだが声だけでアバターがない」といった具合に、どこかで妥協が生じます。Open-LLM-VTuberが新しいのは、プライバシー・表現力・自由度の3つを、ローカル完結という前提のもとで同時に満たした点です。「有料サービスを契約する」というより「自分のPCに相棒を1体住まわせる」感覚に近いと言えます。名前の”VTuber”が示すとおり、その発想は「無味乾燥なアシスタント」ではなく「表情と声を持ったキャラクター」を手元に置くことにあります。
- ・クラウド音声アシスタント=便利だが中身は預けきり。Open-LLM-VTuber=手元で完結する自由な相棒。
- ・「声で話せて、表情があって、しかもオフライン」を1つに束ねたのがこのOSSの発明。
2. なぜ必要か:クラウド依存とプライバシー不安を解決する
Open-LLM-VTuberが解決するのは、クラウド前提のAIコンパニオンに付きまとう「預けきり」の不安です。音声で日常的に話しかける相手であればあるほど、その内容の機微さは増します。悩みごと、独り言、作業中のつぶやき——それらが常に外部のサーバーへ送られていることに、抵抗を感じる人は少なくありません。
具体的な不満はこうです。
・話しかけた音声や会話履歴がクラウドに蓄積されるのが気持ち悪い
・サービスが仕様変更・終了・値上げをすると、相棒ごと失われる
・キャラの見た目・人格・声を自分好みに深く作り込めない(提供された枠の中でしか遊べない)
・ネットが不安定な環境やオフラインでは使えない
従来ツールはこの一部しか解けません。クラウドのキャラチャットは表現力こそ高いものの、プライバシーとカスタマイズ性で不利です。一方、ローカルのTTS読み上げツールはプライバシーは守れても、アバターも会話の頭脳も持たないため、相棒と呼べる体験にはなりません。
- ・音声アシスタントは最も個人的なデータ(声・生活音・独り言)を扱う。その全量をクラウドに預ける前提は、人によっては受け入れがたい。
- ・サービス依存は「相棒が突然いなくなる」リスクと表裏一体。仕様変更や終了で体験ごと消える。
この問題は、AIコンパニオンを日常に組み込むほど深刻になります。使う頻度が上がるほど、扱うデータは私的になり、そのキャラへの愛着も増していきます。つまり日常に馴染むほど、プライバシーと永続性の重要度が上がるという関係にあります。クラウドサービスを使い込んだ人ほど「便利だが、この会話が全部どこかに送られていると思うと素直に楽しめない」というもやもやを抱えており、Open-LLM-VTuberはまさにその”最後の一線”を自分の手元に取り戻す位置づけです。
Open-LLM-VTuberはこの3つ(プライバシー・永続性・カスタマイズ性)を同時に満たすことで、「安心して、長く、自分好みに使える相棒」に近づけます。会話の流れは次のように整理できます。声を入れると、その音声がローカルで処理され、また声になって返ってくる——この往復がすべて手元で完結します。
マイク入力"] --> ASR["ASR
音声を文字へ"] ASR --> LLM["LLM
応答を考える"] LLM --> TTS["TTS
文字を声へ"] TTS --> S["アバターが発話
表情も変化"] S --> V
Open-LLM-VTuberはこの往復を、ローカルエンジンの組み合わせで自動的に処理します。人間は「クラウドに送られていないか」を気にせず、ただキャラと会話することに集中できます。これは、音声という最も個人的なデータを扱うツールだからこそ効いてくる価値です。
3. Open-LLM-VTuberの主な機能:リアルタイム音声会話・視覚認識・アバター表情
Open-LLM-VTuberの機能は「相棒として自然に振る舞うための最小十分」に絞られつつ、驚くほど幅広く揃っています。主要機能を整理します。
割り込みできるリアルタイム音声会話:AIが話している途中でも、こちらから話しかければ発話を止めて聞き直します。人間同士の会話に近い自然な往復ができます。
Live2Dアバターと感情マッピング:応答内容に応じてアバターが表情を変えます。喜び・驚き・困惑などが動きとして表れ、テキストだけでは得られない存在感が生まれます。
完全オフライン動作:ASR・LLM・TTSをすべてローカルエンジンで構成すれば、クラウドなしで会話が完結します。
デスクトップペットモード:背景を透過してアバターだけをデスクトップに浮かべ、クリックを背後のウィンドウへ通す(クリックスルー)ことができます。作業画面の隅に常駐させられます。
視覚認識:カメラ・画面録画・スクリーンショットを通じて、AIが”見る”ことができます。画面を見せて質問する、といった使い方が可能です。
チャットログの永続化:会話履歴が保存され、後から振り返れます。
AIの「内なる思考」の表示:応答とは別に、AIの考えを画面に表示(発話はしない)できます。キャラの内面が透けて見える演出です。
タッチフィードバック:クリックやドラッグに反応します。単なる読み上げではなく、触れると反応する存在として振る舞います。
能動的な発話(プロアクティブ):こちらが話しかけなくても、AI側から話しかけてくる挙動を持たせられます。
TTS翻訳:たとえば中国語のチャットを日本語の音声で読み上げる、といった言語をまたぐ発話も扱えます。
これだけ揃っていると、体験としては市販のキャラチャットや音声アシスタントに肉薄します。しかも決定的に違うのは、その全部を自分の手元でコントロールできることです。どのエンジンで音声を認識し、どのモデルで考え、どの声で話すか——すべて自分の裁量で決められます。
「割り込める」「見せられる」「表情がある」「常駐できる」——この4つが揃って初めて、AIは"ツール"から"相棒"に変わります。Open-LLM-VTuberはそれをローカルで実現している点が本質です。声だけでも、テキストだけでも、この存在感は生まれません。
ただし正直に添えておくべき点もあります。長期記憶(long-term memory)の機能は、本記事の執筆時点では一時的に取り外されており、公式には「近いうちに復活予定」とされています。チャットログの保存自体はできますが、セッションをまたいで過去の会話を深く踏まえた応答を今すぐ期待するのは早計です。この点は今後のアップデートで改善が見込まれます。誠実に現状を把握したうえで使い始めるのが安全です。
- ・「アバターあり・音声あり・視覚あり・オフライン可」を1本に束ねている。要素ごとに別ツールを組み合わせる手間がいらない。
- ・エンジンを差し替えられるので、軽量ローカルで気軽に試し、必要に応じて高品質エンジンへ乗り換える段階的な運用ができる。
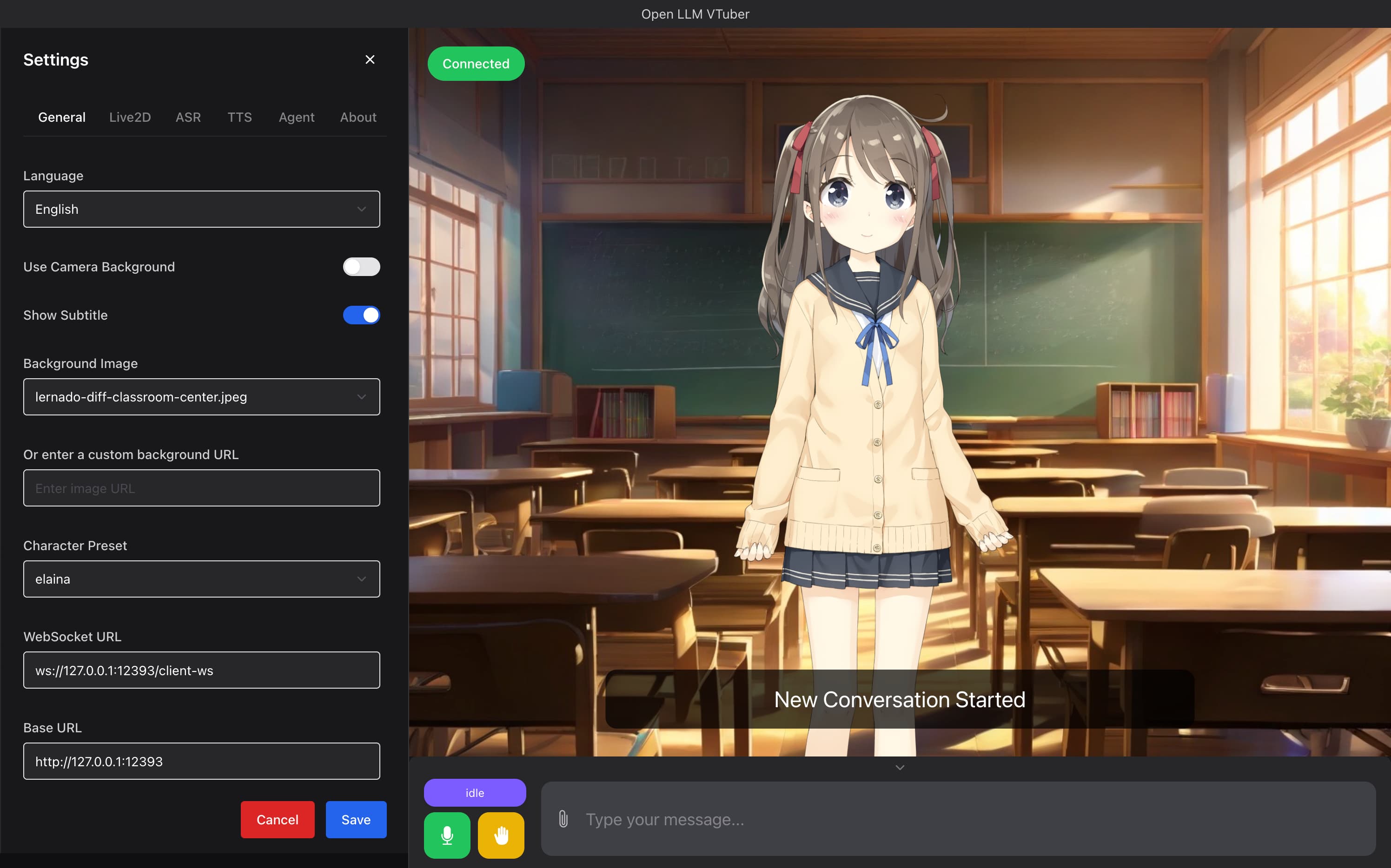
4. Open-LLM-VTuberのインストールと基本操作(conf.yamlで設定)

導入は、公式のQuick Startドキュメントに沿って進めるのが基本です。ここでは要点となるコマンドを押さえます。まず、v1.0.0以降のバージョンでは、更新は専用スクリプトで行います。
# v1.0.0以降のアップデート(プロジェクトディレクトリ内で実行)
uv run update.py
サーバーの起動も、コマンド1つで済みます。
# バックエンドサーバーを起動する
python run_server.py
Open-LLM-VTuberの大きな特徴は、設定をコードではなく conf.yaml という設定ファイルの編集だけで行えることです。使うLLMプロバイダとモデル、ASRエンジン、TTSエンジン、アバター、そしてキャラクターの人格プロンプトを、このファイルにテキストで書き込みます。イメージとしては次のような形です(実際のキー名や構造はバージョンで変わり得るため、必ず公式ドキュメントの最新形を確認してください)。
# conf.yaml の設定イメージ(構造は公式ドキュメントで要確認)
# 使うLLMを指定する(ローカルのOllamaを使う例)
llm:
provider: ollama
model: qwen2.5
# 音声認識エンジンを指定する
asr:
engine: faster_whisper
# 音声合成エンジンを指定する
tts:
engine: sherpa_onnx
# キャラクターの人格を文章で与える
persona: "あなたは親しみやすいAIの相棒です。短く自然に話してください。"
このように、プロバイダ名やモデル名を書き換えるだけで、頭脳(LLM)も耳(ASR)も口(TTS)も丸ごと差し替えられるのが、Open-LLM-VTuberの扱いやすさの核心です。まずは軽いローカルモデルで動作を確認し、応答品質を上げたくなったらクラウドの大型モデルに変える、といった段階的な調整がテキスト編集だけで済みます。プログラミングの知識がなくても、設定ファイルを読み書きできれば十分に遊べる設計です。
新規インストールの場合は、コードを書く前にQuick Startのドキュメントに従うのが確実です。ASR・TTSの各エンジンには個別の導入手順やモデルのダウンロードが必要なものもあり、ここを飛ばすと起動時につまずきやすいためです。「conf.yamlを制する者がOpen-LLM-VTuberを制する」と言ってよく、最初にこのファイルの役割を掴んでおくと、以降のカスタマイズが一気に楽になります。人格プロンプトを書き換えるだけで、まったく別のキャラに変身させられるのも、このファイルの面白いところです。
Webクライアントでマイクを使うときの注意
Webブラウザで動かす場合、マイク入力にはセキュアコンテキスト(HTTPS)が必要です。これはブラウザ側の仕様で、localhost からのアクセスであればHTTPでも許可されますが、別マシンやリモートからアクセスするとHTTPではマイクがブロックされます。手元のPCで localhost として試す分には問題になりませんが、リモート越しに使いたい場合はこの点が壁になります。対処は後半で扱うリバースプロキシです。導入直後は、まず localhost で動作を確かめるのが最短の近道です。
5. Open-LLM-VTuberの仕組みとアーキテクチャ:ASR→LLM→TTSの3段パイプライン
Open-LLM-VTuberの内部は、3つのコンポーネントが直列につながったパイプラインとして理解できます。順に、ASR(音声認識)→ LLM(応答生成)→ TTS(音声合成)です。
・ASR(Automatic Speech Recognition):あなたの声を文字に起こす段。sherpa-onnx・FunASR・Faster-Whisper・Whisper.cpp・Groq Whisper・Azure ASR などから選べる。
・LLM(Large Language Model):起こされた文字を受け取り、キャラの人格に沿って応答を考える段。Ollama・OpenAI(互換含む)・Gemini・Claude・Mistral・DeepSeek・Zhipu AI・GGUF・LM Studio・vLLM などに対応。
・TTS(Text-To-Speech):応答テキストを声に変える段。sherpa-onnx・pyttsx3・MeloTTS・Coqui-TTS・GPTSoVITS・Bark・CosyVoice・Edge TTS・Fish Audio・Azure TTS などから選べる。
・アバター描画:TTSと同期して、Live2Dのキャラが口を動かし、感情に応じて表情を変える段。
この各段が独立して差し替え可能なのが、Open-LLM-VTuberの設計上の妙です。全体像を図にすると次のようになります。デプロイの形態としては、Webクライアント・デスクトップアプリ・バックエンドサーバーという層で構成されます。
Pythonで動く本体"] --> ASR["ASRエンジン
sherpa-onnx等"] BE --> LLM["LLMプロバイダ
Ollama等"] BE --> TTS["TTSエンジン
MeloTTS等"] BE --> AV["Live2Dアバター描画
表情マッピング"] WEB["Webクライアント
ブラウザ HTTPS必須"] --> BE DESK["デスクトップアプリ
ウィンドウ/ペット"] --> BE
このパイプライン構造には運用上の意味があります。各段が疎結合だからこそ、「音声認識だけ精度を上げたい」「声だけ好みのものに変えたい」「頭脳だけクラウドの大型モデルにしたい」といった部分最適が容易です。1箇所を差し替えても他の段に影響が及びにくく、conf.yamlの該当部分を書き換えるだけで済みます。これは、AIアバターを自作しようとして「音声認識」「対話」「音声合成」「アバター制御」を自分でつなぐと膨大になる作業を、丸ごと肩代わりしてくれるということでもあります。
デプロイの形態も押さえておきましょう。バックエンドサーバーが処理の中心で、Webクライアント(ブラウザ)とデスクトップアプリがそのフロントになります。デスクトップアプリには通常のウィンドウモードと、背景透過でデスクトップに常駐するペットモードがあります。図にすると次のとおりです。
バックエンド本体"] --> M1["Webクライアント
ブラウザで表示"] CORE --> M2["デスクトップ
ウィンドウモード"] CORE --> M3["デスクトップ
ペットモード 透過"] M1 --> U1["localhostは可
リモートはHTTPS必須"] M2 --> U2["独立したアプリ画面"] M3 --> U3["クリックスルーで常駐"]
この3つのデプロイモードがあるおかげで、「PCでガッツリ話したいときはウィンドウモード、作業のお供にはペットモード、共有PCやタブレットではブラウザ」といった具合に、状況に応じた使い分けができます。処理の重い部分はすべてバックエンドに集約されているため、フロントは表示と入出力に徹する構造です。概念がシンプルなぶん、どのモードでも同じメンタルモデルで扱えるのが、Open-LLM-VTuberの設計上の強みです。この構造は、音声合成のVibeVoiceのような単機能ツールを、より上位の「対話体験」として束ねる枠組みだと捉えると理解しやすいでしょう。
6. LLM・ASR・TTSエンジンの比較とリモートアクセスの注意
では、Open-LLM-VTuberで何を選べばよいのか。各段の代表的な選択肢と、ローカル/クラウドの性格を表で整理します。
| 段 | 代表的な選択肢 | ローカル/クラウド | 向いている使い方 |
|---|---|---|---|
| LLM(頭脳) | Ollama, LM Studio, vLLM, GGUF | ローカル | 完全オフライン・プライバシー最優先 |
| LLM(頭脳) | OpenAI, Claude, Gemini, DeepSeek | クラウド | 応答品質を最優先・手軽に高性能 |
| ASR(耳) | sherpa-onnx, Faster-Whisper, Whisper.cpp | ローカル | オフラインで音声認識したい |
| ASR(耳) | Groq Whisper, Azure ASR | クラウド | 高速・高精度をAPIで得たい |
| TTS(口) | sherpa-onnx, MeloTTS, GPTSoVITS, CosyVoice | ローカル | 声もオフラインで完結させたい |
| TTS(口) | Edge TTS, Fish Audio, Azure TTS | クラウド | 手軽に自然な音声を得たい |
要するに、プライバシーと完全オフラインを取るならローカルエンジンで固め、応答品質や手軽さを取るなら要所をクラウドに任せる、という住み分けです。全部ローカルにするか、頭脳だけクラウドにするか、といった混在も自由に組めます。
補足すると、Open-LLM-VTuberはローカルとクラウドを”敵対”させていません。conf.yamlの該当箇所を書き換えるだけで、段ごとにローカル/クラウドを混在できます。たとえば「音声認識と音声合成はローカルで完結させてプライバシーを守りつつ、応答生成の頭脳だけはクラウドの大型モデルで賢くする」といった中間解が現実的です。最初はすべてローカルで軽く動かし、物足りない段だけをクラウドに置き換えていく、という段階的な最適化ができます。TTS翻訳のように言語をまたいで発話させたい場合も、TTSエンジンの選択で対応の幅が変わるため、目的に合わせて選ぶとよいでしょう。動画の字幕・翻訳まで含めて多言語を扱いたい人は、pyvideotransのような専用ツールと役割を分けて考えると整理しやすくなります。
そしてもう1つ、実運用で必ずぶつかるのがリモートアクセス時のHTTPS問題です。前述のとおり、Webクライアントでマイクを使うにはセキュアコンテキスト(HTTPS)が必要で、localhost 以外からのHTTPアクセスではマイクがブロックされます。別のマシンやスマホからアクセスして使いたい場合は、リバースプロキシを立ててHTTPS化するのが定石です。構成のイメージは次のとおりです。
ブラウザ"] -->|"HTTPS"| RP["リバースプロキシ
TLS終端"] RP -->|"HTTP"| BE["Open-LLM-VTuber
バックエンド"] BE --> MIC["マイク許可
セキュアコンテキスト成立"]
リバースプロキシでTLS(HTTPS)を終端し、内側はHTTPでバックエンドにつなぐ——この一段を挟むだけで、リモートからでもマイクが使えるようになります。ローカルだけで完結させるなら不要ですが、スマホから話しかけたい、家の中の別マシンで動かしたい、といった一歩進んだ使い方をするなら覚えておきたい定石です。
- ・プライバシーと完全オフライン最優先 → LLM・ASR・TTSをすべてローカルエンジンで固める。
- ・応答品質を手早く上げたい → 頭脳(LLM)だけクラウドの大型モデルに差し替える。
- ・リモートやスマホから使いたい → リバースプロキシでHTTPS化する。
7. Open-LLM-VTuberの導入判断:向いている人・注意点(開発段階とv2.0)

最後に、導入すべきかの判断材料を整理します。
Open-LLM-VTuberが向いている人
・プライバシーを重視し、音声アシスタントをクラウドに預けたくない
・自分だけのキャラクター(見た目・人格・声)を作り込みたいVTuber/キャラ制作者
・AIアシスタントを土台から自分好みにカスタマイズしたい開発者
・デスクトップペットとして作業のお供に常駐させたい
・オフラインやネットワークが不安定な環境でも音声対話を使いたい
慎重に判断すべきケース
・GPUや各エンジンの環境構築を一切したくない(多少のターミナル操作は必要)
・セッションをまたぐ長期記憶が今すぐ必須(現在は一時的に無効化中)
・完成された安定プロダクトを求める(本OSSは活発な開発段階)
特に注意したいのが開発段階とバージョン移行です。Open-LLM-VTuberは活発に開発が進む若いプロジェクトで、いくつか把握しておくべき事情があります。まず長期記憶が一時的に取り外されている点は前述のとおりで、公式には復活予定とされています。次に、v1.0.0では破壊的変更があり、conf.yamlの互換性が失われたため、旧バージョンからは再デプロイが推奨されています。さらに、v2.0のリライトが計画中で、v1系はバグ修正が続く一方、新機能のPRは控えめにするよう促されている状況です。
- ・長期記憶は現在一時的に無効化中(復活予定とされる)。セッションをまたぐ記憶が必須なら現状は非対応と見込む。
- ・v1.0.0で破壊的変更あり。旧バージョンからはconf.yamlが非互換のため、再デプロイが推奨される。
- ・v2.0リライトが計画中。v1はバグ修正中心で、新機能PRは控えめに促されている。最新の開発状況を公式で確認してから始める。
とはいえ、最新リリースはv1.2.1(2025-08-26)で、約12,200スター・フォーク約1,400と、コミュニティの支持は厚いプロジェクトです。ライセンスはMIT(サンプルのLive2Dモデルは別途Live2D Free Material Licenseの対象)で、商用・非商用を問わず自由度が高いのも魅力です。「ローカルで動く、自分だけの音声AIコンパニオン」というニーズ自体は今後さらに一般化していくため、この領域の代表的なOSSを早めに触っておく価値は十分にあります。開発が活発だからこそ、変化を楽しみながら付き合える人に向いた道具だと言えます。
まとめ
Open-LLM-VTuberは、「AIコンパニオンを自分の手元に取り戻す時代」に生まれた、音声対話のためのOSSです。Live2Dのアバター・リアルタイム音声会話・視覚認識を1つに束ねながら、完全オフラインで動かせるという一点で、クラウド前提のサービスから明確に一歩踏み込みました。
- ・Open-LLM-VTuberはLive2Dアバターと声で会話できる音声対話AIコンパニオンを、完全オフラインで動かせるOSS。
- ・仕組みはASR→LLM→TTSの3段パイプライン。各段をローカル/クラウドのエンジンから自由に選べる。
- ・割り込み会話・視覚認識・感情表情・デスクトップペット化まで揃い、クラウド音声アシスタントの自由な代替になり得る。
- ・設定はconf.yamlの編集のみ。プログラミング必須ではないが、環境構築には多少のターミナル操作がいる。
- ・ライセンスはMIT。ただし長期記憶は一時無効化中、v2.0リライトも計画中の活発な開発段階である点は要理解。
「クラウドに預けきりの音声アシスタントに、どこか落ち着かなさを感じていた」なら、まずは公式のQuick Startに沿って python run_server.py で立ち上げ、軽いローカルモデルで一言、話しかけてみてください。対話の頭脳であるLLMの全体像を掴みたい方はLLM完全ガイド2026を、音声合成そのものを深掘りしたい方はVibeVoiceを、あわせて読むと理解が立体的になります。
参照ソース
・Open-LLM-VTuber/Open-LLM-VTuber (GitHub) — 公式リポジトリ。README・対応エンジン一覧・技術構成の一次ソース。
・Open-LLM-VTuber 公式ドキュメント — Quick Start・conf.yamlの設定・デプロイ方法の公式ドキュメント。
・Open-LLM-VTuber Releases (GitHub) — v1.0.0の破壊的変更・v1.2.1などリリースノートの一次ソース。