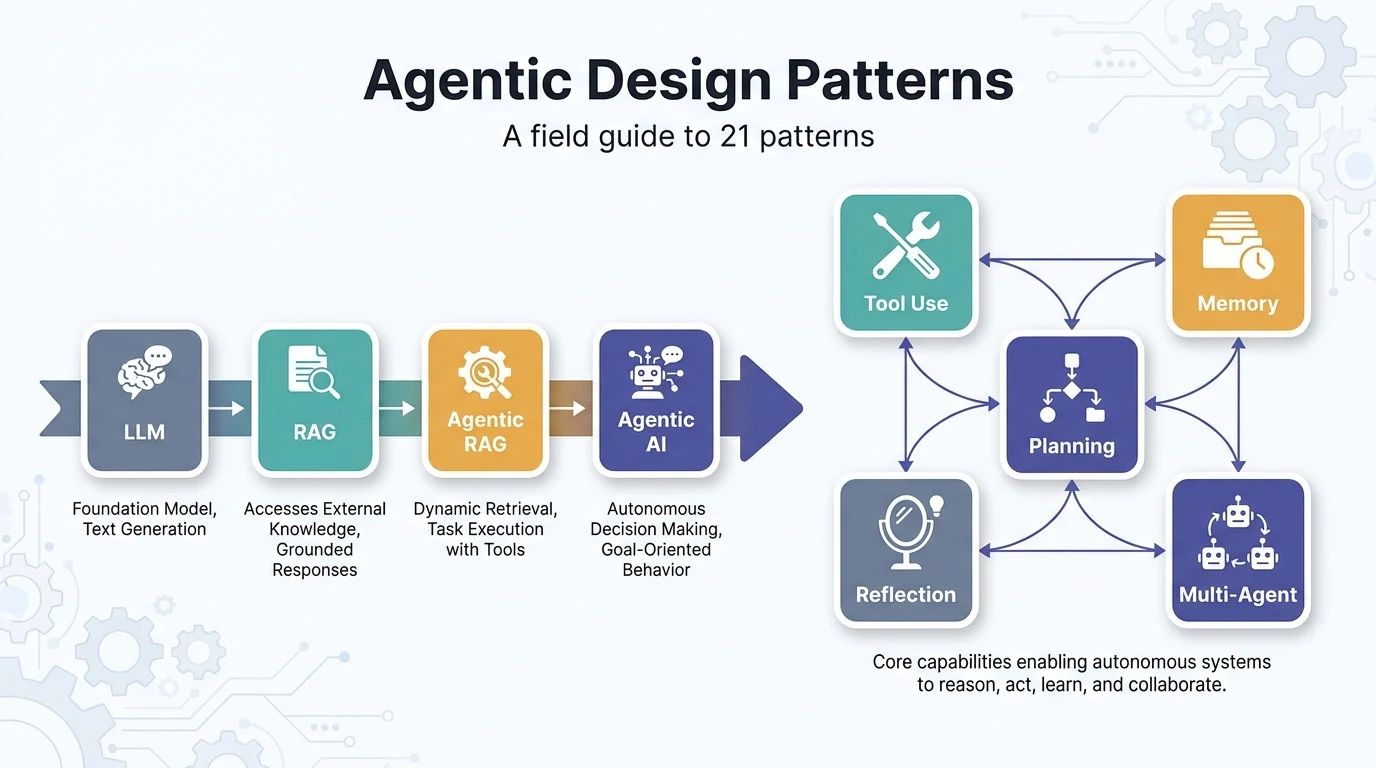
この記事ではAIエージェントに特化して解説します。AIエージェント全般は AIエージェントフレームワーク比較2026年版 をご覧ください。
バイブコーディングからエージェンティック開発へ——2026年に起きた転換
2025年、Andrej Karpathyが「vibe coding(バイブコーディング)」という概念を広めた。自然言語でAIに指示し、生成されたコードをそのまま受け入れるスタイルだ。CursorやBolt.newの登場で、非エンジニアでもアプリを作れる時代が到来した。
しかし2026年、この流れは次の段階に進んだ。Harvard Gazette(2026年4月)は「バイブコーディングはAIの未来を理解する入り口」と位置づけた。Harvardの教育学部でKaren Brennan教授がReplit・Figma Make・Claude Codeを使った6週間のバイブコーディング講座を開講し、非エンジニアのソフトウェア創造を民主化する実験を行っている。
一方、本番環境では「バイブ」だけでは通用しない。Amazonは2025年Q3にAIコーディングアシスタントQ起因のインシデントを受け、90日間のコードデプロイメントリセットを実施した。バイブコーディングの限界——レビュー不足・技術的負債・セキュリティホール——が露呈し、エージェンティック開発への移行が加速している。
バイブコーディング"] -->|"限界露呈"| B["2026年
エージェンティック開発"] A --> A1["自然言語→コード生成"] A --> A2["レビュー最小限"] A --> A3["プロトタイプ向き"] B --> B1["AIが実行、人間が設計"] B --> B2["全diffをPRレビュー"] B --> B3["本番運用対応"]
Anthropicレポートが示すエージェンティック開発の実態
Anthropicが2026年1月に公開した「2026 Agentic Coding Trends Report」は、エージェンティック開発の現状を定量的に示している。
主な発見:
- 開発者の60%がAIを業務に統合済み
- 委任したタスクの80〜100%で人間が積極的な監視を維持
- マルチエージェントシステムが単一エージェントを置換——並列推論が標準に
- タスクホライゾンが数分から数日〜数週間に拡大
- 戦略的な人間チェックポイントでのみエージェントが停止
# Anthropicレポートの4つの戦略的優先事項
strategic_priorities:
1: マルチエージェント協調の設計
2: 人間-エージェント間の監視スケーリング
3: エンジニアリング以外へのエージェンティック開発の拡張
4: セキュリティをゼロから組み込む設計
Gartnerの予測はさらに踏み込んでいる——2026年末までに企業アプリの40%がタスク特化型AIエージェントを搭載する(2025年は5%未満)。2035年にはエージェンティックAIがエンタープライズソフトウェア収益の30%(4500億ドル超)を占める見通しだ。
バイブコーディング vs エージェンティック開発——何が違うのか
| 観点 | バイブコーディング(2025年) | エージェンティック開発(2026年) |
|---|---|---|
| コード所有権 | AIに委譲 | エンジニアが保持 |
| レビュー規律 | 最小限または省略 | 全diffを人間PRと同水準でレビュー |
| 適性スコープ | ハッカソン、プロトタイプ | 本番CI/CD、大規模リファクタ |
| 人間の役割 | パッシブなプロンプター | アクティブなオーケストレーター |
| 主なリスク | 技術的負債、セキュリティ | コグニティブデット(文脈喪失) |
| ワークフロー | 対話的、アドホック | 仕様→エージェント実行→人間レビュー |
Andrej Karpathyはこの転換を「agentic engineering」と名付けた——「デフォルトは99%の時間コードを書かないこと。エージェントをオーケストレーションすること」。
AI開発ツールの使い分け:エディタ型 vs エージェント型
2026年のAI開発ツールは大きく2カテゴリに分かれる。
| ツール | カテゴリ | 強み | 料金(2026年) |
|---|---|---|---|
| Cursor | AIエディタ(VS Code fork) | 最速のオートコンプリート、日常コーディング | $20/月(Pro)、$200/月(Ultra) |
| Windsurf | AIエディタ | コスパ最良のエージェンティックIDE | $15/月 |
| Claude Code | ターミナルエージェント | 大規模リファクタ(40+ファイル)、深いコンテキスト | 従量課金 |
| GitHub Copilot | AIアシスタント | エントリーレベル、無制限補完 | $10/月 |
| OpenAI Codex | クラウドエージェント | 並列タスク実行 | 従量課金 |
経験豊富な開発者は両方を併用している。日常のコーディングにはCursor/Windsurfのインラインエディタ、大規模リファクタや複数ファイルにまたがる作業にはClaude Code/Codexのターミナルエージェント——この使い分けが2026年のベストプラクティスだ。
マルチエージェントシステムが本番に入った——数字で見る普及状況
2026年、マルチエージェントシステムは実験段階を超えた。
- Global 2000企業の72%がAIエージェントシステムをパイロット段階以降で運用中
- マルチエージェントオーケストレーションへの問い合わせが1,445%急増
- 投資1ドルあたり5〜10倍のROIを報告
- コスト削減、生産性向上が典型的な成果
Claude Managed Agentsのように、エージェントの構築からデプロイまでをクラウドで管理するサービスが登場し、インフラ構築のハードルが大幅に下がったことが普及を加速させている。
# マルチエージェント構成の実例(ソフトウェア開発)
# 1つのSupervisorが4つの専門エージェントを指揮
agents = {
"requirements": Agent(role="要件分析", tools=["jira", "confluence"]),
"coder": Agent(role="コード生成", tools=["github", "lint"]),
"tester": Agent(role="テスト実行", tools=["pytest", "coverage"]),
"deployer": Agent(role="デプロイ管理", tools=["docker", "k8s"]),
}
# 共有コンテキストで協調動作
supervisor = Supervisor(agents=agents, human_checkpoint="deploy")
「Human-in-the-Loop」から「Human-above-the-Loop」へ
2026年の重要なパラダイムシフトは、人間の監視モデルの進化だ。
従来の「Human-in-the-Loop」はすべてのステップで人間が介入していた。2026年は「Human-above-the-Loop」——信頼が確立された高頻度・低リスクの判断はAIが自律的に処理し、重要な決定ポイントでのみ人間が介入するモデルに移行している。
EU AI Act第14条もこの方向を後押ししている——高リスクAIシステムでは「受動的な承認者」ではなく「訓練された意思決定者」による監視が義務化された。
LangGraphのinterrupt()パターンは、この思想を技術的に実装したものだ。
# LangGraphのinterrupt()による人間チェックポイント
from langgraph.types import interrupt
def deploy_node(state):
# デプロイ前に人間の承認を要求
approval = interrupt({
"action": "production_deploy",
"changes": state["diff_summary"],
"risk_score": state["risk_assessment"],
})
if approval.get("approved"):
return execute_deploy(state)
return {"status": "rejected", "reason": approval.get("reason")}
2026年に「Agentic AIエンジニア」が求められる理由
以上の転換を踏まえると、2026年に「Agentic AIエンジニア」が新しい職種として急速に定義されつつある理由が明確になる。従来のMLエンジニアがモデル学習とデプロイに集中していたのに対し、Agentic AIエンジニアはツール連携・メモリ管理・マルチエージェント設計・安全性を含む幅広いスキルセットが求められる。
Lamhot Siagian氏が公開した「Complete Roadmap to Become an Agentic AI Engineer in 2026」は、この新しい領域の学習パスを9ステップ・100問のQ&A形式で体系化したPDFガイドだ。以下では、ロードマップの100問から各ステップの核心を抜粋し、Q&A形式で日本語解説する。
ロードマップの全体像:9ステップの学習順序
このロードマップは「foundation-first(基礎から固める)」の原則に従い、以下の順序で学習を進める。
型・async・テスト"] --> B["2. LLM基礎
トークン・プロンプト"] B --> C["3. フレームワーク選定
LangGraph vs CrewAI"] C --> D["4. 高度な概念
LCEL・ワークフロー"] D --> E["5. メモリ管理
短期・長期・チェックポイント"] E --> F["6. ツール連携
スキーマ・安全性"] F --> G["7. RAGシステム
ベクトル検索・リランキング"] G --> H["8. マルチエージェント
ReAct・Supervisor"] H --> I["9. 本番運用
FastAPI・Docker・AWS"]
各ステップは前のステップを前提としており、フレームワークを先に触ってPython基礎を後回しにするのはロードマップが明確に否定しているアンチパターンだ。
| ステップ | 学習内容 | 所要期間目安 |
|---|---|---|
| 1. Python基礎 | 型ヒント、async/await、Pydantic、テスト | 2-4週 |
| 2. LLM基礎 | トークン、コンテキストウィンドウ、プロンプト設計 | 1-2週 |
| 3. フレームワーク選定 | LangGraph、CrewAI、AutoGen比較 | 1-2週 |
| 4. 高度な概念 | LCEL、Runnable、ワークフロー | 2-3週 |
| 5. メモリ管理 | 短期・長期メモリ、チェックポイント | 1-2週 |
| 6. ツール連携 | カスタムツール、スキーマ設計 | 2-3週 |
| 7. RAG | ベクトルDB、ハイブリッド検索、リランキング | 2-4週 |
| 8. マルチエージェント | ReAct、Supervisor、通信プロトコル | 2-3週 |
| 9. 本番運用 | FastAPI、Docker、AWS、CI/CD | 2-4週 |
ステップ1-2:Python基礎とLLM理解——Q&Aで学ぶ土台
ロードマップの100問から、最初の2ステップの核心部分を抜粋する。
Q. なぜPydanticがエージェント開発で重要なのか? A. エージェントがツールを呼び出す前に入力を検証するため。LLMはハルシネーションでパラメータを誤る場合があり、Pydanticの型付きスキーマがそれをキャッチする。不正な入力は明確なエラーとして返され、エージェントの自己修復ループに回せる。
from pydantic import BaseModel, Field
class WeatherArgs(BaseModel):
city: str = Field(..., min_length=2)
units: str = Field("metric", pattern="^(metric|imperial)$")
# エージェントがツールを呼ぶ前にバリデーション
# 不正な入力は明確なエラーとして返され、自己修復ループに回せる
Q. コンテキストウィンドウのバジェッティングとは? A. エージェント設計の最大の制約はコンテキストウィンドウ。ロードマップは配分の目安を示している:指示に30%、検索結果に30%、メモリに20%、ツール出力に20%。この配分を超えると重要な指示がプッシュアウトされ、エージェントが指示を「忘れる」。
Q. Function Calling(ツール呼び出し)はなぜ重要か? A. モデルが自由形式テキストではなく構造化されたツール呼び出し(関数名+引数)を出力すること。これにより確実な実行・バリデーション・サンドボックスが可能になる。エージェントの「考える」と「実行する」を分離する核心的な仕組みだ。
ステップ3:フレームワーク選定——最大のアンチパターンを避ける
Q. LangGraph、CrewAI、AutoGenのどれを選ぶべきか?
| 項目 | LangGraph | CrewAI | AutoGen |
|---|---|---|---|
| アーキテクチャ | グラフベース(ノード+エッジ) | ロールベース(宣言的) | エージェント間チャット |
| 状態管理 | 明示的(チェックポイント対応) | フレームワーク管理 | 会話履歴ベース |
| 適性 | 複雑なワークフロー、本番運用 | プロトタイプ、チーム構成 | 研究、実験 |
| 学習コスト | 高 | 中 | 中 |
| 2026年の状態 | 活発な開発 | 活発な開発 | メンテナンスモード |
詳しい比較はAIエージェントフレームワーク比較2026年版を参照してほしい。
Q. フレームワーク選定で最大のアンチパターンは? A. フレームワークをアーキテクチャと混同すること。フレームワークは実装ツールであり、アーキテクチャはステートモデル・ツール境界・データ契約・安全規則で構成される。フレームワークの前に基礎を固めなければ、フレームワークが混乱を増幅する。
ステップ4-6:メモリ・ツール連携——Q&Aで学ぶコア技術
Q. エージェントのメモリの2種類とは? A. 短期メモリ(会話履歴、ツール出力、現在のタスク状態——コンテキストウィンドウ内)と長期メモリ(データベース、ベクトルストア、ユーザープロファイル——外部ストレージ)。特に重要なのはチェックポイントで、長時間実行エージェントの状態を保存し、障害時の復旧や人間承認フローへの対応を可能にする。
Q. ツールを「エージェントフレンドリー」にする設計原則は? A. 4つの原則がある。(1) 明確な名前と狭い目的(1ツール1機能)、(2) 型付き入力スキーマ(Pydantic)、(3) 決定論的出力(構造化データ、ナラティブではない)、(4) タイムアウトとエラーハンドリング。MCPプロトコルもツール連携の標準化として注目されている。
Q. RAGでハイブリッド検索が推奨される理由は? A. dense(ベクトル検索=意味的な近傍取得)とsparse(BM25=キーワード完全一致)を組み合わせること。片方だけでは「意味は近いが用語が違う」または「用語は一致するが文脈が違う」結果を見逃す。最終的にcross-encoderでリランキングし、上位結果の精度を高める。
ステップ7-8:マルチエージェントとReActパターン
Q. ReActパターンとは何か? A. Reasoning + Acting。推論(plan)とアクション(tool call)を交互に繰り返すパターン。エージェントが「推測」ではなく「調べてから判断する」ため、事実性が向上する。
Q. マルチエージェント(Supervisorパターン)はいつ使うべきか? A. タスクの分解が本当に有益な場合にのみ使う。例えば、Retriever(情報収集)→ Summarizer(要点抽出)→ Writer(草稿作成)→ Critic(根拠チェック)の4エージェント構成。ただし単一エージェントで十分なケースでマルチエージェントにすると、協調オーバーヘッドとデバッグ複雑性だけが増す。Semantic Kernelのようなフレームワークもこの原則に基づいて設計されている。
ステップ9:本番デプロイ——プロダクションレディネスの要件
Q. 「本番レディ」の定義は?
| 要件 | 具体的な対策 |
|---|---|
| 信頼性 | 構造化出力、スキーマバリデーション、リトライ戦略 |
| 安全性 | ツールのallowlist、サンドボックス、確認フロー |
| 観測性 | リクエストID、トレーシング、ツール別エラー率 |
| 保守性 | 評価スイート、カナリアデプロイ、プロンプトのバージョン管理 |
| コスト制御 | トークン使用量の監視、キャッシュ戦略、レート制限 |
# 本番アーキテクチャの全体像
UI (Streamlit/React)
↓
API (FastAPI)
↓
Agent Orchestrator (LangGraph)
↓
Tools (内部サービス/API) + RAG (ベクトルストア) + Memory (DB)
↓
Observability (ログ/トレース/メトリクス) + Evaluation パイプライン
Q. 面接でAgentic AIエンジニアとして何を示すべきか? A. 2-3個の具体的なプロジェクト(小規模でも可)を持ち込み、ツール使用・RAG・評価・本番思考を示すこと。加えて、1つのデバッグ経験(検索ノイズ、ツールタイムアウト、スキーマパースエラーなど)を説明できることが重要。
# ロードマップ推奨のプロジェクト構造
my_agent/
├── app/ # API/UIエントリポイント(FastAPI)
├── core/ # ドメインロジック、プロンプト、ポリシー
├── agents/ # エージェントグラフ、ルーター
├── tools/ # ツールラッパー、スキーマ(Pydantic)
├── rag/ # チャンキング、検索
├── eval/ # テスト、ゴールデンセット
├── infra/ # Docker、設定
└── pyproject.toml
参照ソース
- 2026 Agentic Coding Trends Report — Anthropic (PDF)
- ‘Vibe coding’ may offer insight into our AI future — Harvard Gazette
- Gartner Predicts 40% of Enterprise Apps Will Feature AI Agents by 2026
- From Vibe to Agentic: The 2026 Maturation of AI-Driven Development — Medium
- Complete Roadmap to Become an Agentic AI Engineer in 2026 — Lamhot Siagian (PDF)
- LangGraph公式ドキュメント
- CrewAI公式ドキュメント