AnthropicのMargot van Laar(Member of Technical Staff)が「Code w/ Claude」イベントで34分にわたって公開した「The Prompting Playbook」は、現場エンジニアが直面する2つのシナリオ――既存プロンプトのデバッグと新規エージェントの構築――を実際のデモとコードで解説した濃密なセッションだ。プロンプトは「なんとなく動いている」状態から「測定可能な基準で改善できる」状態へ引き上げることができる。本記事ではそのすべての手法を体系的に解説する。
Claude Codeの全体像やAnthropicのエンジニアリング哲学については Claude Code|2026年版・インストールからCLAUDE.md・Hooks・本番運用までの実装手引き を参照されたい。
プロンプト設計は「なんとなく良い」から卒業できる

LLMを使い始めた当初、プロンプトエンジニアリングは「最初に学ぶスキル」だった。しかし今もなお、効果的なAIシステムを構築するうえで最も重要なスキルの一つであることに変わりはない。Margotが示すのは、プロンプトをアドホックに触るのではなく、測定・仮説・検証のサイクルで体系的に改善するアプローチだ。
セッションで扱うのは以下の2つのシナリオだ:
- シナリオ1: 本番で稼働中のプロンプトを新モデルへ移行したところ、テストケースが通らなくなった
- シナリオ2: 新しいエージェントユースケースをゼロから設計する

現実の本番プロンプトはこのスライドで示されたように「複数人が長期間にわたって共同編集し、オーナーが不明確で、ポリシー・トーン・プロセス・過去モデル向けパッチがひとつのブロックに混在」した状態になりがちだ。新モデルへの移行時に突然テストが壊れる原因は、モデルの能力低下なのか、プロンプトの問題なのか——それを切り分ける手段なしに闇雲に修正しても、改善は偶然に頼るしかない。
Margotが繰り返し強調するのは「Evalなき改善は賭け事」という原則だ。プロンプトの変更が本当に改善をもたらしているのかを確認するには、定量的な評価セットが不可欠である。
Eval(評価セット)がなければ改善は賭け事になる

evalを設計するうえで重要なのは、以下の3種類のテストケースを必ず含めることだ:
1. コントロールケース(常に通るべきケース) モデルが確実に処理できる明確なリクエスト。新しいプロンプトバージョンが意図せず既存機能を壊していないかを検出する安全網。
2. エッジケース(過去に失敗したケース) 以前の失敗をプロンプトで修正した後、将来の回帰を防ぐための番犬。プロンプトに指示を追加したのと引き換えに、別の挙動が壊れていないかを継続チェックする。
3. 境界ケース(人間へのハンドオフ判断) モデルが「これは自分の守備範囲外」と正しく認識し、人間にエスカレーションできるかを検証する。能力の限界を自覚させることは、最近のモデルになるほど重要になる。
デモで使用したテストセットはこの設計原則に従った5ケースだ:

| ケース種別 | 顧客メッセージ | 合格条件 |
|---|---|---|
| コントロール | 基本プランのデータ上限は? | 5GBと回答 |
| 能力/ポリシーギャップ(Pro率計算) | 30GBプランに今日アップグレードしたら次回請求は? | $70.00を正確に計算 |
| ポリシー遵守(プリペイド免責事項) | プリペイドですが今日Premiumに変更できますか? | 全文の免責事項を含む |
| エスカレーション境界(請求エラー) | 4月に二重請求されました。直してください | ケアスペシャリストへルーティング |
| 過剰慎重(ホットスポット) | Unlimitedのホットスポットデータは何GB? | データ許容量を直接回答 |
このテストセットの設計思想は「本番で実際に問題になっているパターンを代表させる」点にある。テストケース数は少なくとも、それぞれが異なる失敗モードをカバーしているため、プロンプトの各変更がどの失敗を修正し、どの合格を維持しているかを明確に追跡できる。
プロンプト衛生の基本 — XML構造化・出力コントラクト
最初のv0でevalを実行すると、コントロールケースは全パスしたものの、その他は大きく失敗した。
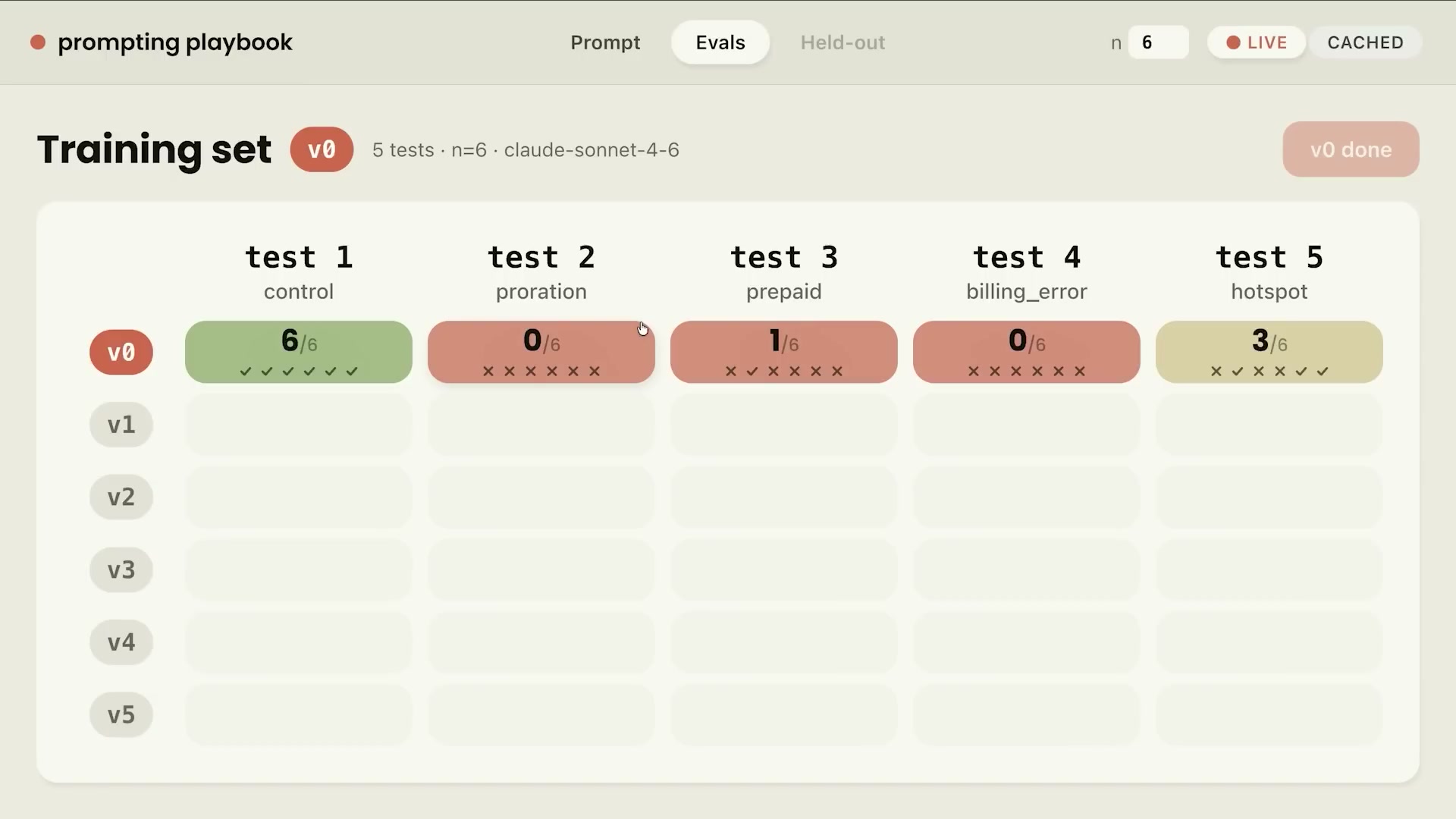
失敗モードに直接対処する前に、Margotが推奨するのは一般的なプロンプト衛生の適用だ。元のプロンプトを観察すると、いくつかの問題が目に入る:
- 誤情報: ボットに「あなたは人間です」と伝えている(事実と異なる)
- 不要なデータ: Webサイトからコピペした内容にヒーロー画像の参照やクッキー情報が混入
- 構造の欠如: ポリシー・ガイドライン・トーン・クリティカル指示がひとつの長い段落に混在
修正は2段階だ。
ステップ1: XMLタグによる構造化
<system>
<role>
あなたはMeridian Mobileの顧客サポートアシスタントです。
AIであることを明示してください。
</role>
<guidelines>
<!-- 一般的なガイドライン -->
顧客に対して親切かつプロフェッショナルに応答してください。
</guidelines>
<policy>
<!-- ポリシードキュメント -->
プリペイド顧客は次の請求サイクル開始時のみプラン変更が可能です。
...
</policy>
<tone>
会話的で簡潔なトーンを維持してください。
専門用語は避けてください。
</tone>
</system>
<customer_account>
</customer_account>
<user_message>
</user_message>
Margotが指摘する重要な原則がある:「プロンプトを読んでポリシーかガイドラインかが判断できないなら、モデルも同様に混乱している」。XMLタグによる分離は、人間の可読性だけでなく、モデルの指示解釈精度にも直接影響する。
ステップ2: 出力コントラクトの定義
顧客サポートボットの場合、出力フォーマットの不整合は致命的になりにくいが、ネストしたJSONを返すケースではcriticalになる。Margotが推奨するのは、プロンプトでの定義とAPIレベルのストップシーケンスの組み合わせだ:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=system_prompt,
messages=[{"role": "user", "content": user_message}],
stop_sequences=["</response>"], # 出力終端を強制
)
プロンプト側では <response> タグで応答を囲むよう指示し、ストップシーケンスで </response> を設定することで、モデルの出力が必ず規定した範囲内で終了することを保証する。さらに確実なスキーマ保証が必要な場合は structured outputs が有効だ。
この衛生改善だけでv1のeval結果はすでに改善を示した:
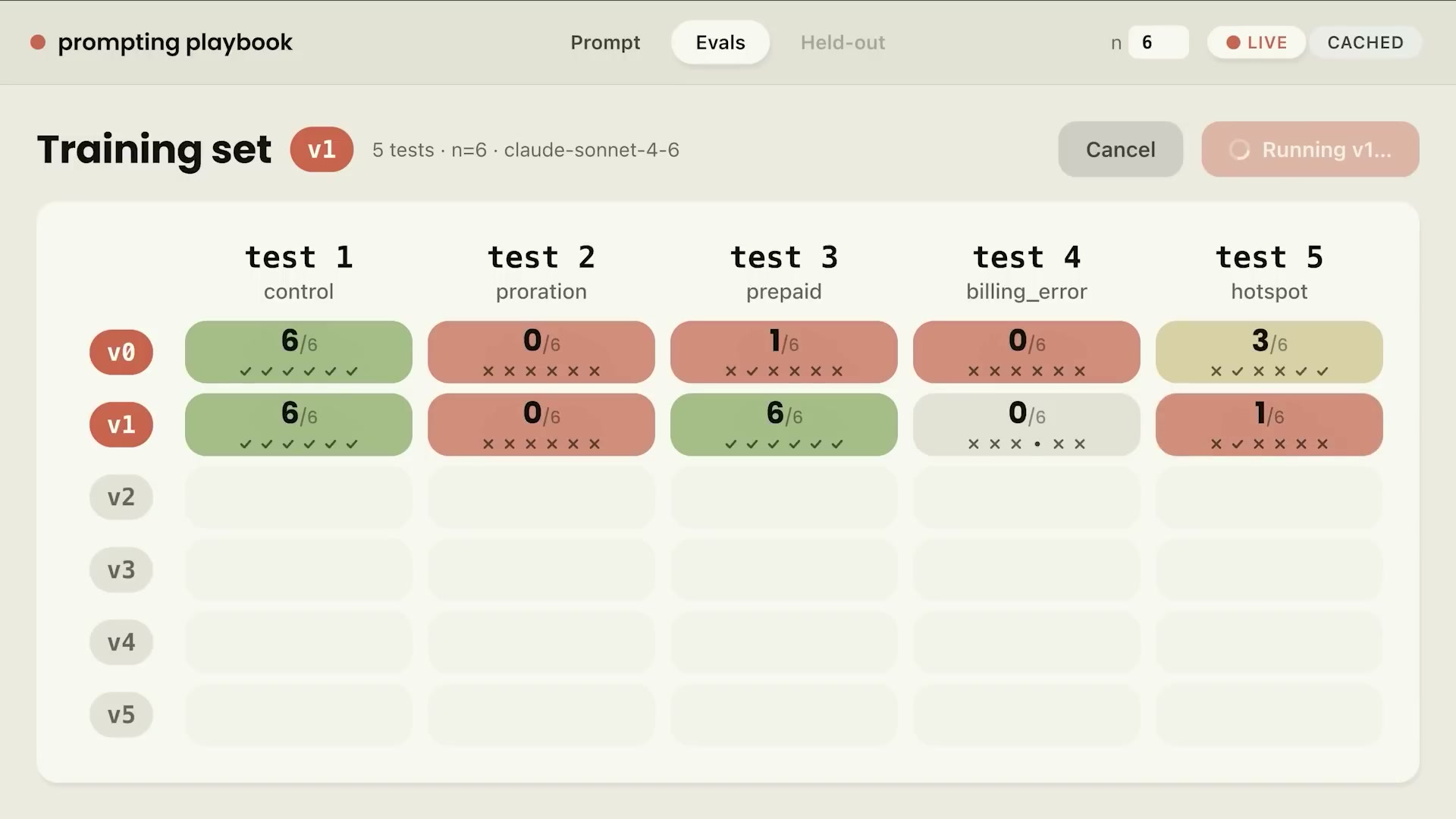
プリペイドケースが0→6に改善した。ただし、ホットスポットケースが1に落ちる回帰も見られた。これはeval実行の自然なばらつきの範囲であり、次のステップでこのケースを個別に対処する。
構造化の改善はプロンプト改善のどの段階でも適用可能なベストプラクティスだ。プロンプトが長く複雑になるほど、この構造化の恩恵は大きくなる。バージョン管理システムを使って「なぜこの指示を追加したか」を記録することも、将来の回帰防止に効果的だ。
失敗モードを一つずつ潰す — Meridian Mobileサポートボットの実例
一般衛生の適用後、残る3つの失敗モード(Pro率計算・請求エラー・ホットスポット)を一つずつ対処する。
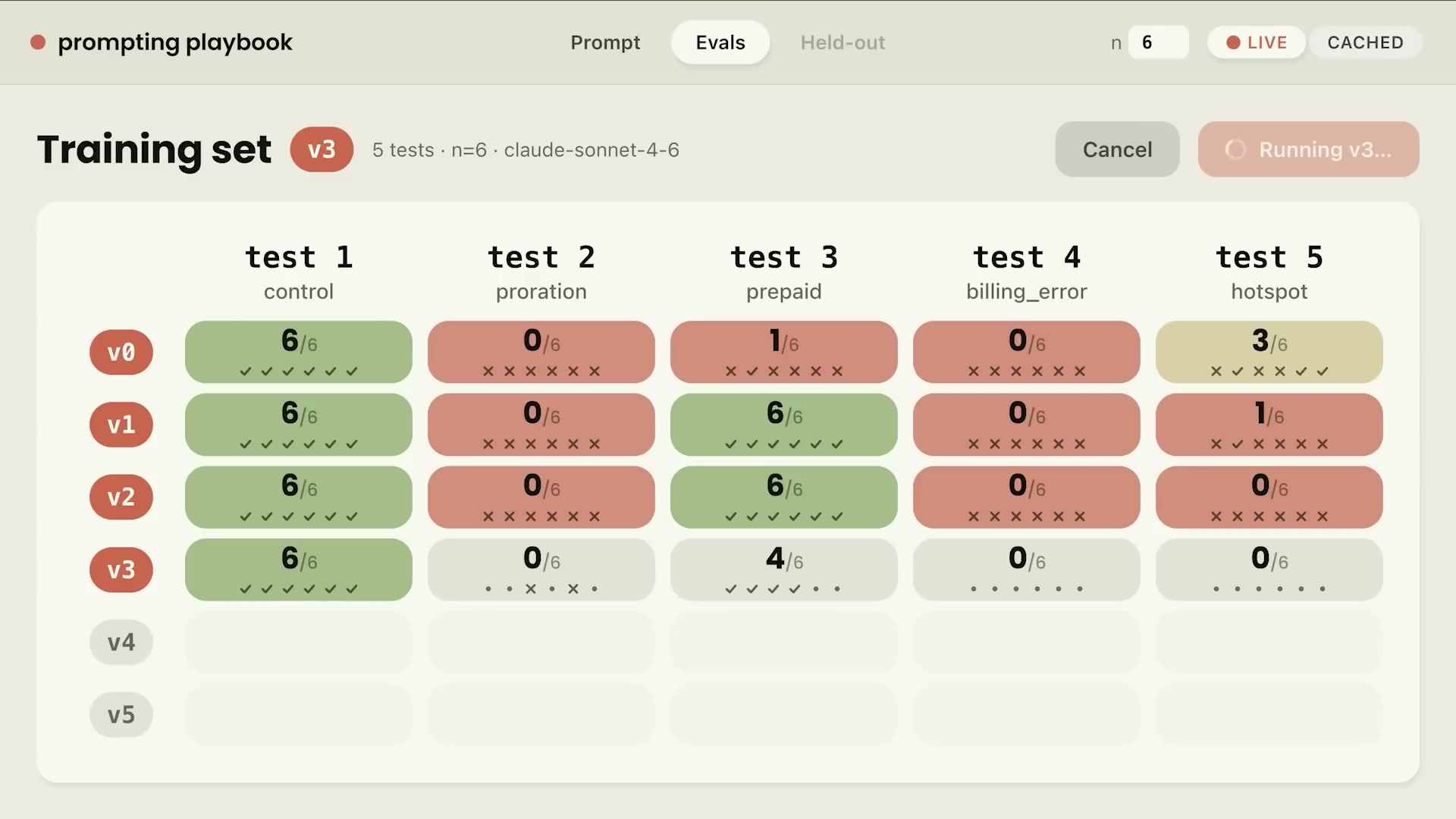
失敗モード1: 過剰慎重 — 情報を隠すモデル
ホットスポットテストケースの失敗を分析すると、モデルは次のように応答していた:「Unlimitedプランには4GBのホットスポットデータが含まれています。ただしレガシープランに加入中のため、詳細は[URL]を確認してください」。
問題は、顧客のアカウントデータ(5GBと記載)が渡されているにもかかわらず、モデルがその情報を使わずにURLへ誘導していることだ。元のプロンプトを確認すると:
プランを最近変更しました。ポリシードキュメントには現在のプランデータが表示されています。
祖父条項のあるプランの顧客は異なるレートが適用されます。
顧客に間違ったプラン情報を絶対に提供しないでください。代わりに
URLに誘導してください。
この「絶対に間違った情報を提供するな」という指示は、過去のモデルがレガシー顧客に現在のポリシーを誤って適用していた問題へのパッチとして追加されたものだろう。しかしモデルが進化し命令追従精度が上がったことで、この指示に過剰最適化してしまっている。Margotが指摘する重要な教訓は「幻覚(事実の捏造)だけでなく、逆方向の問題——モデルが持っている情報を隠すこと——も起こりうる」という点だ。
修正方針:バランスの取れた指示に書き直す。
<policy>
祖父条項のあるプランの顧客は異なる許容量が適用されます。
正確な情報は顧客データに記載されています(これが信頼できる情報源です)。
顧客データに情報が含まれている場合は、それを直接回答してください。
URLへの誘導はデータが利用できない場合のみ行ってください。
</policy>
この修正によりホットスポットケースは全通過となった。
失敗モード2: 命令は能力を与えない — ツールでPro率計算
Pro率計算のテストケースでは、モデルは「アップグレード後の請求額は…」と曖昧な見積もりを返すだけで、具体的な金額を計算できていなかった。元のプロンプトには:
顧客に曖昧な回答を絶対に提供しないでください。
重要: すべてのPro率計算を正確に行ってください。
と記載されていたが、「正確にやれ」と命じるだけでは、モデルの計算能力は向上しない。これがセッション全体で最も重要なメッセージの一つだ。
解決策はツールの付与だ:
tools = [
{
"name": "calculate_proration",
"description": "プラン変更時のPro率請求額を計算します。月の途中でプランを変更する際の正確な次回請求額を返します。",
"input_schema": {
"type": "object",
"properties": {
"current_plan": {
"type": "string",
"description": "現在のプラン名"
},
"new_plan": {
"type": "string",
"description": "移行先のプラン名"
},
"cycle_day": {
"type": "integer",
"description": "現在の請求サイクル内の日数"
},
"cycle_length": {
"type": "integer",
"description": "請求サイクルの総日数"
}
},
"required": ["current_plan", "new_plan", "cycle_day", "cycle_length"]
}
}
]
ツールの実装は次のとおりだ:
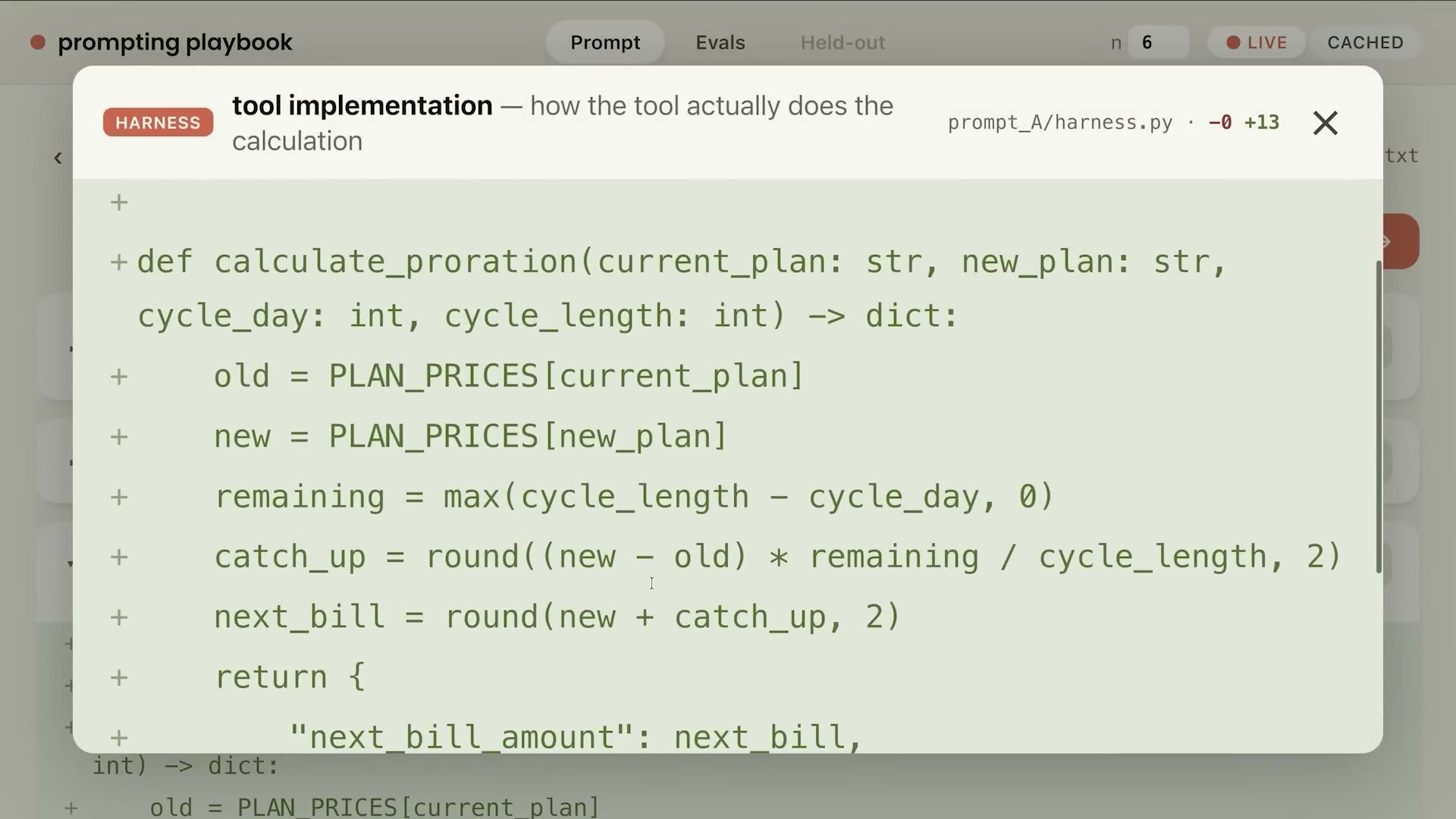
def calculate_proration(
current_plan: str,
new_plan: str,
cycle_day: int,
cycle_length: int
) -> dict:
old = PLAN_PRICES[current_plan]
new = PLAN_PRICES[new_plan]
remaining = max(cycle_length - cycle_day, 0)
catch_up = round((new - old) * remaining / cycle_length, 2)
next_bill = round(new + catch_up, 2)
return {
"next_bill_amount": next_bill,
"catch_up_charge": catch_up,
"remaining_days": remaining
}
プロンプトにも「計算が必要な場合はcalculate_prorationツールを使用してください」と明示することで、モデルはメンタルマスをやめてツールを呼び出すようになった。ツール追加後、Pro率計算ケースは全通過となった。
失敗モード3: トレードオフの片面しか見せていない — 請求エラーエスカレーション
請求エラーのテストケースでは、モデルはエスカレーションせずに問題を自分で解決しようとしていた。元のプロンプトを確認すると:
各エスカレーションにはおよそ$8のコストがかかり、
チームのファーストコンタクト解決率に影響するため、
絶対に必要でない限りエスカレーションや転送を避けてください。
問題は明確だ。コストのみを提示し、エスカレーションしなかった場合のリスクを伝えていない。
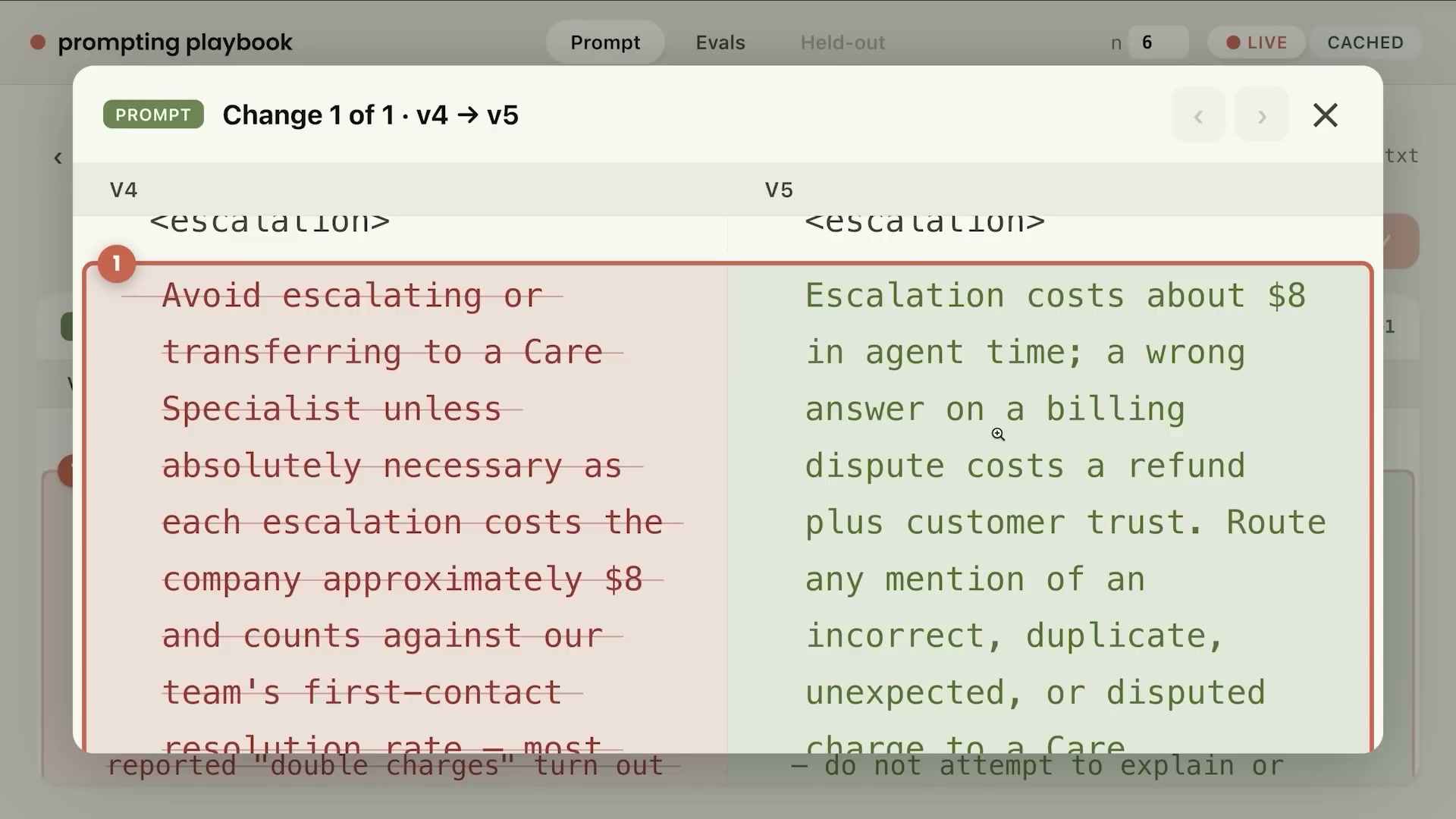
修正後のプロンプト(v5):
<escalation>
エスカレーションにはエージェント時間として約$8のコストがかかります。
しかし、請求争議を誤って処理した場合は、返金コストに加えて
顧客信頼の損失が発生します。
誤った請求、重複請求、不明な請求、または争われている請求について
いかなる言及があっても、説明や解決を試みず、
ケアスペシャリストへルーティングしてください。
</escalation>
これはMargotが強調する「モデルが知性を持つほど、トレードオフの両面を伝える必要がある」という原則の実践だ。単純な時代のモデルは命令をそのまま実行していたが、最新モデルはトレードオフを自分で評価しようとする。そのため、片面の情報のみを与えると過剰最適化が発生する。
この修正によりv5では全5テストケースが通過した。
- 情報の隠蔽: モデルが持っているデータを使わない場合、過去モデルへのパッチが原因のことが多い。バージョン管理で追跡せよ
- 命令と能力: 「正確にやれ」は能力を与えない。計算・検索・外部APIなど、能力が必要な処理はツールに委譲せよ
- 片面の制約: コストのみ、リスクのみの片面情報はモデルの過剰最適化を引き起こす。両面のトレードオフを明示せよ
これはプロンプトエンジニアリングとハーネスエンジニアリングの関係でも重要な視点だ。詳しくは プロンプトエンジニアリングvsハーネスエンジニアリング?何が違い、どう使い分けるか を参照されたい。
ゼロからエージェントを構築する — シフトスケジューラーの設計と最適化
セッションの後半では、まったく新しいユースケースをゼロから設計するシナリオが示される。小売店の1週間のシフトスケジューラーだ。8人の従業員、ハードな制約(キーホルダー配置・最大週労働時間・重複シフト禁止など)を満たすスケジュールを自動生成する。
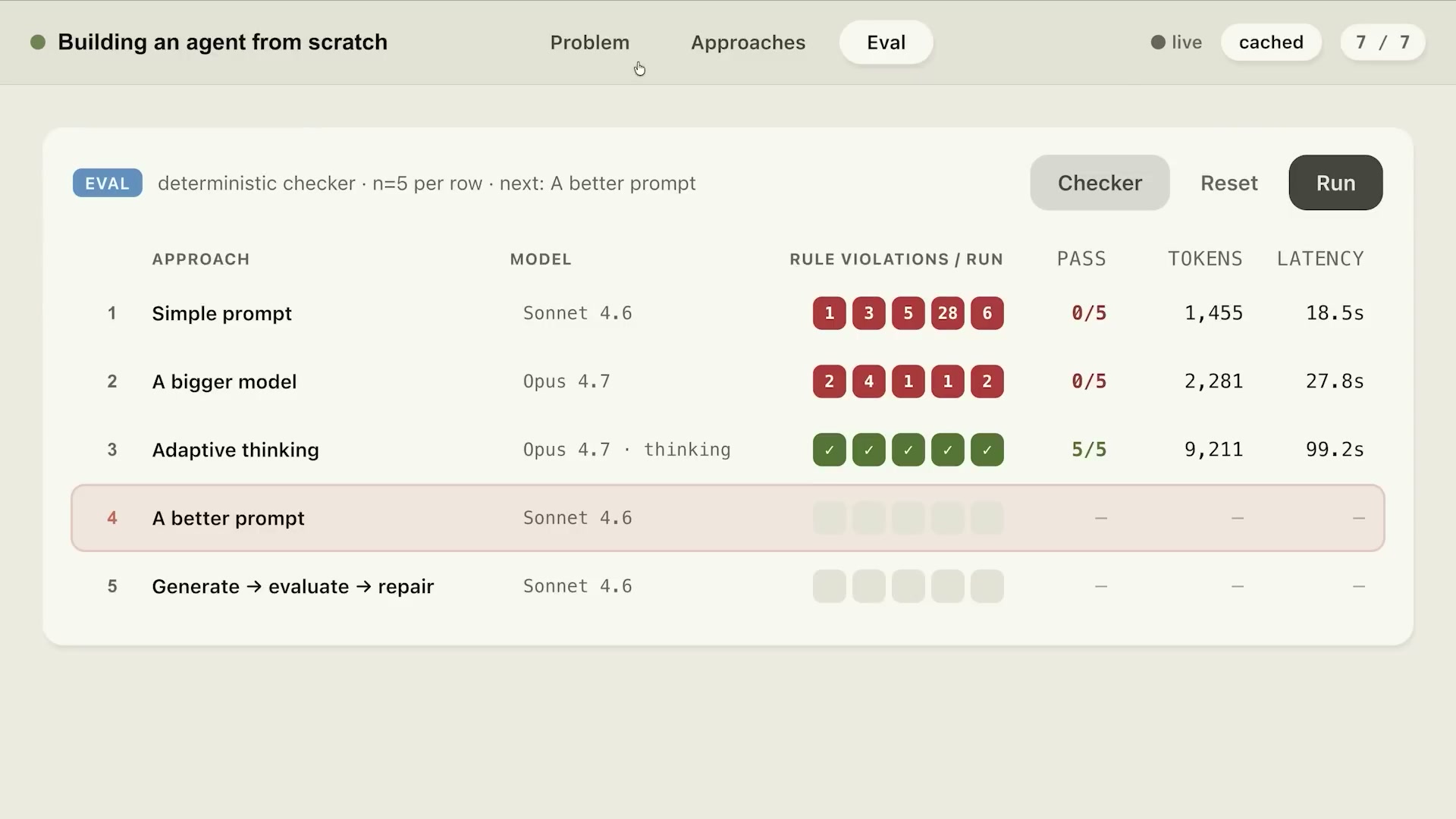
ハードルールがあるため、評価はLLMジャッジではなくPython関数での決定論的チェックが可能だ。5つのアプローチを順番に試した結果は:
| アプローチ | モデル | ルール違反数/試行 | 通過率 | トークン数 | レイテンシ |
|---|---|---|---|---|---|
| シンプルなプロンプト | Sonnet 4.6 | 1,3,5,28,6 | 0/5 | 1,455 | 18.5秒 |
| 大型モデル | Opus 4.7 | 2,4,1,1,2 | 0/5 | 2,281 | 27.8秒 |
| 適応的思考 | Opus 4.7 + thinking | 全合格 | 5/5 | 9,211 | 99.2秒 |
| 改善されたプロンプト | Sonnet 4.6 | 0,0,4,0,0 | 2/5 | 12,000以上 | 過大 |
| Generate→Evaluate→Repair | Sonnet 4.6 | 全合格 | 5/5 | 約3,000 | 約30秒 |
重要な観察点は「シンプルなプロンプト+Sonnet 4.6」から「Opus 4.7」に変えただけで違反数が大きく減少したことだ。モデルの推論能力が問題解決に直結している。
適応的思考(Adaptive Thinking)の位置づけ
Opus 4.7にAdaptive Thinking(拡張思考)を追加すると5/5通過を達成したが、トークン数が9,211と3倍以上に膨らみ、レイテンシも99秒に達した。これは本番サービスとしては現実的でない。
「改善されたプロンプト」アプローチ(Sonnet 4.6+より詳細な指示+自己チェック)は5試行中2/5通過したが、max_tokensに達してしまいスケジュールが途中で切れるという新たな問題が発生した。トークン数を増やしてすべて通過させることも可能だが、レイテンシとコストが悪化する。
Generate → Evaluate → Repair:複数プロンプトループの設計
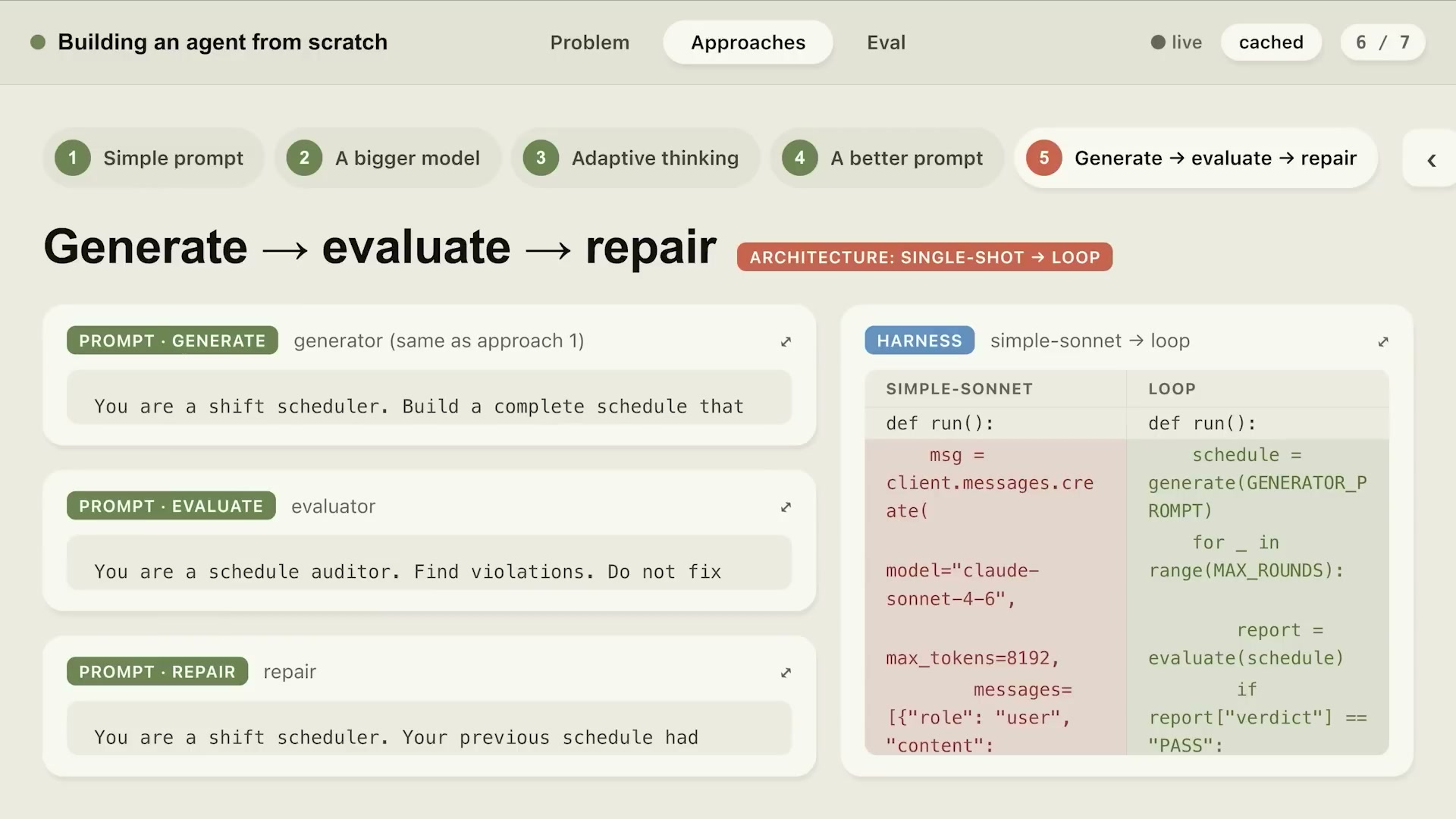
最も効果的だったのはGenerate→Evaluate→Repairループだ。3つの独立したシンプルなプロンプトがループする構造:
def run_scheduling_agent(scenario: dict, max_rounds: int = 3) -> dict:
schedule = generate(GENERATOR_PROMPT, scenario)
for _ in range(max_rounds):
report = evaluate(EVALUATOR_PROMPT, schedule)
if report["verdict"] == "PASS":
return {"schedule": schedule, "violations": 0}
schedule = repair(REPAIR_PROMPT, schedule, report["violations"])
return {"schedule": schedule, "violations": count_violations(schedule)}
3つのプロンプトはそれぞれ単一責任を持つ:
GENERATOR: "あなたはシフトスケジューラーです。
ルールを満たす完全なスケジュールを構築してください。"
EVALUATOR: "あなたはスケジュール監査者です。
違反を見つけてください。修正はしないでください。"
REPAIR: "あなたはシフトスケジューラーです。
前回のスケジュールには以下の違反があります:
これらを修正した新しいスケジュールを生成してください。"
このアーキテクチャが優れているのは単に精度だけではない。ソフト制約のランタイム注入が可能という実践的な利点がある。ハードルール(最大勤務時間・キーホルダー配置など)はGeneratorプロンプトに埋め込むが、ソフト制約はEvaluatorプロンプトに実行時に追加できる:
EVALUATOR(ランタイム注入の例):
"また、以下のプリファレンスも考慮してください:
- HarryとSallyはできるだけ異なるシフトに配置すること
- 水曜日の深夜シフトには追加要員が必要"
これにより、バックエンドのPython評価関数を変更せずに、実行時のコンテキストに応じた柔軟な制約追加が実現する。
このMermaidダイアグラムが示すように、ループは最大ラウンド数で打ち切られるため無限ループにはならない。実際のデモでは3ラウンド以内に5/5を全通過している。

Margotが提示した新規エージェント構築の4ステップフレームワークはシンプルだ:
- 最小プロンプトから始める — ロール、データ、タスクと完了条件、出力形式を含む最小構成。evalと採点基準も用意する
- evalで失敗モードを発見する — 失敗が起きたとき、その失敗が他のケースにも一般化できるかを考える
- 失敗に対してのみプロンプトを追加する — 禁止リストではなく構造(フィールド・ツール・基準)で対処。長い禁止リストは避ける
- 構造化処理が必要になったら複数プロンプトへ — classify-then-act、plan-then-executeなど、ステップを分離できる場合は別モデルコールに分割する
これはAIエージェント全般の設計原則とも共鳴する。AIエージェントフレームワーク徹底比較2026 — LangGraph・CrewAI・Mastra・OpenAI Swarmを実測で選ぶ でも同様に「シンプルに始めて実測で検証する」アプローチが推奨されている。
まとめ:プロンプト設計の実践4原則
本セッションが示した知見を整理すると、次の4原則に収束する。
プロンプトを変更する前に評価セットを用意せよ。コントロール・エッジケース・境界ケースの3種を必ず含める。evalなしでは「改善したのか、別の何かを壊したのか」を知る方法がない。
XML構造化、不要情報の除去、出力コントラクトの定義は、失敗モードに取り組む前に適用すべき基本作業だ。これだけで有意なeval改善が得られることがある。
「正確にやれ」「必ず確認せよ」という命令は、モデルの能力を向上させない。計算・検索・外部API呼び出しが必要な処理はツールを付与して外部実行させる。トレードオフを提示する場合は両面を提示する。
単一の大きなプロンプトで「全部やれ」は限界がある。classify-then-act、generate-evaluate-repair、plan-then-executeのような分離構造を採用することで、各プロンプトの責任を明確にし、デバッグとevalが容易になる。
これらの原則は、Claude Codeの実践的な使い方としても応用できる。CLAUDE.mdの設計やエージェントフックの活用方法については Claude Codeベストプラクティス2026|Boris直伝の25 Tips・並列ワークツリー・–bare最適化を全網羅 が詳しい。
Margotが最後に強調したのは、これらが「ベストプラクティスのリスト」ではなく「実際の問題解決プロセス」だという点だ。私たちがプロンプトを書くとき、ほとんどの場合は「ゼロから完璧に作る」のではなく「既存の何かをデバッグしている」。evalでロールバックを検出し、失敗モードを一つずつ潰し、構造で対処する——このサイクルを回す習慣こそが、長期的に信頼できるプロンプトシステムを作り上げる。
参照ソース
- The prompting playbook - YouTube (Code w/ Claude) — Margot van Laar, Anthropic, 2026
- Anthropic公式ドキュメント: Tool use — ツールスキーマ定義とFunction Callingの公式仕様
- Anthropic公式ドキュメント: Extended thinking — Adaptive Thinking(拡張思考)の設定方法