Code with Claude Londonイベントで公開されたAnthropicのワークショップが、エージェント設計者の間で注目を集めている。スピーカーはWill Steuk(AnthropicのMember of Technical Staff、Applied AIチーム所属)。テーマは「ツール・スキル・サブエージェントのどれを使うべきか」、副題は「プロンプトを超えて成長したエージェントの解体」だ。
45分間のセッションは座学でなくライブコーディング形式で進行した。400行に膨れ上がったシステムプロンプトと12個のツールを抱えた架空の在庫管理エージェント「StockPilot」を題材に、evalスイートで問題を定量化しながら設計を段階的に改善していく。最終的にevalスコアは63-75%から92%へ、トークン使用量は28分の1へ、実行コストは30分の1へと改善する。
Claude Code全体のアーキテクチャと設計原則は Claude Code完全ガイド2026:インストールから本番運用まで も参照されたい。
StockPilot——「正しく作られた」エージェントがなぜ崩壊するか

StockPilotは中規模小売業者向けの在庫管理エージェントとして設計された。その機能を列挙すれば印象的だ——在庫の低水準検知、需要予測、サプライヤー選定、発注書の作成、従業員向け週次レポートの生成。いずれも単体では複雑でない機能だ。
問題は設計の問題でなく、成長の問題だった。
エージェントは正常に動作していた。しかしビジネス要件が増えるたびに機能が追加された。最初は需要予測のサブエージェントが加わった。次にレポート生成のサブエージェントが追加された。その都度、システムプロンプトには新しいポリシーや手順が追記された。この繰り返しが続いた結果として、エージェントの構成は以下のようになった。

- システムプロンプト: 約400行
- ツール数: 12個(うち3つはサブエージェントへの薄いラッパー)
- サブエージェント: forecasting、procurement、writing の3種
- 全ての実行結果: オーケストレーターのコンテキストに生データでダンプされる
Will Steukはこのアーキテクチャを「2025年初期の正しい設計」と評した。当時の判断は防御可能だった。ツールを追加し、サブエージェントを追加し、ポリシーをシステムプロンプトに書いた——それぞれの決断には理由があった。しかし積み重なった複雑性が、本来なら正しく動くはずの処理を壊すようになった。
12タスク・5グレーダーのevalで設計の問題を可視化する
Will Steukはこの問題にアプローチする前に、まずevalスイートを走らせて現状を数値化した。ヒルクライミングは定量的な基準なしには進められない。

evalは12タスクで構成され、5種類のグレーダーが使い分けられる。
| グレーダー種別 | 用途 | 例 |
|---|---|---|
| exact_match | 単純な値の完全一致 | 在庫数の読み取り(R1) |
| set_match | リストの集合一致 | 発注点以下のSKUリスト(R2) |
| numeric_tolerance | 許容誤差範囲内の数値 | 14日予測、プロモ月予測(R6-R8) |
| llm_judge | LLMによる非決定論的評価 | 週次レポートの構造と文体(R9) |
| composite | 複数条件の組み合わせ | 日次低在庫スイープの正確さ×速度×上位3件精度(F1) |
タスクIDは「R(Regression)」と「F(Failure Mode)」の2種に分かれる。Rタスクはシングルターンの基本能力テスト。Fタスクはより複雑なマルチターンの故障モードシミュレーションだ。
Willがベースラインを取得するために使ったコマンドはシンプルだ。
# Messages APIバージョンでevalを実行
uv run evals --agent before
# Claude Managed Agentsバージョンをデプロイ
uv run deploy starter
# 特定タスクのみ実行(反復サイクルを速くする)
uv run evals --task F1
uv run evals --task F2,R7
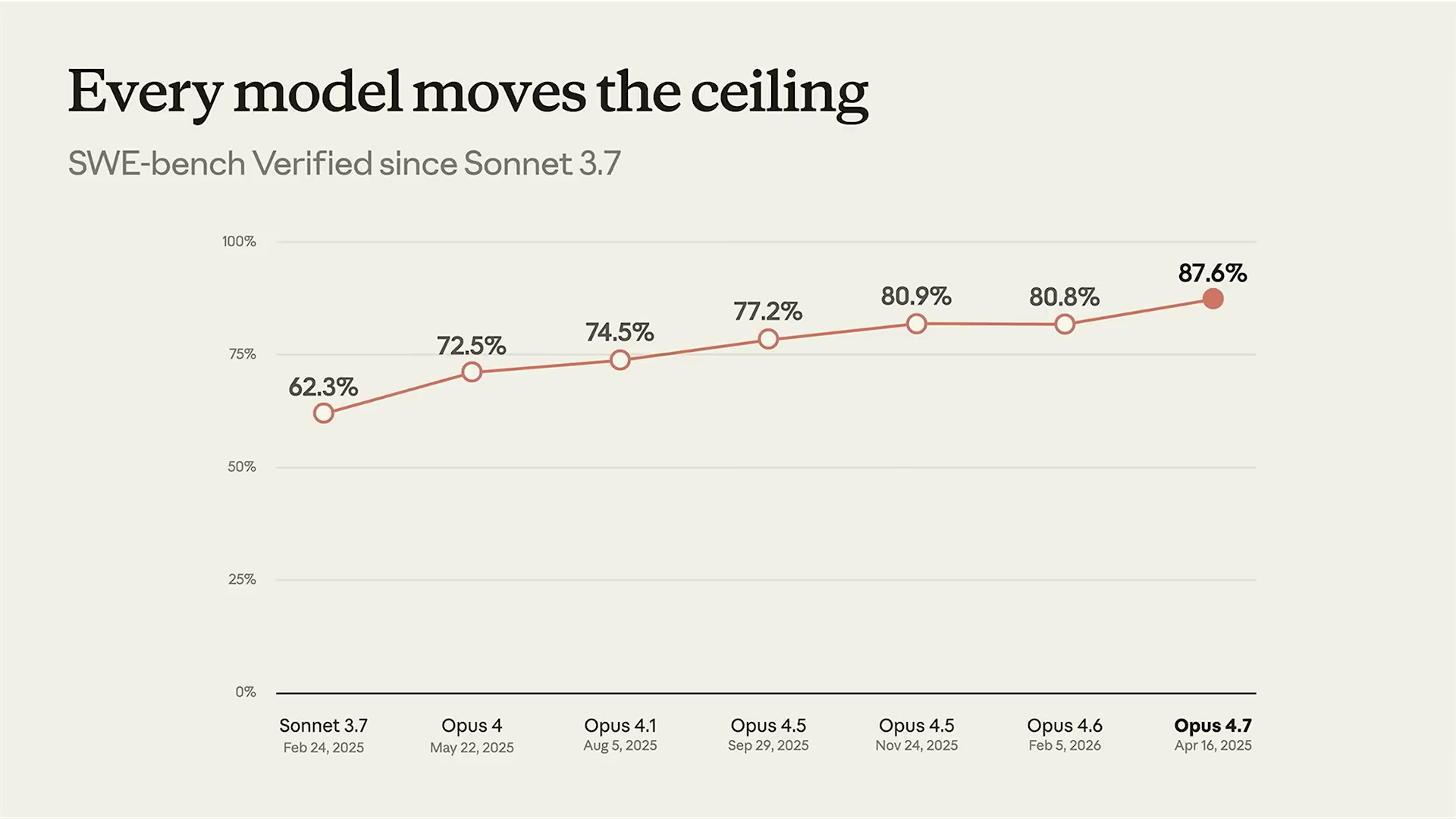
最初のeval実行結果は62%(12タスク中7タスク合格)だった。公称スペックの83%よりも悪い数値だ。製造業の現場では17%の失敗率は許容できない品質水準ではない。
Claude Codeで根因分析——3つの構造的問題
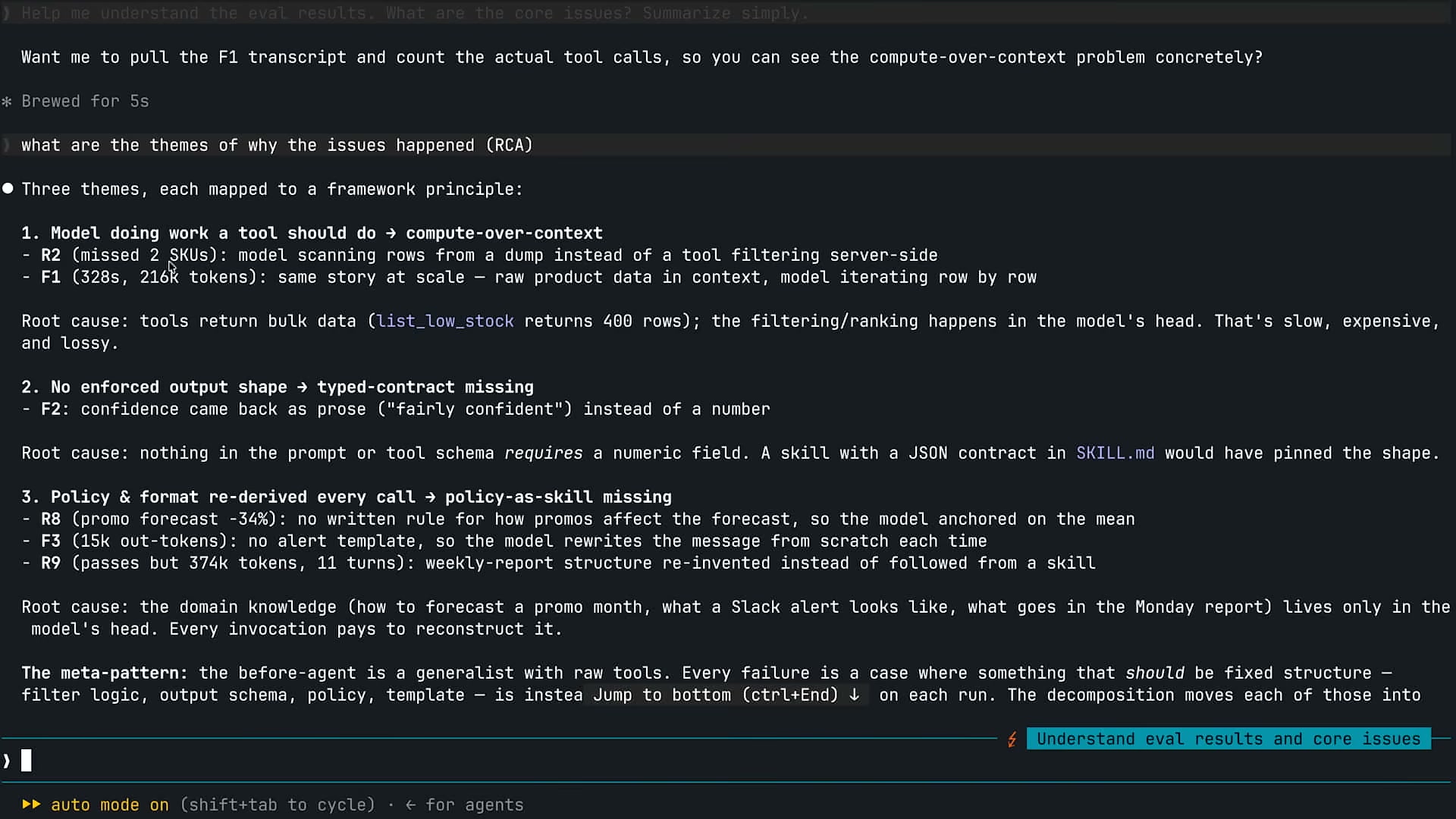
Will SteukはClaude Code(モデル: Opus 4.7、effortレベル: extra high)を使ってevalの失敗を分析させた。Claudeは12のeval失敗を3つのテーマに整理した。
1. compute-over-context(ツールが担うべき処理をモデルが担っている)
list_low_stockツールが400行分のCSVデータをコンテキストに丸ごとダンプしていた。モデルはその全データを「脳内」で走査して在庫低下品目を特定しようとする。これは遅く、トークンを大量消費し、精度も落ちる。本来ならツール側でフィルタリングしてtop-N件だけを返せばよい。
R1(在庫参照)で216,365トークンを消費した原因がここにある。
2. typed-contract missing(出力スキーマが定義されていない)
F2(プロモーション注文)のサブエージェントは数値の確信度を「fairly confident」という散文で返していた。オーケストレーターはその散文から数値を抽出しようとして失敗する。SKILL.mdにJSONスキーマが定義されていれば、サブエージェントは型付きのJSONを返す。
3. policy-as-skill missing(ポリシーがシステムプロンプトに埋もれている)
R8(プロモーション月の予測)で予測乗数が3.1倍のはずが1.35倍で計算された。原因はシステムプロンプトの異なる箇所に矛盾する方針が存在していたこと。プロモーション予測のルールをスキルとして切り出し、モデルが確実に参照できる形にする必要があった。
12-Factor Agentsの設計原則でも同様の指摘がある——エージェントが「記憶」すべき知識とオーケストレーターの「行動指針」は分離すべきだ。詳しくは 12-Factor Agents完全解説:本番投入できるLLMエージェント設計12原則 も参照されたい。
修正サイクル1——スキルでシステムプロンプトを解体する
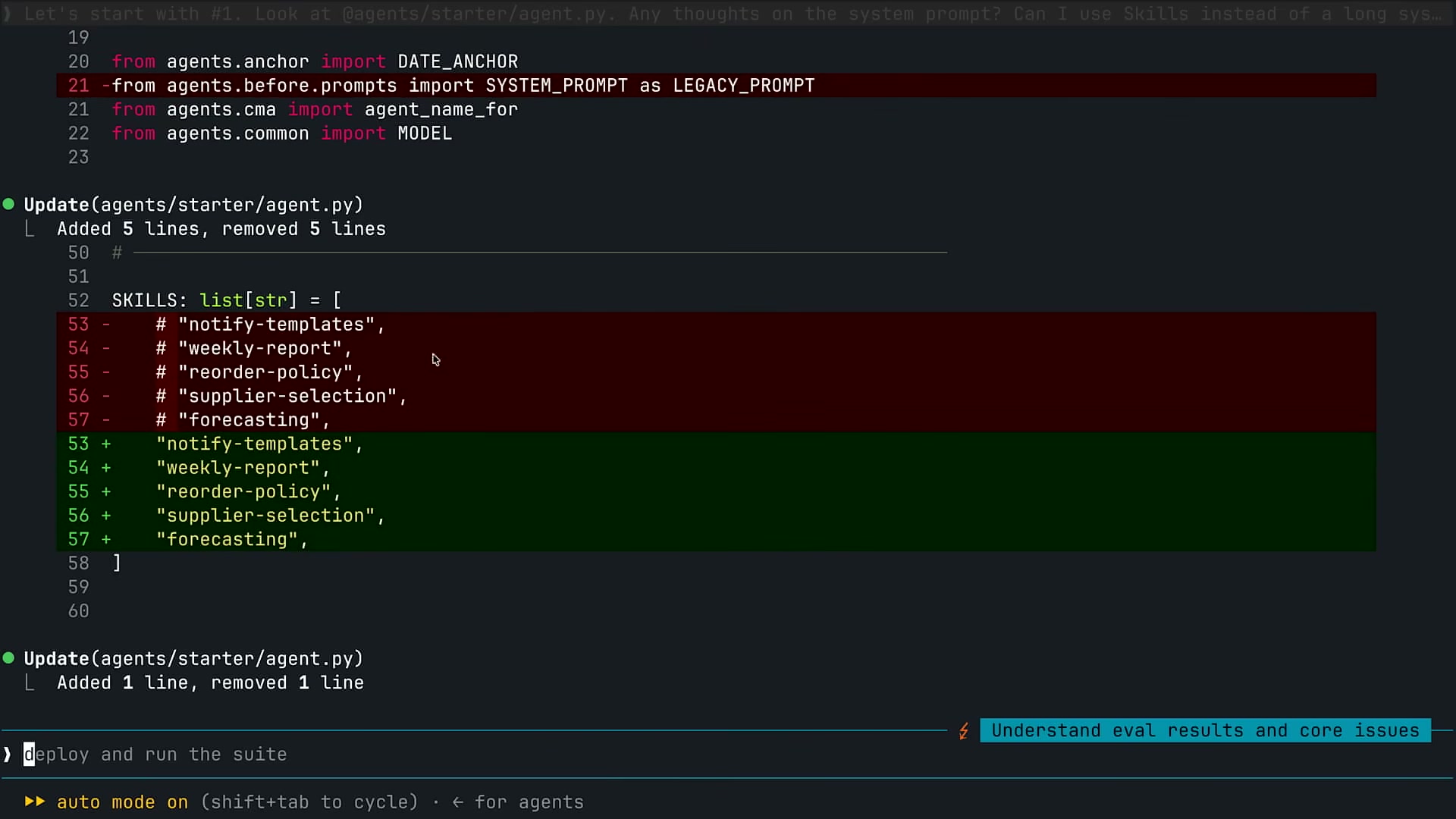
最初の修正サイクルはシステムプロンプトの解体だ。Claude Codeに「このシステムプロンプトを見てほしい。スキルで置き換えられるか?」と尋ねると、Claudeは既存のスキルファイル群を認識し、コードを修正した。
# agent.py の SKILLS リスト(コメントアウトを解除するだけ)
SKILLS: list[str] = [
"notify-templates",
"weekly-report",
"reorder-policy",
"supplier-selection",
"forecasting",
]
変更の核心は次の2点だ。
- システムプロンプトを約400行から15行に圧縮する
- ポリシー・手順・フォーマット定義をスキルファイル(SKILL.md)に移す
スキルは「Claudeが必要なときだけコンテキストに読み込む、パッケージ化された情報」だ。需要予測のタスクが来るまで、フォーキャスティングスキルはコンテキストウィンドウを汚染しない。必要になった瞬間にClaudeがスキルを参照し、そこに書かれたポリシーとOutput contractに従って処理する。 システムプロンプトは「Claudeが常に必要とする情報」だけに限定する。タスク依存の情報はスキルに切り出す。これがProgressive Disclosureだ。
スキルの有効性についてはAnthropicの公式エンジニアThariqが詳しく解説している。 ClaudeチームThariqが明かしたSkills設計9カテゴリ によれば、スキルは「システムプロンプトに全てを書く」アプローチで生じるコンテキスト汚染を防ぐ最も有効な手段のひとつだ。
スキルファイルの構造——Output contractが品質を決める
スキルが単なる情報ではなく「型付き契約」として機能するのは、JSONスキーマが明示されているからだ。F2のサブエージェントが散文で数値を返していた問題はここに根本がある。
良いスキルファイルには以下の要素が含まれる。
# forecasting
## When to invoke
フォーカス月の需要予測を依頼されたとき。通常のreorder calculationには使わない。
## Output contract(必須)
返答はJSONのみ。散文禁止。
{
"forecast_qty": integer,
"confidence": 0.0-1.0,
"method": "baseline" | "promo-adjusted" | "forecaster-agent",
"flags": []
}
## Path A: 通常月
baseline × seasonal_multiplierをbashで計算し、上記JSONで返す。
## Path B: プロモーション月
callable_agentのforecasterに委譲する。
forecasterは独立したコンテキストで計算を実行し、strictなJSONを返す。
Output contractを明示することで、サブエージェントが「fairly confident」のような散文を返すことはなくなる。オーケストレーターは型付きのJSONから直接数値を読み取れる。
修正サイクル2——12ツールを3つのプリミティブに替える
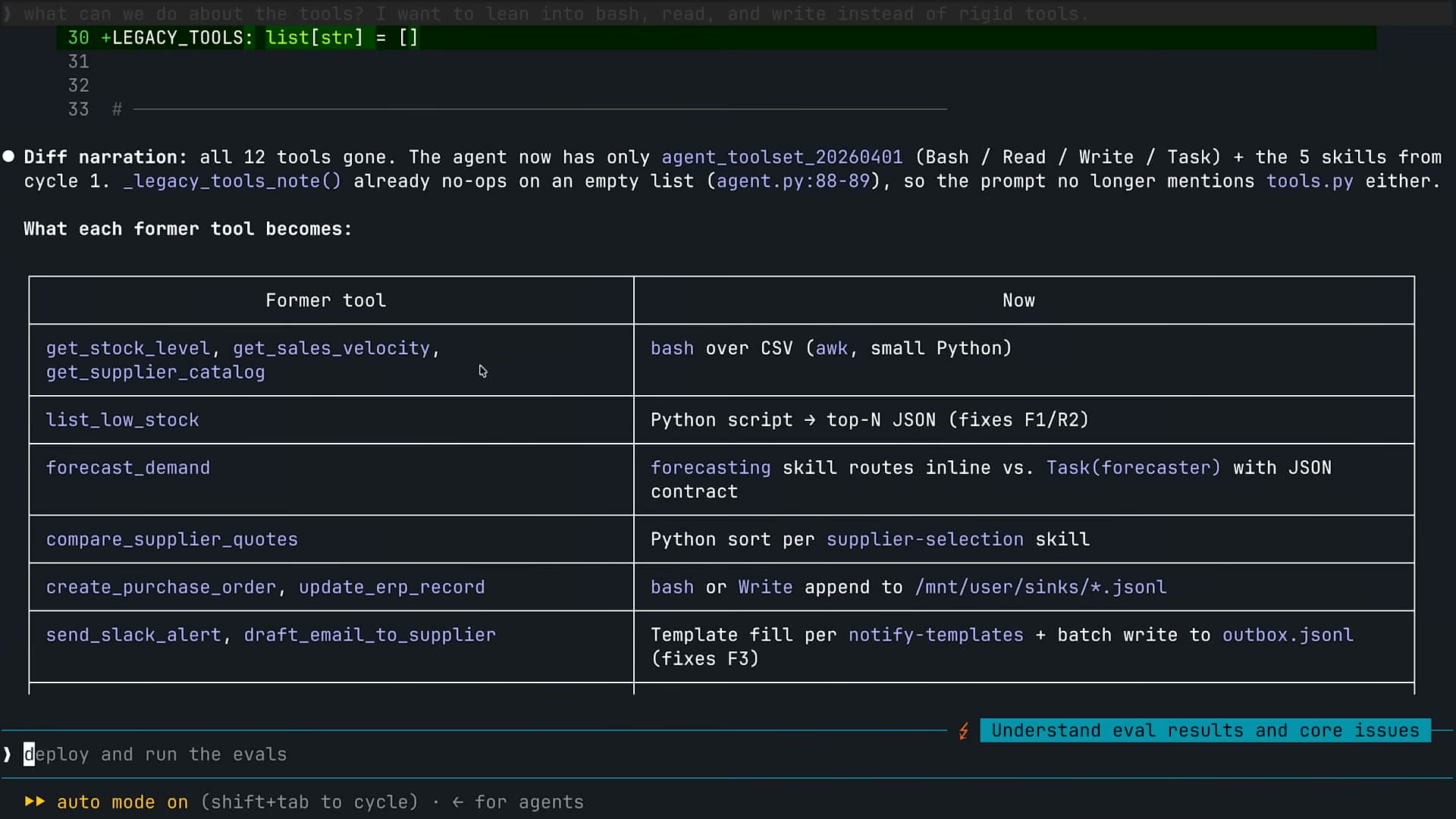
2つ目の修正サイクルはツールの整理だ。Claude Codeに「ツールを分析して最適化できるか?」と問うと、Claudeは12ツール全体の削除を提案し、agent_toolset(Bash + Read + Write)への置き換えを実行した。
# before: 12個の専用ツール
LEGACY_TOOLS: list[str] = [
"get_stock_level",
"list_low_stock",
"forecast_demand",
"get_sales_velocity",
"compare_supplier_quotes",
"get_supplier_catalog",
"create_purchase_order",
"update_erp_record",
"send_slack_alert",
"draft_email_to_supplier",
"generate_weekly_report",
"search_web_for_disruptions",
]
# after: LEGACY_TOOLS をクリア、agent_toolset を使用
LEGACY_TOOLS: list[str] = []
各ツールがどのプリミティブに置き換えられたかを以下に示す。
| 旧ツール | 新実装 |
|---|---|
| get_stock_level, get_sales_velocity, get_supplier_catalog | bashでCSVを直接読み込み(awk, 小Pythonスクリプト) |
| list_low_stock | Pythonスクリプト → top-N件のJSONを出力 |
| forecast_demand | forecastingスキルがルーティング(inline or Task) |
| compare_supplier_quotes | Pythonソートをsupplier-selectionスキルで実行 |
| create_purchase_order, update_erp_record | BashまたはWriteで/mnt/user/sinks/*.jsonlに追記 |
| send_slack_alert, draft_email_to_supplier | notify-templatesスキルに従いbatchでoutbox.jsonlに書き出し |
カスタムツールは「CSVを読み込んで返す」という薄い処理しかしていないことが多い。代わりにBashを与えると、Claudeは読み込みと同時にフィルタリング・集計・上位N件への絞り込みまで行い、コンテキストに載るデータ量が激減する。216,000トークン → 7,628トークンはこの変更が主因だ。
Will Steukはツール選択の原則をこう整理した。
- まずClaude Codeのプリミティブ(Bash、Read、Write、web search)から始める
- 必要なカスタムツールだけ追加する(プリミティブで賄えないもののみ)
- MCPはラスト・リゾート——複数のエージェント・クライアントが共通ツールにアクセスする場合のみ
修正サイクル3——サブエージェントの適切な使い時
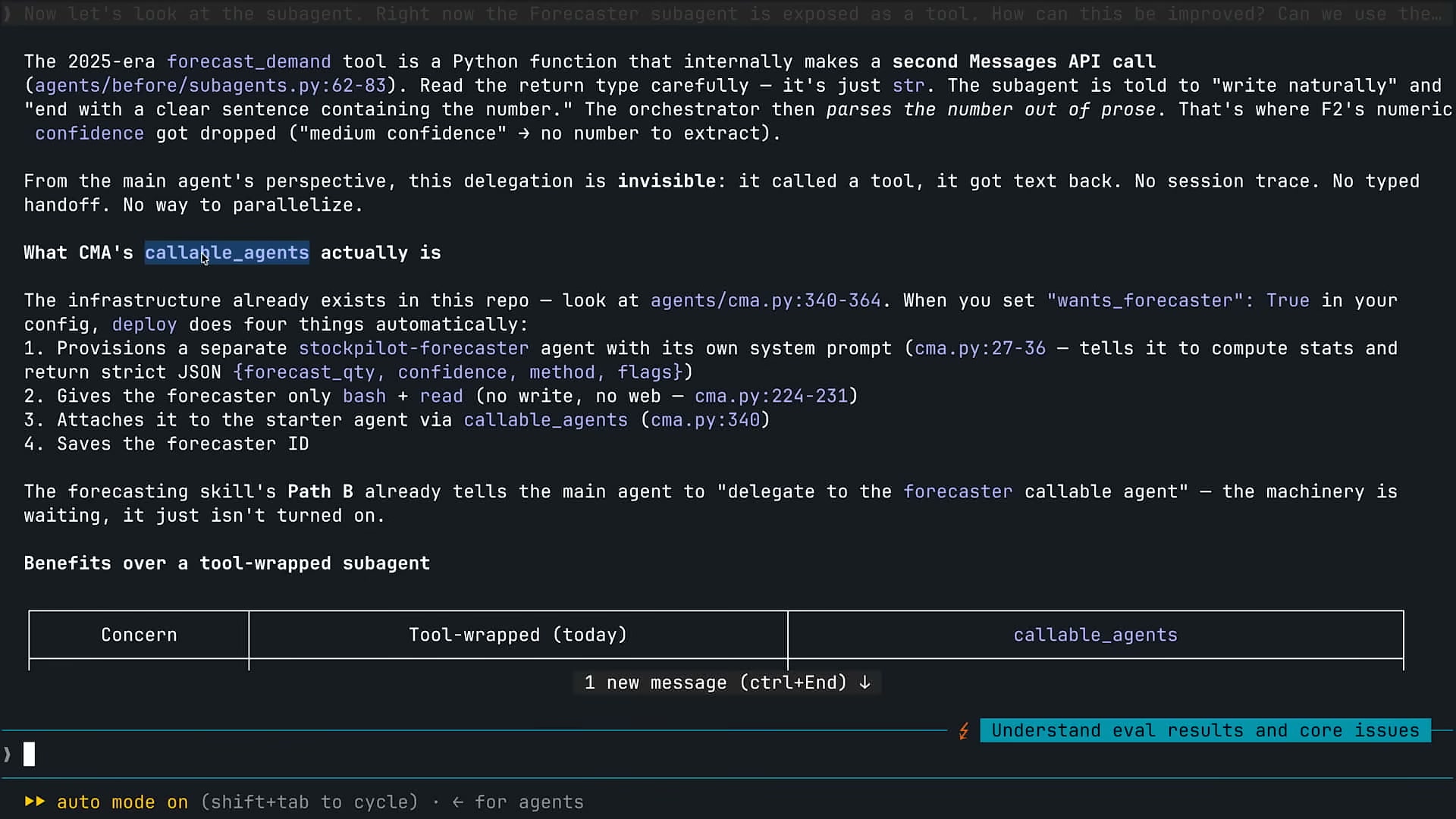
3つ目の修正サイクルはサブエージェントの再設計だ。元のStockPilotにはforecasting・procurement・writingの3つのサブエージェントがあった。修正後は全てを削除し、forecastingだけを保持した。
サブエージェントが正当化される2つのケース
Will SteukはAnthropicの内部ガイドラインとして2つの判断基準を示した。
① 多数のClaudeを問題に投入したいとき 並列処理が有効な問題——深いウェブリサーチ、大量のファイルの同時探索、独立したタスクの並列実行——ではサブエージェントが力を発揮する。Claude Codeのマルチエージェント機能はこの設計だ。
② コンテキスト汚染を防ぎたいとき コードを書いた同じインスタンスにレビューをさせるべきでない。フォーキャスティングの計算を、顧客との会話を保持しているインスタンスに任せるべきでない。独立したコンテキストで結果を出させ、オーケストレーターに戻すべき処理がある。
forecastingサブエージェントを保持した理由は②だ。「顧客と会話しているメインのClaudeのコンテキストが、予測計算を歪めてはいけない」という設計判断だ。
callable_agents vs ツールラッパー
従来のサブエージェントは「ツールとして定義した関数の内部でMessages APIを呼ぶ」という構造だった。この設計の問題は:
- オーケストレーターからはツールを呼んだだけに見える
- サブエージェントのセッション情報・ログが追跡しづらい
- 出力が散文で返ってくるとパースに失敗する
Claude Managed Agentsのcallable_agentsはこれを解決する。サブエージェントがCMAのマルチエージェントプリミティブとして登録され、オーケストレーターと同じ観測性でトレースできる。
Claude Managed Agentsが解決するもの

このワークショップでは、Messages APIで手書きしたエージェントループをClaude Managed Agents(CMA)に移行する作業も含まれている。CMAを使う理由を一言でいえば「インフラの心配をせずに、エージェント設計だけに集中するため」だ。
手書きのエージェントループで解決しなければならない問題を列挙すれば、その複雑さが分かる。
- エージェントループの状態管理
- ツール呼び出しと結果のハンドリング
- タイムアウト・エラーの回復
- セキュアなサンドボックス環境の提供
- 複数ユーザーへの同時スケーリング
- セッション情報・ログの収集と追跡
CMAはこれら全てを引き受ける。開発者はagent.pyでスキルのリストとツールの設定を記述するだけでよい。デプロイも一行だ。
Claudeが保有すべきハーネス設計の詳細については ハーネスエンジニアリング完全解説:Claude Codeソースから読む5層モデル・クエリループ・コンテキスト管理 でソースコードレベルから解説している。
ワークショップの3ステップ

ワークショップでは参加者が以下の3ステップを順に実施する。
Step 1: SHORT_PROMPTに切り替え、notify・weeklyスキルを有効化
→ uv run evals --task F3で改善を確認
Step 2: データダンプ型ツールを削除し、CMAをBashで設定
→ uv run evals --task F1で大幅なトークン削減を確認
Step 3: フォーキャスティングと効率化のためのサブエージェントを実装
→ uv run evals --task F2,R7で予測精度の改善を確認
各ステップの後に必ずevalを再実行し、改善が確認されてから次に進む。「修正→計測→改善」のサイクルが最も重要な実践だ。
最終アーキテクチャ——15行・5スキル・1つのcallable_agent
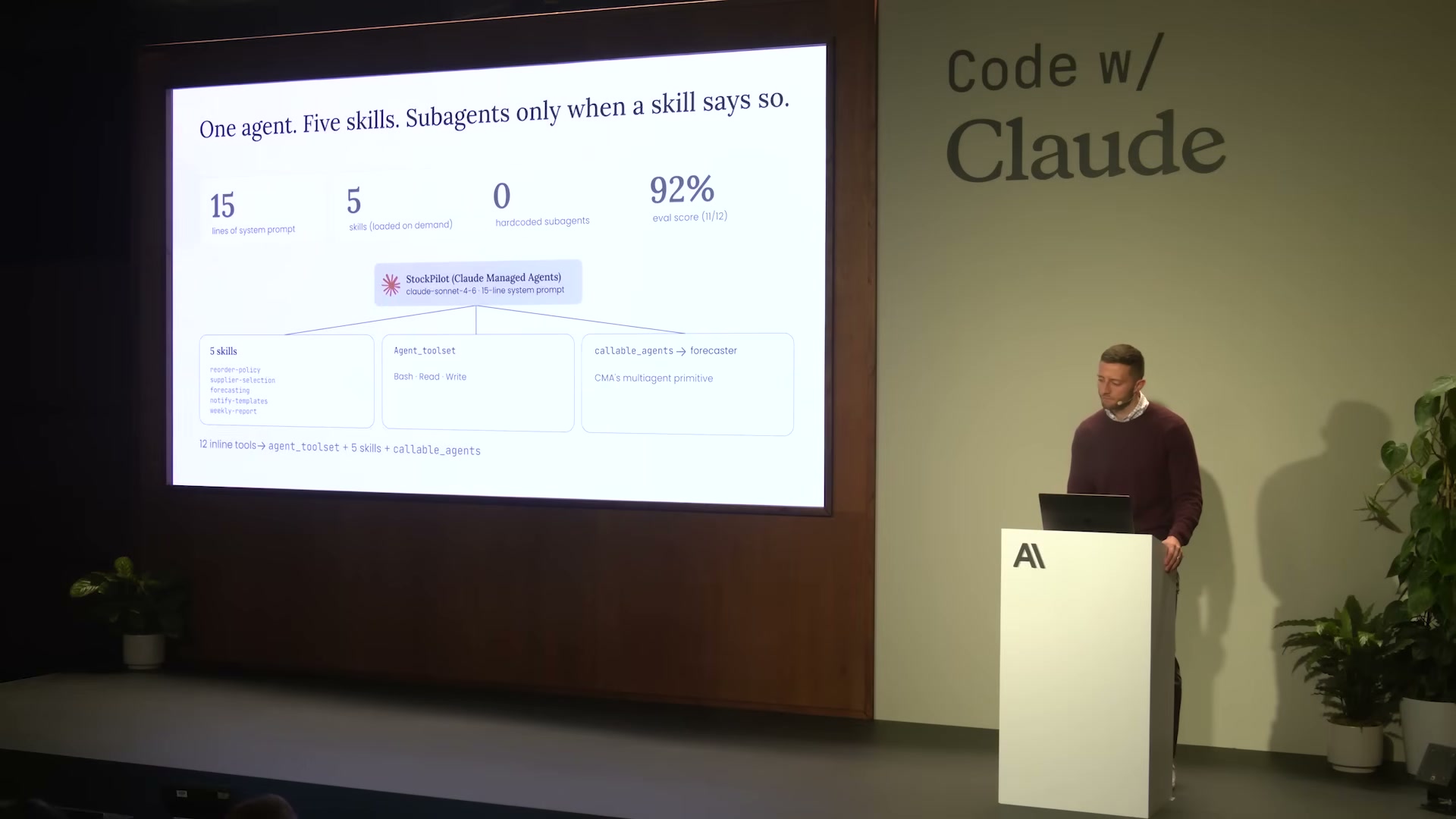
修正後のアーキテクチャを図示する。
Claude Managed Agents
15行 system prompt] Orch --> Skills[5つのスキル
reorder-policy
supplier-selection
forecasting
notify-templates
weekly-report] Orch --> Tools[agent_toolset
Bash - Read - Write] Orch --> CA[callable_agents] CA --> Forecaster[Forecaster Agent
独立コンテキスト
strict JSON output] Skills -->|skill says so| CA
修正前と修正後の変化をまとめる。
| 項目 | 修正前 | 修正後 |
|---|---|---|
| システムプロンプト | 約400行 | 15行 |
| スキル | 0(全てプロンプトに埋め込み) | 5種(必要時にロード) |
| ツール数 | 12個(専用カスタムツール) | 3個(Bash + Read + Write) |
| サブエージェント | 3個(ハードコード) | 1個(forecaster、skill経由でのみ起動) |
| ホスティング | 手書きMessages APIループ | Claude Managed Agents |
evalヒルクライミングの成果
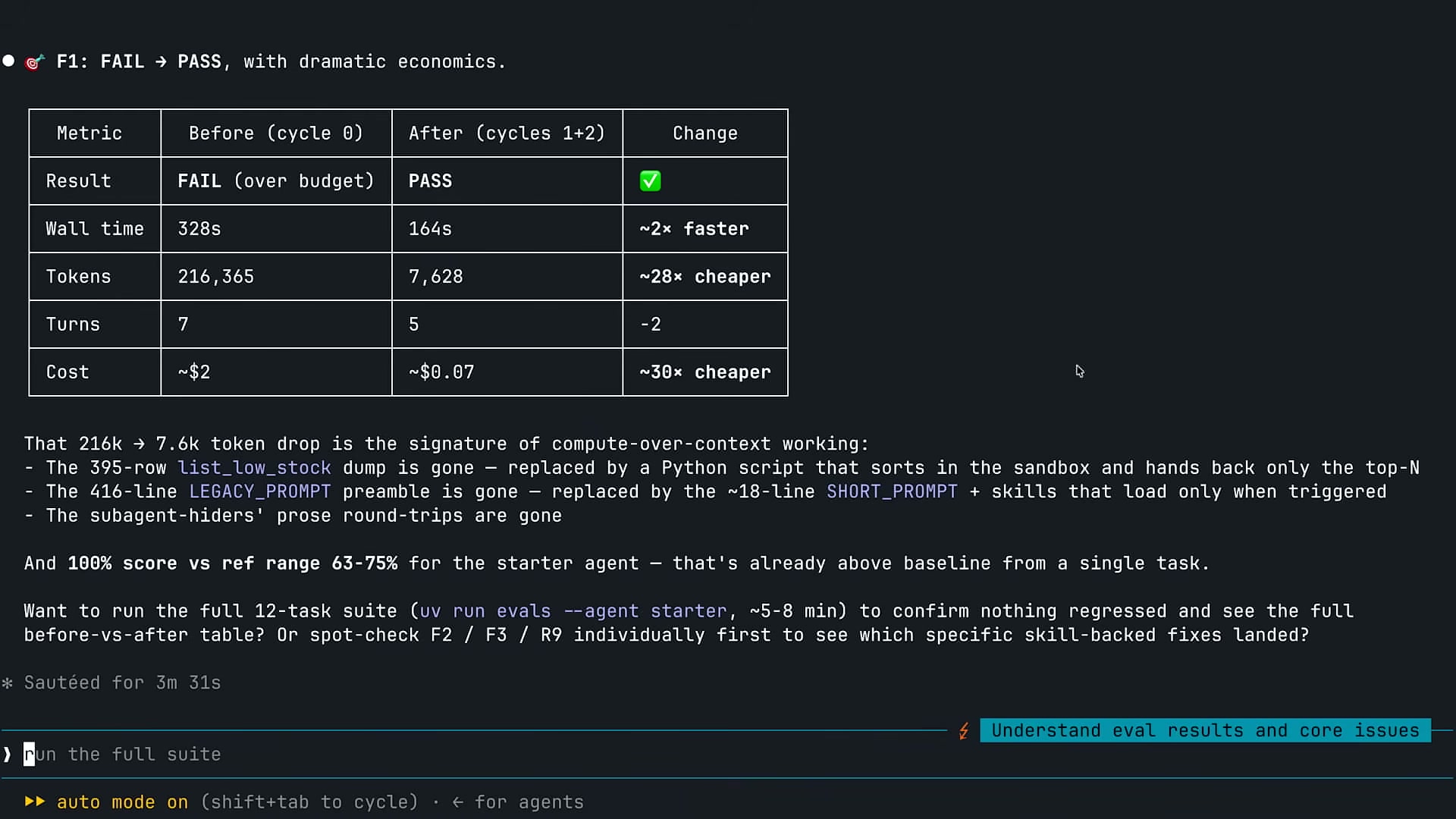
F1(日次低在庫スイープ)のevalで最も劇的な改善が見られた。
| 指標 | 修正前 | 修正後 | 変化率 |
|---|---|---|---|
| 結果 | FAIL(予算超過) | PASS | ✓ |
| 実行時間 | 328秒 | 164秒 | 約2倍高速 |
| トークン使用量 | 216,365 | 7,628 | 約28倍削減 |
| ターン数 | 7 | 5 | -2 |
| コスト | 約$2.00 | 約$0.07 | 約30倍削減 |
216,000トークンから7,600トークンへの削減は「compute-over-context」問題の解消が主因だ。
- 400行の
LEGACY_PROMPTが約18行のSHORT_PROMPT+ オンデマンドスキルに置き換わった list_low_stockの395行CSVダンプが、Pythonスクリプトによるtop-N JSON出力に置き換わった- サブエージェントの散文ラウンドトリップがなくなった
全12タスクのevalスイートを通じた最終スコアは92%(12タスク中11タスク合格)。ベースラインの63-75%から大幅に改善した。
Will Steukはヒルクライミングの哲学についてこう述べた。「われわれはevalをプロダクトの能力拡張に合わせて継続的に進化させる。モデルの能力も変化する。evalは固定のゴールでなく、開発サイクルのコンパスだ」
エージェント設計3原則——まとめ

Will Steukが最終スライドでまとめた3原則は、このワークショップ全体を貫くメッセージだ。
Bash・スキル・サブエージェントといった基盤プリミティブ中心に設計することで、より優れたモデルに切り替えるだけでエージェントの能力が上がる。複雑なカスタムツールを積み重ねると、モデルのアップグレードでむしろ挙動が変わるリスクがある。
システムプロンプトからコンテキストをスキルにオフロードし、エージェントが特定のタスクに必要な情報だけを読み込む。全情報を常時コンテキストに載せることは「コンテキストの汚染」だ。
モデルの能力が進化するにつれて、evalも進化させる。「今のモデルが限界だからevalは無意味」でも「現状のevalは永遠に正しい」でもない。継続的にevalを見直し、エージェントが本当に達成すべきことを計測できているか確認し続けることが、ヒルクライミングの本質だ。
ツール・スキル・サブエージェントの判断フレームワーク
このワークショップの核心は、3つのプリミティブの使い分けを実際の事例で示した点にある。
ClaudeがBash・Read・Writeで代替できない処理のみ。外部APIへの認証付きアクセス、特定フォーマットのデータ書き込み、マネージドサービスとの連携など。まずBashで実現できないか試すべきだ。ツールの数が増えるほどコンテキストが汚染され、モデルが混乱する。
ポリシー・手順・出力フォーマット・ドメイン知識のうち、全タスクには不要だが特定タスクには必須の情報。「予測が必要なときだけ予測ルールを知る」「週次レポートが必要なときだけレポートフォーマットを知る」という設計がProgressive Disclosureだ。システムプロンプトに書くべき情報は「Claudeが全タスクで常に必要とする情報」だけに絞る。
2つの条件のどちらかが成立するとき。①並列化して速度・深度を上げたい場合(ウェブリサーチ、コードベース探索など)。②メインエージェントのコンテキストから独立させたい処理がある場合(コードレビュー、フォーキャスティングなど)。サブエージェントを「デフォルト」にしない。追加するたびにオーケストレーターとサブエージェント間のコミュニケーション品質が問われる。
まとめ
Code with Claude Londonで公開されたこのワークショップは、エージェント設計の実践的な教科書として機能する。
StockPilotの変遷が示すのは「肥大化した設計は、悪い判断の集積でない」という逆説だ。各追加は当時の要件を満たす最善の判断だった。しかし積み重なった複雑性がシステム全体を不安定にした。解決策は「リセットして再設計する」ことではなく、「どこに何を置くべきかを整理する」ことだった。
スキルは情報のありかを整理する。プリミティブツールはモデルに人間と同じ能力を与える。サブエージェントは必要な場面でのみ独立した思考を提供する。この3つを適切に組み合わせ、evalで定量的に計測しながら改善を積み上げる——それがAnthropicが「ヒルクライミング」と呼ぶ、実運用エージェントを磨き続けるプロセスだ。
参照ソース
- Code with Claude London ワークショップ動画(YouTube) — Will Steuk(Anthropic MTS)によるライブデモ、2026年
- Anthropic公式ドキュメント: Claude Managed Agents — managed-agents / callable_agents / skills
- ClaudeチームThariqが明かしたSkills設計9カテゴリ — Anthropic社内でのスキル活用実践録
- ハーネスエンジニアリング完全解説 — Claude Codeのエージェントループ設計をソースから読む