
Code with Claude London 2026の全セッション解説は Code with Claude London 2026 完全ガイド|全11セッション動画・要約・登壇者まとめ をご覧ください。
2026年5月19日、Code with Claude Londonの会場でAnthropicのDaisy Hollmanが壇上に立った。スライドに書かれたサブタイトルはこうだ——“How we run Claude Code on our own codebase — and what we’ve learned”(AnthropicがClaude Codeを自社コードベースで実際にどう運用し、何を学んだか)。
「基礎を超えて」と題したこのセッションは、一般的なチュートリアルではない。Anthropicという、Claude Code自体を作っている会社の内側から得た、2年分の運用知見だ。41枚のスライドを通じてHollmanが繰り返したのは一つのフレーズ——「Does it scale?(スケールするか?)」。

セッション概要
- 発表者: Daisy Hollman(Anthropic、Member of Technical Staff)
- イベント: Code with Claude London 2026(2026年5月19日)
- 時間: 30〜40分
- 動画: YouTube(英語)
セッションのアジェンダ:4つの問いかけ
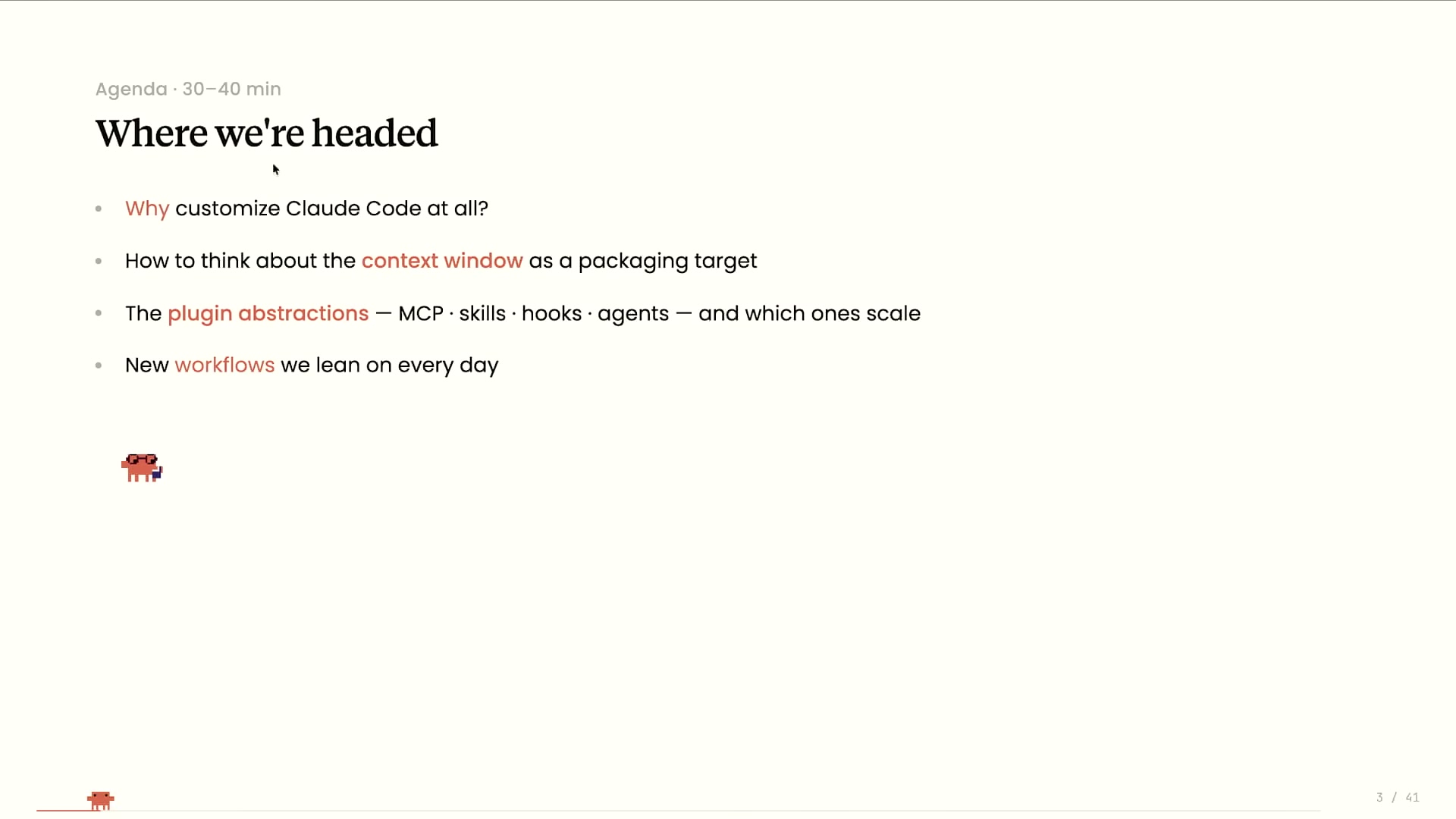
Hollmanのアジェンダは4つのテーマで構成される:
- Why customize Claude Code at all? — そもそもなぜカスタマイズするのか
- How to think about the context window as a packaging target — コンテキストウィンドウをパッケージングターゲットとして捉える
- The plugin abstractions — MCP · skills · hooks · agents — and which ones scale — 4つの拡張単位とスケーラビリティの評価
- New workflows we lean on every day — Anthropicが日常的に使うワークフロー
一見シンプルだが、Anthropic内部の運用実績に基づいた「何が機能し、何が機能しないか」の正直な報告がこのセッションの核心だ。
なぜカスタマイズするのか——「仕事が実際に存在する場所」から考える
Claude Codeを導入したものの、どこまでカスタマイズすべきか判断に迷う開発者は多い。Hollmanはこの問いをシンプルに整理した。カスタマイズの目的は「Claudeに、仕事が実際に存在する場所へのアクセスを与えること」だ。

「仕事が実際に存在する場所」とは何か。Hollmanが例として挙げたのは:
- Team chat: Slack, Teams, email — スレッドをトリアージし、オーナーに確認し、PRを投稿する場所
- コードリポジトリ: PR・イシュー・コードレビューが行われる場所
- CI/CDパイプライン: ビルド・テスト・デプロイが実行される場所
Claude Codeがこれらの場所にアクセスできなければ、単なるコード補完ツールで終わる。カスタマイズとは、Claudeの「手」を仕事が本当にある場所に届かせる行為だ。
「カスタマイズの目的をソースコードの変更に限定するのは間違い。PRのトリアージ、Slackでの質問、ドキュメントの更新——これらすべてがClaude Codeの仕事の範囲になる」
そしてもう一つのアクセス視点——Tooling(ツール)だ。

Hollmanのスライドには、Anthropicの内部的な視点の転換が凝縮されていた:
“We build tools for humans to write code better. We should build tools for agents to write code better.”
人間が使う開発ツール(IDE、デバッガー、静的解析ツール)を人間が使いやすく設計してきた。同じ発想を、エージェントが使いやすく設計したツールに転換する——これが「Claudeのためのツールを作る」という考え方だ。
コンテキストウィンドウをパッケージングターゲットとして考える
このセクションはセッション全体の設計哲学的な基盤を提示する。Hollmanは言う——「Claude Codeに渡すものはすべて、コンテキストウィンドウという箱に収まらなければならない」。

コンテキストウィンドウに入るものの内訳:
| 要素 | 説明 | 特性 |
|---|---|---|
| System prompt | Claudeの基本動作定義 | 常時ロード |
| Tool definitions | MCPツールのname/description/schema | 常時ロード |
| CLAUDE.md | プロジェクトルール | 常時ロード |
| Skills | カスタムスキルの定義 | descriptionは常時、bodyはpay-per-use |
| Conversation | 会話履歴・ファイル読み込み・ツール結果 | 累積 |
| Room to work | Claudeが出力するための余白 | 最低限確保必要 |
コンテキストウィンドウは「パッケージング問題」だ。各要素がどのくらいスペースを取るかを意識して、Claudeが「実際の作業」をするための余白を確保する設計が必要。
この視点が後半の「スケールするか?」という評価軸につながる。どんなに便利な機能でも、コンテキストを圧迫しすぎれば逆効果になる。
# コンテキストウィンドウ使用量の概念
# (実際の数値は参考値)
context_budget = {
"system_prompt": 2_000, # トークン
"tool_definitions": 5_000, # 20サーバー×15ツール
"claude_md": 3_000, # プロジェクトルール
"skills_desc": 1_500, # 全スキルのdescription合計
"conversation": 50_000, # 会話・ファイル読み込み
"room_to_work": 10_000, # Claudeの出力余白
}
# total: ~71,500 / 200,000 (Claude 3.5系の場合)
4つのプラグイン抽象化 — MCP・スキル・フック・エージェント

Hollmanは4つのプラグイン抽象化それぞれについて、共通のフレームで評価した——「Does it scale?(スケールするか?)」。
この問いの意味は2つある:
- コンテキスト効率: 使用しないときもコンテキストを消費するか
- チーム規模: 1000のプラグインが共存できるか
MCP — 「CLIがあるならスキルを使え」

MCPの最大の強みはポータビリティだ。Hollmanはその本質をこう整理した:
- 設計目的: シェルもファイルシステムも持たない任意のクライアントから使えるように設計されている
- サーバーが管理するもの: 認証・プロセスライフタイム・スキーマ・トランスポート — これがポータビリティの源
- Claude Codeの場合: シェルを持っているクライアントなので、MCPのメリットを全部享受する必要はない
そしてスライドに添えられた TIP が実践的だ:
"If you already have a CLI for the thing, a skill that drives it is usually less code and fewer moving parts than standing up an MCP server. Reach for MCP when there's no CLI to drive, or you need the portability."
既にCLIがある場合、そのCLIを呼び出すスキルを書く方が、MCPサーバーを構築するより少ないコードで依存関係も減る。MCPを選ぶべきなのは、CLIが存在しない場合かポータビリティが必要な場合だ。
MCPのスケール問題と解決策

MCPには固有のスケール問題がある:
- 全ツールの name + description + schema がシステムプロンプトに常時展開される
- 20サーバー × 15ツール = 300ツール → プロンプトの大半がツール定義で埋まる
- これは「コンテキストを無駄に消費する」状態だ
AnthropicはこれをClaude Codeに内蔵した tool_search で解決している:
# tool_searchの動作概念
# 1. 起動時: ツール名のみをロード(schemaなし)
# 2. 実行時: 必要なツールのschemaだけ動的取得
# 従来のMCP(問題あり)
# system_prompt: [tool1_name + desc + full_schema] × 300ツール = 巨大
# tool_search導入後
# system_prompt: [tool1_name] × 300ツール + 使用ツールのschemaのみ = 小さい
「20サーバー×15ツールがあると、プロンプトがほぼツール定義で埋まる。tool_searchがこれを解決する——ツール名を先にロードし、schemaは必要時に取得する。我々はこれを搭載している。プロンプトサイズ問題を解決する。」
スキル — pay-per-useの設計思想
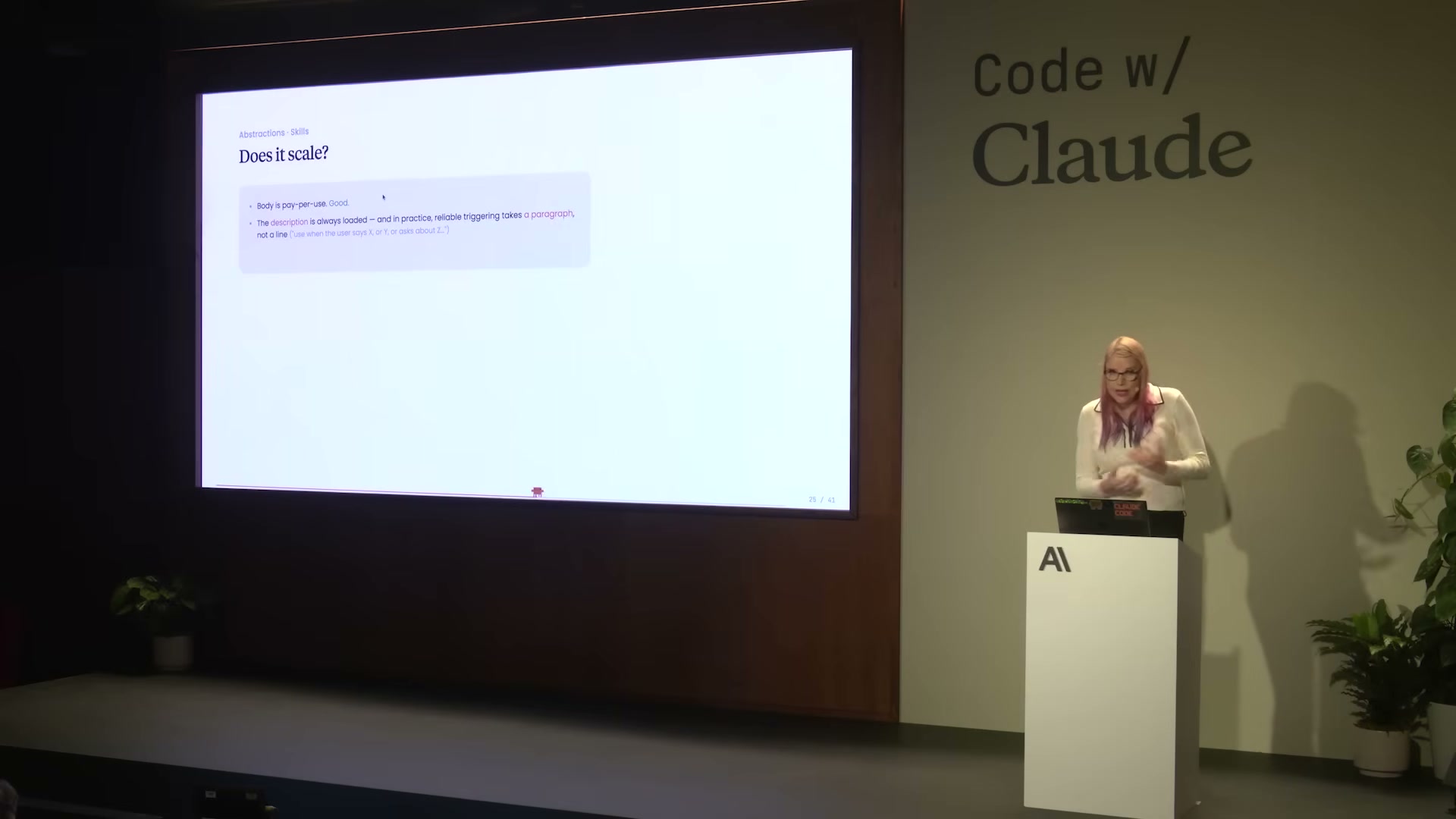
スキルには「スケールする」という評価が下されている。理由はpay-per-use(使用時のみコスト発生)の構造にある:
- Body(本文): pay-per-use。スキルが実際に使われたターンのみコンテキストに乗る
- Description: 常時ロード。Claudeがスキルをトリガーするかを判断するために必要
ここで重要な実践的知見がある——descriptionを1行で書くな:
「Descriptionは常にロードされる——そして実際のところ、信頼性の高いトリガーには段落が必要で、1行では足りない(ユーザーが『Y』と言ったとき、または『Z』について聞いたとき、などの条件が必要)」
## スキルdescriptionの良い例(段落で書く)
description: |
このスキルはコードレビューを実行します。
使用タイミング:
- ユーザーが「レビューして」「コードを確認して」と言ったとき
- Pull Requestのレビューを依頼されたとき
- 「品質チェックして」「バグがないか確認して」と言ったとき
このスキルは以下のファイルを分析します: src/, tests/, .github/
Lintエラー・型エラー・セキュリティ問題を検出して報告します。
## スキルdescriptionの悪い例(1行)
description: "コードレビューを実行する" # 不十分
フック — 「ただのシェルスクリプト」
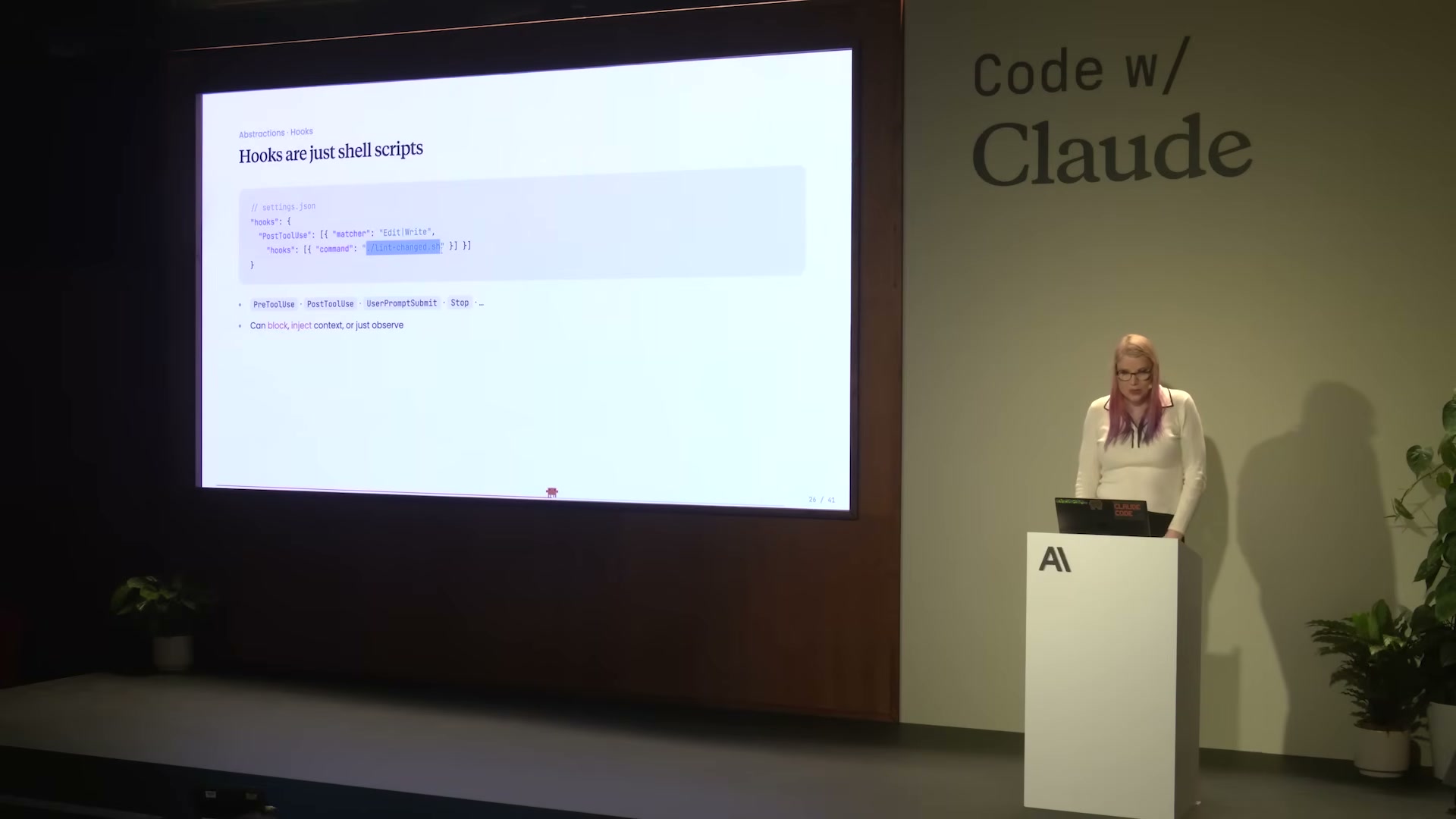
フックについてのHollmanのメッセージはシンプルだ——「Hooks are just shell scripts(フックはただのシェルスクリプト)」。
// settings.json でのフック設定例
{
"hooks": {
"PostToolUse": [{
"matcher": "Edit|Write",
"hooks": [{ "command": "lint-on-save.sh" }]
}]
}
}
フックの種類:
- PreToolUse: ツール実行前に発火
- PostToolUse: ツール実行後に発火(上記例: Edit/Write後にlintを実行)
- UserPromptSubmit: ユーザーがプロンプトを送信するたびに発火
- Stop: Claudeが応答を終了したとき
フックができること: block(実行をブロック) / inject context(コンテキストを注入) / just observe(観察のみ)
フックの典型的な使い方
-
lint自動実行: PostToolUse(Edit Write) → lint → エラーをClaudeへフィードバック - コンテキスト注入: PreToolUse → 関連ファイルを自動でコンテキストに追加
- セキュリティガード: PreToolUse(Bash) → 危険なコマンドをブロック
- 監査ログ: PostToolUse → 全操作を外部ログに記録
フックがスケールする理由: フックはシェルスクリプトを呼び出すだけなので、既存の開発ツール(lint・format・test・セキュリティチェック)をそのまま再利用できる。新たな統合層を学ぶ必要がない。
エージェント — 実験的だが方向性は明確
セッションの後半でHollmanはAgentsについて触れた。「Workflows · Agent teams (experimental)」として紹介された概念は「Claudes that talk to each other」——複数のClaude同士が通信するチームだ。
この段階では「experimental」とされており、AnthropicはClaudeエージェントチームの設計パターンを現在も精査中だ。ただし方向性は明確で、並列実行・タスク分割・オーバーナイトチームへの道筋が示された。
スケールしないリストの外——CLAUDE.mdとMemoryの正直な評価

このスライドがセッション最大の驚きだった。Hollmanは正直にプラグイン抽象化の「リストに含まれないもの」を示した。
CLAUDE.mdについての評価:
“You pay for all of it, every turn — even the 90% irrelevant to this task. And it doesn’t compose: 1000 plugins each shipping a CLAUDE.md is 1000 files in the box. Doesn’t scale. Fine for the handful of rules that truly apply everywhere.”
すべてのターン・すべてのタスクで全内容のトークンを消費する。タスクに関係ない90%のルールも毎回コンテキストに乗る。1000のプラグインが各自CLAUDE.mdを持てば1000ファイルがコンテキストに入る。スケールしない。
「すべての場所に真に適用されるごく少数のルールだけ書く」のが正しい使い方だ。
CLAUDE.mdに書くべき情報: プロジェクト全体に常時適用される不変のルールのみ。タスク固有のロジック・条件付きの指示・機能説明はスキルに切り出せ。
Memoryについての評価:
“Model-curated, not human-curated. We draw the ‘plugin’ line at human-authored, human-reviewed. Memory is downstream of that — useful, but a different contract.”
Memoryはモデルが管理するものであり、人間が書いてレビューするものではない。AnthropicはプラグインとしてMemoryを位置づけていない——「human-authored, human-reviewed」という制約を満たさないからだ。
Memoryは有用だが、別の契約(別の設計原則)の下にある。MCP・スキル・フックという「人間が明示的に設計する拡張」とは異なる性質を持つ。
これは Claude Managed Agents Memory & Dreaming で解説した内容と照合すると興味深い対比になる。同じAnthropicでも、Memoryをプラグイン抽象化として見るかどうかで設計思想が分かれている。
実践ワークフロー — Agent Viewで複数セッションを一括管理
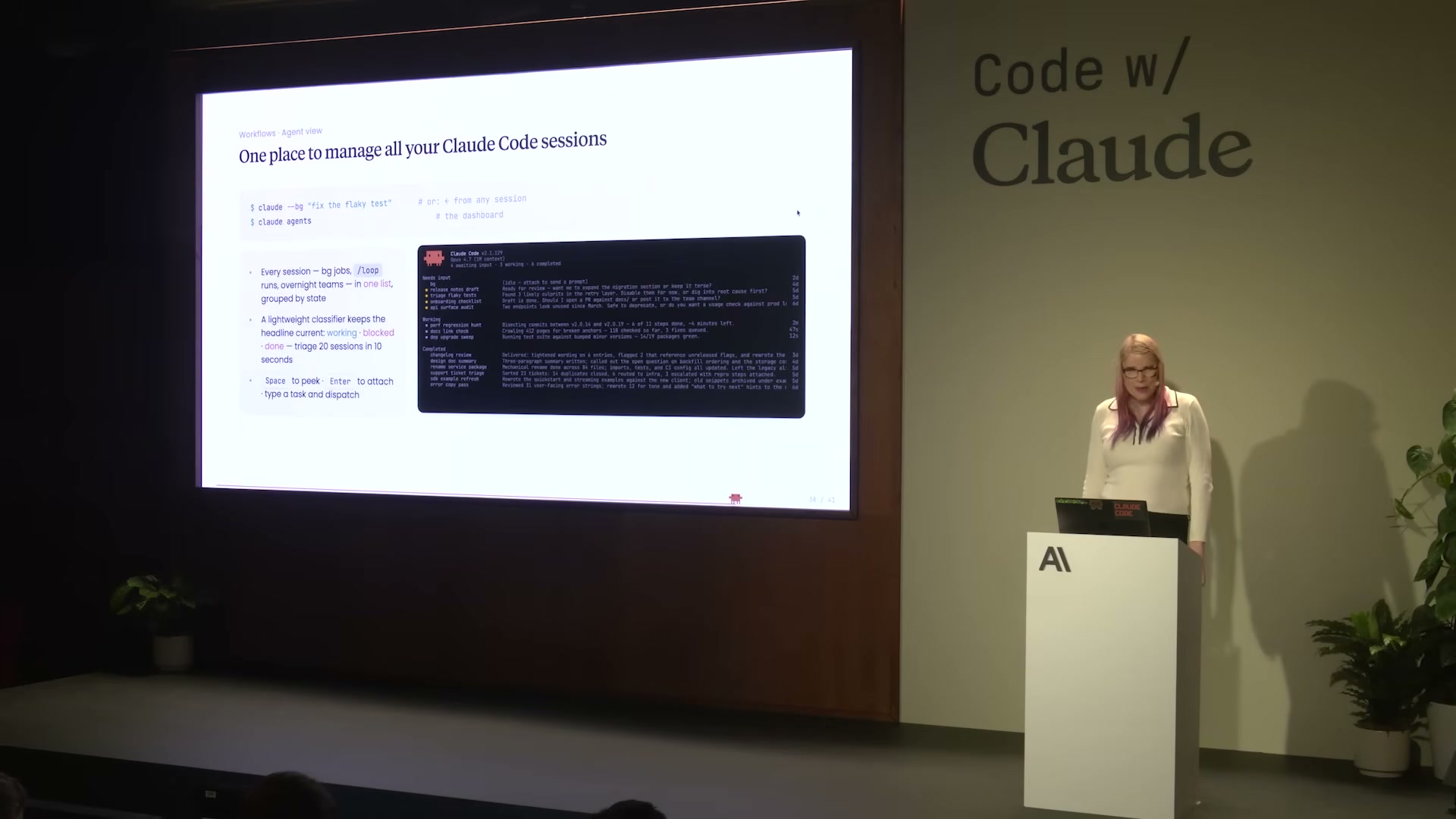
セッション後半でHollmanが紹介したのが、Anthropicが日常的に使う Agent View だ。
# バックグラウンドでエージェントを起動
$ claude --bg "fix the flaky test"
# または /loop で継続タスクを実行
# → すべてのセッションをAgent Viewで一元管理
# Agent Viewを開く
$ claude agents
Agent Viewの特徴:
- 全セッション(バックグラウンドジョブ・/loopセッション・overnight teams)が1つのリストに、状態でグループ化
- 軽量な分類器がヘッドライン(working / blocked / done)を自動更新
- 20セッションを10秒でトリアージ——どれが詰まっているかを瞬時に把握
Spaceでピーク(内容確認)、Enterでアタッチ(セッションに接続)- 任意のタスクをリストからディスパッチ可能
Agent Viewは「Claude Codeのオペレーションセンター」だ。10個のエージェントが並行して動いていても、10秒ですべての状態を把握できる。
これは Claude Code新機能完全解説2026 でも触れたAgent Viewの機能を、Anthropicが内部でどう使っているかを示す具体的な事例だ。
「スケールするか?」で選ぶ判断フレームワーク
Hollmanのセッション全体を通じて浮かび上がった判断フレームワークを整理する。
既に存在するか?"} Q1 -->|Yes| Q2{"すべてのタスクで
必要か?"} Q1 -->|No| Q3{"ポータビリティが
必要か?"} Q3 -->|Yes| MCP["MCP
(サーバー構築)"] Q3 -->|No| Q4{"操作をブロック/
観察したいか?"} Q2 -->|Yes| Q4 Q2 -->|No| Skill["スキル
(CLIをラップ)"] Q4 -->|Yes| Hook["フック
(シェルスクリプト)"] Q4 -->|No| Skill2["スキル
(手順を定義)"] MCP --> Note1["tool_search必須
スケール対策"] Skill --> Note2["descriptionは
段落で書く"] Skill2 --> Note2 Hook --> Note3["PreToolUse/
PostToolUse選択"]
| 抽象化 | スケールするか | 使い所 | 注意点 |
|---|---|---|---|
| MCP | 条件付き | CLI不在 / ポータビリティ必要時 | tool_searchでプロンプトサイズ制御 |
| スキル | する | 繰り返し手順・チーム知識の共有 | descriptionは段落レベルで書く |
| フック | する | ブロック・観察・コンテキスト注入 | ただのシェルスクリプト。既存ツールを再利用 |
| エージェント | 実験中 | 並列タスク・overnight処理 | experimental。設計パターン精査中 |
| CLAUDE.md | しない | 全タスク共通のルール(ごく少数) | 多くなりすぎたらスキルへ切り出し |
| Memory | 別カテゴリ | モデル主導の学習 | プラグインではなく別の契約 |
Anthropicが自社で学んだ3つの設計原則
41枚のスライドを通じてHollmanが伝えた設計原則を3つに集約する。
原則1: コンテキストウィンドウは有限のリソース——すべての要素をコスト意識で設計する
CLAUDE.mdがすべてのターンでコンテキストを消費するのと同じように、MCPの全ツールschema・スキルのdescription——これらはすべてコンテキストの「スロット」を占有する。拡張を追加するたびに「これは本当にこのコンテキストスペースを価値があるか?」を問うべきだ。
原則2: スケールの基準は「チームの規模で破綻しないか」
個人で動くものがチームで動かないのがClaude Code拡張の典型的な失敗パターンだ。CLAUDE.mdが1人の開発者のルールを記述するには十分でも、100のチームがそれぞれのルールを追加すると崩壊する。スキル・フック・MCPは独立性が高く、コンポーザブルなため、チーム規模でも機能する。
原則3: human-authored, human-reviewedの境界線を守る
AnthropicはMemoryをプラグイン抽象化から意図的に外した。理由は「人間が書き、人間がレビューする」という境界線を維持するためだ。AIが自動的に蓄積した知識と、人間が設計した知識は異なる性質を持つ——この区別を設計レベルで意識することが重要だ。
コードで実践する——本番環境への適用
Hollmanのセッション内容を実際のClaude Code設定に落とし込む例を示す。
// ~/.claude/settings.json — Anthropicのパターンに学んだ設定例
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [{ "command": "npx eslint --fix ${file} 2>&1 | head -20" }]
}
],
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [{ "command": "security-check.sh '${command}'" }]
}
]
},
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"]
}
}
}
// .claude/skills/pr-review.md — descriptionを段落で書くスキル例
---
description: |
PRレビューを実行するスキル。
使用タイミング:
- 「PRをレビューして」「プルリクを確認して」と言ったとき
- 「コードの品質チェックして」「バグがないか確認して」と言ったとき
- GitHub上のPRリンクやPR番号が提示されたとき
このスキルは以下をチェックします:
- コードの正確性・型エラー・未使用インポート
- セキュリティ上の問題(XSS・SQLインジェクション等)
- テストカバレッジの不足
---
# PR Review Skill
gh pr view {pr_number} でPRを取得し...
# Agent Viewの活用例
# 複数のタスクをバックグラウンドで並行起動
$ claude --bg "fix all TypeScript errors in src/"
$ claude --bg "update dependencies and run tests"
$ claude --bg "write unit tests for auth module"
# Agent Viewで状態を一括確認・管理
$ claude agents
# → working: 2セッション / blocked: 1セッション / done: 0
# Spaceでblocked状態のセッションを確認し、Enterでアタッチして解決
まとめ:「スケールするか?」という問いを常に持て
Daisy Hollmanのセッションは、表面的なツール紹介ではなかった。Anthropicが自社で2年間Claude Codeを使い込んで得た「何が機能し、何が機能しないか」の正直な報告だった。
「スケールするか?」という問いは、機能の評価基準として機能する。便利に見えても、チーム規模やコンテキスト消費の観点でスケールしない選択は、長期的に技術的負債になる。
Claude Code拡張の3原則: MCPはポータビリティが必要なときのみ / スキルのdescriptionは段落で書く / CLAUDE.mdに書くのは本当にすべての場所で必要なルールだけ
このセッションで触れられた各概念の詳細については:
- プラグイン抽象化の選択フレームワーク → ツール・スキル・サブエージェント——肥大化したエージェントを解剖するAnthropicワークショップ実録
- Agent ViewなどClaude Code最新機能 → Claude Code新機能完全解説2026
- ロンドンの他セッションの全体像 → Code with Claude London 2026 完全ガイド





