エージェントが何時間も自律的に動けるようになった今、開発者は何をしているだろうか。多くの場合、答えは「エージェントの横に張り付いて、一挙手一投足を見守っている」だ。コードを書いたか、ビルドが通ったか、テストは成功したか――そのたびに画面を覗き込み、問題があれば手動で介入する。これは本質的に、せっかく手に入れた自動化ツールを手動で操作しているのと変わらない。まるで自動運転の車を買って、緊張しながらハンドルに手を添え続けているようなものだ。
AnthropicのClaude Codeチーム、Member of Technical StaffであるSid Bidasariaは、2026年5月19日に開催されたCode with Claude London 2026で「Stop babysitting your agents(エージェントの監視をやめろ)」と題したセッションを実施した。その内容は、エージェントが「自走」できない根本原因を特定し、3つのコンパウンドパターンで解決するという実践的なものだった。Sidは実際のMonkeytypeクローンプロジェクトを使ったライブデモを通じて、抽象論ではなく具体的な実装方法を示した。
このセッションは、Claude Code Londonシリーズの中でも特に実装に踏み込んだ内容として注目を集めた。参加者の多くが「自分も同じ問題を抱えていた」と感じたのは、エージェントの能力向上と人間の運用スタイルの間にギャップが生まれているからだ。エージェントが数時間作業できるのに、開発者がその隣で同じ時間を費やしていては、生産性の向上幅は限定的になる。
Claude Codeの全機能と設計思想については Claude Code完全ガイド2026:インストールから本番運用まで で体系的に解説しています。
セッション概要:なぜ監視をやめるべきか
Sid Bidasaria — Member of Technical Staff, Claude Code, Anthropic
セッション: "Stop babysitting your agents"
イベント: Code with Claude London 2026(2026年5月19日開催、Londonにて)
YouTube動画ID: wI0ptqCSL0I

Sidのセッションの出発点は、シンプルな観察だ。「エージェントは数時間動き続けられるようになった。なのに、なぜ開発者はまだその横に座っているのか?」
この問いは、現在のAI開発ツールの使われ方における最大のパラドックスを突いている。Claude Codeをはじめとするコーディングエージェントは、2025年から2026年にかけて急速に能力が向上し、複雑なタスクを連続して実行できるようになった。マルチステップのリファクタリング、テストの追加、バグ修正、PRの作成——これらを人間の介入なしにこなせるようになっている。
しかし現実の運用を見ると、多くの開発者はエージェントの実行中にターミナルの前に座り続けている。「次に何をするか」を確認し、エラーが出れば原因を見て修正指示を出し、完了したかどうかをチェックする。これは根本的に間違っていない——問題は、エージェントにそれをやらせていないことだ。
問題の核心は「監視コスト」にある。エージェントが作業を完了するたびに人間が確認し、次のステップを判断し、問題があれば介入する——このサイクルが続く限り、並列化も長時間実行も絵に描いた餅だ。開発者のキーボードがボトルネックになっている。
Sidが提示した解決策は、3つのコンパウンドパターンだ。それぞれが独立して機能するだけでなく、組み合わせることで指数的に効果が高まる。「コンパウンド(compound)」という言葉を選んだのは意図的で、金融における複利のように、パターンが重なるほど効果が加速することを示している。

3パターンを一言で要約すると:
- Verification(検証) — Claudeに自分の仕事を自分でチェックさせる
- Parallelize(並列化) — すべてのClaudeエージェントを1画面で管理する
- Background Loops(バックグラウンドループ) — キーボードをボトルネックから外す
以降のセクションで、それぞれのパターンを実装レベルまで掘り下げる。
エージェントが”自走”できない本当の理由
現在のほとんどのエージェントは、タスクを実行して「完了しました」と報告する。ここに根本的な問題がある——「完了した」と「正しく動作している」は、まったく別の話だ。
人間が仕事を終えたとき、私たちは自然に自己検証を行う。コードを書いたらビルドする。ビルドが通ったら実行する。実行したら副作用(ログ、画面表示、DB状態)を確認する。ユニットテストを走らせる。最終的にデプロイして確認する。この一連のフローは、長年の経験で身についた「当たり前の習慣」だ。

エージェントの問題は、このフィードバックループが存在しないことだ。コードを書いて「完了」と宣言する。ビルドエラーが出ていても、実行時に壊れていても、視覚的なUIが崩れていても、それを確認するステップが組み込まれていなければ、エージェントは気づかない。エージェントにとって「タスクの完了」は「コードを書き終えること」であり、「動作することを確認すること」ではない。
この問題はさらに深いところにある。エージェントが自己検証できないのは能力の問題ではなく、設計の問題だ。Claude Codeは十分な能力を持っている。ブラウザを操作できる。ログを読める。テストを実行できる。DBを確認できる。これらの能力はすべて存在する。しかし、それをいつ・どの順序で実行するかという「自己検証プロセス」は、明示的に教えなければエージェントには組み込まれない。
そして開発者が「監視しなければならない」と感じる理由がここにある。エージェントが自己検証できないから、人間が代わりに検証する。これを変えるのが「Verification」パターンの核心だ。
1. 自己検証プロセスの不在 — コードを書いて「完了」と宣言するが、実際に動作するか確認しない。「書き終えた」と「動く」は別物だという認識がない
2. フィードバックループの設計欠如 — エラーや副作用を確認してコードを修正し、再度確認するというサイクルが自動的には回らない
3. 人間介在の構造的依存 — 「次に何をすべきか」の判断が毎回人間に委ねられる設計になっている。エージェントが自律的に判断できるのは、明示的に与えられた範囲内だけだ
この問題を認識した上で、Sidが提示した3パターンの詳細を見ていこう。
パターン1:Verification — Claudeに自分の仕事をチェックさせる
Verificationパターンの本質は、「人間が当然やること」をエージェントにも教えることだ。Sidが強調したのは、これが単純な「テストを実行せよ」という指示ではなく、検証スキル(Verification Skill)として体系化されるべきものだという点だ。
検証スキルは、Claude Codeのスキルシステムを使って実装する。スキルファイルに「検証の手順」を記述しておくことで、Claudeは毎回それを参照しながら一貫した検証プロセスを実行できる。重要なのは「aggressive(積極的)に使え」というフレーズだ。コードに関連する変更を行うたびに、検証スキルを呼び出す。後でまとめてやるのではなく、変更のたびに即時フィードバックを得る。
スキルシステムの強みは、検証プロセスを再利用可能なユニットとして定義できることだ。一度検証スキルを書けば、プロジェクト内のどのタスクでも再利用できる。さらに、スキルの内容は「生きたドキュメント」として機能し、プロジェクトの複雑さが増すにつれてスキルも進化する。
ループがすべてを変える
Sidが「Loops make the world go around(ループが世界を回す)」というスライドで示したのは、エージェントのフィードバックループの構造だ。
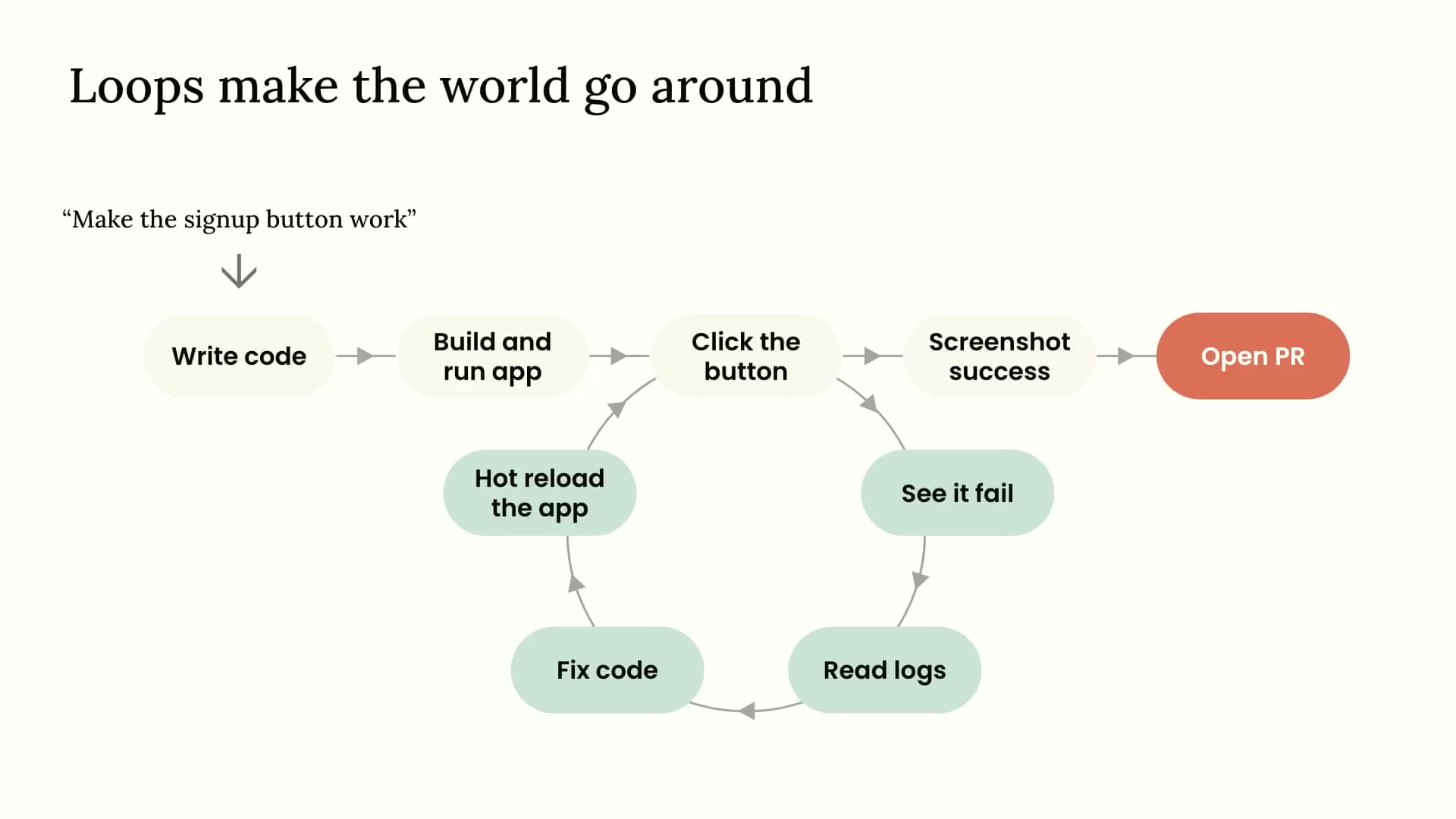
このダイアグラムが示すのは、エージェントがコード修正→ビルド&実行→ログ確認→ホットリロード→再確認というループを自律的に回せるようになったとき、初めて「本当に自走する」ということだ。ループの外にいる人間は、最初のタスク指示とPRのレビューだけでよくなる。
ループ構造は、単なる「繰り返し処理」ではない。各イテレーションでエージェントは新しい情報を得て、次の行動を決定する。ログを読んでエラーの原因を特定し、コードを修正し、再びビルドして確認する——この自律的な問題解決サイクルこそが、エージェントを「使うツール」から「任せられるパートナー」へと変える。
このフィードバックループこそが、並列化(Pattern 2)と組み合わせたときに真価を発揮する基盤となる。1つのエージェントが自律的にループを回している間に、開発者は別のエージェントに別のタスクを与えられる。そのエージェントも同様に自律的にループを回す。これが真の並列化だ。
3種類の検証:UX・バックエンド・E2E
Sidは検証を3つのフレーバーに分類した。プロジェクトの性質に合わせて適切な検証戦略を選ぶことが重要で、すべてのプロジェクトで全フレーバーを実装する必要はない。

フレーバー1:UX検証 — ブラウザを実際に動かす
UX検証では、Claudeがリアルなブラウザを操作してUIの状態を確認する。テキストで「ページが表示されているはず」と判断するのではなく、実際にブラウザを開いてスクリーンショットを撮り、視覚的に確認する。これを可能にするのがClaude Chrome MCP(Model Context Protocol)だ。
Claude Chrome MCPは、ブラウザをAPIで操作するためのMCPサーバーで、Claudeがページの内容を読み取り、クリックし、フォームに入力し、スクリーンショットを撮るといった操作を実行できる。人間が目で確認していた「UIが正しく表示されているか」「ボタンが動作するか」「フォームが送信できるか」といったチェックをClaudeが代行する。
UX検証が特に価値を発揮するのは:
- フロントエンドコンポーネントの変更後
- CSS・スタイル変更後(レイアウト崩れの検出)
- インタラクション(クリック、フォーム送信)の実装後
- レスポンシブデザインの確認
フレーバー2:バックエンド検証 — サービスを起動してDBまで確認
バックエンド検証は、APIルートを実際にヒットしてレスポンスを確認し、DBの状態変化を検証し、ログを読むというアプローチだ。「コードが正しく書けているはず」ではなく、「実際にサービスを起動して動作を確認する」。
バックエンド検証のフロー:
- サービスを起動する(例:
npm run server) - 対象のAPIエンドポイントにリクエストを送る
- レスポンスのステータスコードと内容を確認する
- DBの状態変化を確認する(新しいレコードが作成されたか、更新されたかなど)
- エラーログがないことを確認する
バックエンド検証では、実際の副作用(DB書き込み、外部API呼び出し)が発生するため、テスト環境の分離が重要になる。開発環境やテスト用DBを使うことで、本番データへの影響を防ぐ。
フレーバー3:E2E検証 — ステージングに本番トラフィックをリプレイ
E2E(エンドツーエンド)検証はより重い検証で、ステージング環境にデプロイして本番相当のトラフィックをリプレイする。個々のコンポーネントを個別に確認するのではなく、システム全体が統合された状態で動作するかを確認する。
E2E検証は、CI/CDパイプラインに組み込むことで、エージェントのコード変更が本番環境に影響しないことを継続的に保証できる。デプロイ前の最後の砦として機能し、ユニットテストやバックエンド検証では発見できない統合レベルのバグを検出する。
3つのフレーバーは排他的ではなく、組み合わせて使うことも多い。フロントエンドの変更にはUX検証、APIの変更にはバックエンド検証、リリース前にはE2E検証——という使い分けが実践的だ。
検証スキルの実装(コードと実践例)
Sidがデモで使用した検証スキルのYAMLを見てみよう。Claude Codeのスキルシステムは、.claude/skills/ ディレクトリ(またはプロジェクトルートの skills/ ディレクトリ)にMarkdownファイルを配置することで利用できる。

---
name: verify
description: >
Use this skill to verify testing the front end whenever you make changes
to it. Use it aggressively any time you touch relevant code.
---
1. pnpm run dev (frontend + backend)
2. wait for localhost:3000 health check
3. Use Claude Chrome mcp to open localhost:3000
4. Test all relevant features of the code we've touched so far and $ARGUMENTS
5. If needed, correlate behavior with logging
If you run into blockers, find a solution and update this skill for the future.
このスキルの設計で注目すべき点が3つある:
1. descriptionに「いつ使うか」を明記する
スキルのdescriptionは単なる説明文ではなく、Claudeがそのスキルをいつ呼び出すかを判断するための指示文でもある。"Use it aggressively any time you touch relevant code"という記述が、Claudeに積極的な検証実行を促す。この「aggressive(積極的)」という言葉の選択は重要で、Claudeに「少しでも迷ったら検証せよ」と伝えている。
2. $ARGUMENTSで動的なテスト対象を渡せる
$ARGUMENTSプレースホルダーにより、呼び出し時に追加のテスト対象を渡せる。例えば /verify "ログインフォームの送信ボタン" のように使える。これにより、汎用的な検証スキルを特定の機能のテストにも転用できる。
3. ブロッカーが出たらスキル自体を更新する
最後の行「If you run into blockers, find a solution and update this skill for the future」が重要だ。エージェントが検証中に問題に突き当たったとき、その解決策をスキルファイルに追記させることで、スキルが自己進化する。初日は単純な5ステップだったスキルが、プロジェクトの複雑さに応じて自動的に詳細化される。
stopフックで自動実行を設定する
Sidが挙げた「Pro tip」は、stopフック(Stop Hook)を使って検証スキルを自動起動することだ。stopフックはClaude Codeのフック機能の一つで、エージェントがタスクを「完了」しようとするときに指定したコマンドを実行する。
{
"hooks": {
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "echo 'Reminder: Run /verify if you have not already done so'"
}
]
}
]
}
}
このhookを設定すると、Claudeがタスクを「完了」しようとするたびに、検証スキルを実行したかどうかのリマインダーが表示される。検証をスキップして「完了」と宣言することを防ぐ仕組みだ。
より強力な実装としては、フックスクリプト内でverifyスキルの実行ログを確認し、未実行であれば実行を強制するパターンもある。例えば、特定のファイル(.verify_done)の存在を確認し、なければ検証を強制実行するシェルスクリプトをhookとして設定するアプローチだ。
stopフックとverificationスキルの組み合わせは、まさにフィードバックループを自動化する設計だ。エージェントが「完了したい」と思うたびに、「本当に完了したか確認せよ」というチェックが走る。これにより、検証が「任意のオプション」ではなく「完了の定義の一部」になる。
Claude Codeのフック機能全般については、同じCode with Claude London 2026でDaisy Hollmanが詳しく解説している。フック・スキル・MCPを組み合わせたプラグイン抽象化の設計思想は Beyond the basics with Claude Code — Daisy HollmanのMCP・スキル・フック・エージェント4プラグイン論 で詳しく解説しているので、合わせて参照してほしい。
デモ:Monkeytypeクローンで Chrome MCP を使った自動検証
Sidのライブデモは、Monkeytype(タイピング練習サービス)のクローンプロジェクトで行われた。デモで示されたのは、検証スキルを使ったUX検証の実際の流れだ。Monkeytypeクローンは、タイピング速度・精度を測定するインタラクティブなWebアプリで、コンフェッティアニメーション、カスタムモード切り替え、リアルタイムスコア表示など、視覚的な確認が必要な機能が多い。
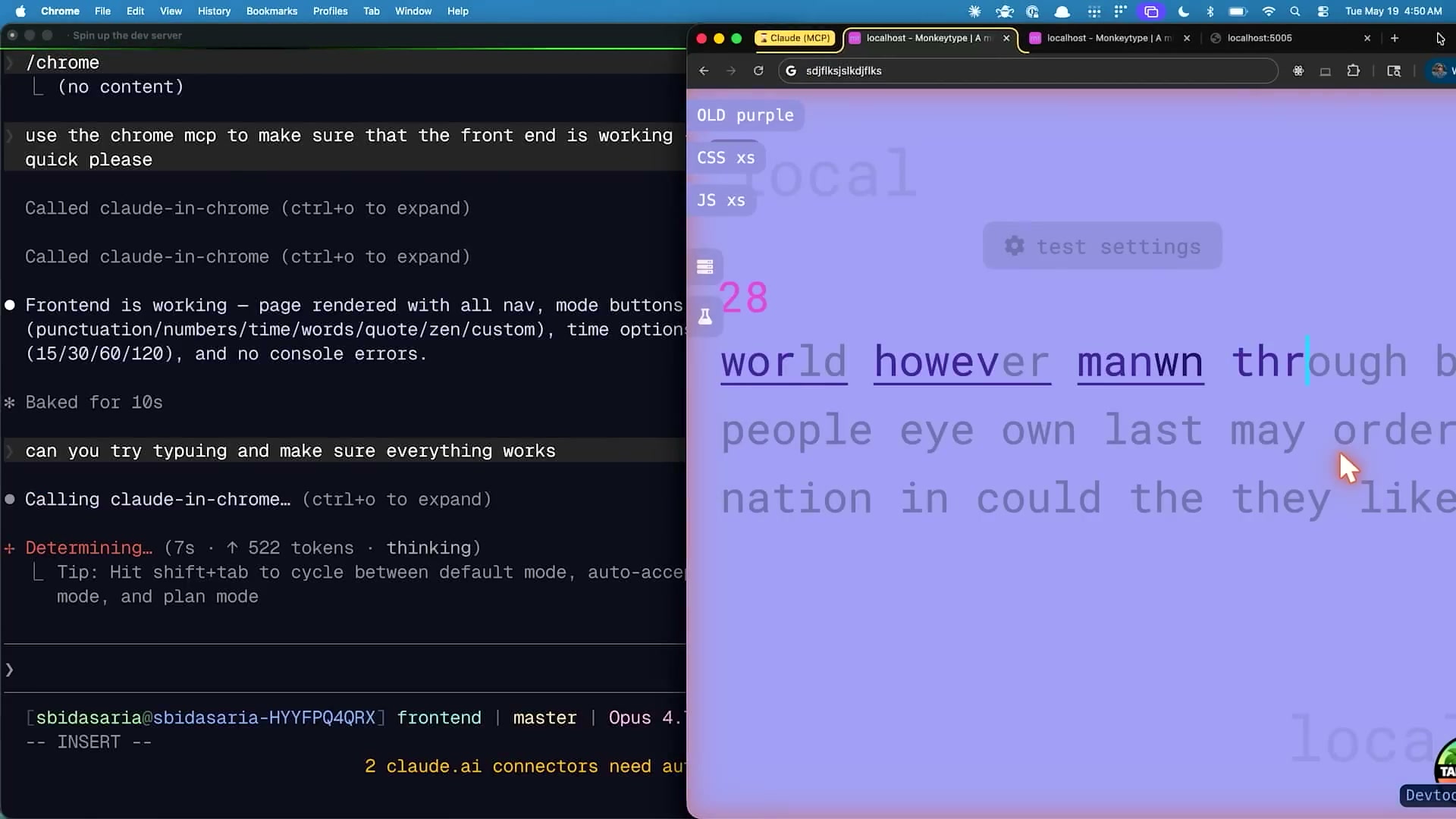
デモのプロンプトは非常にシンプルだった:
use the chrome mcp to make sure that the front end is working quick please
このたった一文の指示に対してClaudeが実行したのは、以下の一連の自律的なアクションだ:
- Chrome MCPでlocalhost:3000を開く
- ページが正しくロードされたかスクリーンショットで確認
- ナビゲーション・モードボタン・UIコンポーネントの存在を確認
- 各要素のセレクターを使ってインタラクションを検証
- 「Frontend is working – page rendered with all nav, mode buttons…」と報告
続いてデモでは、Claudeが自発的にさらなる検証を実施した。
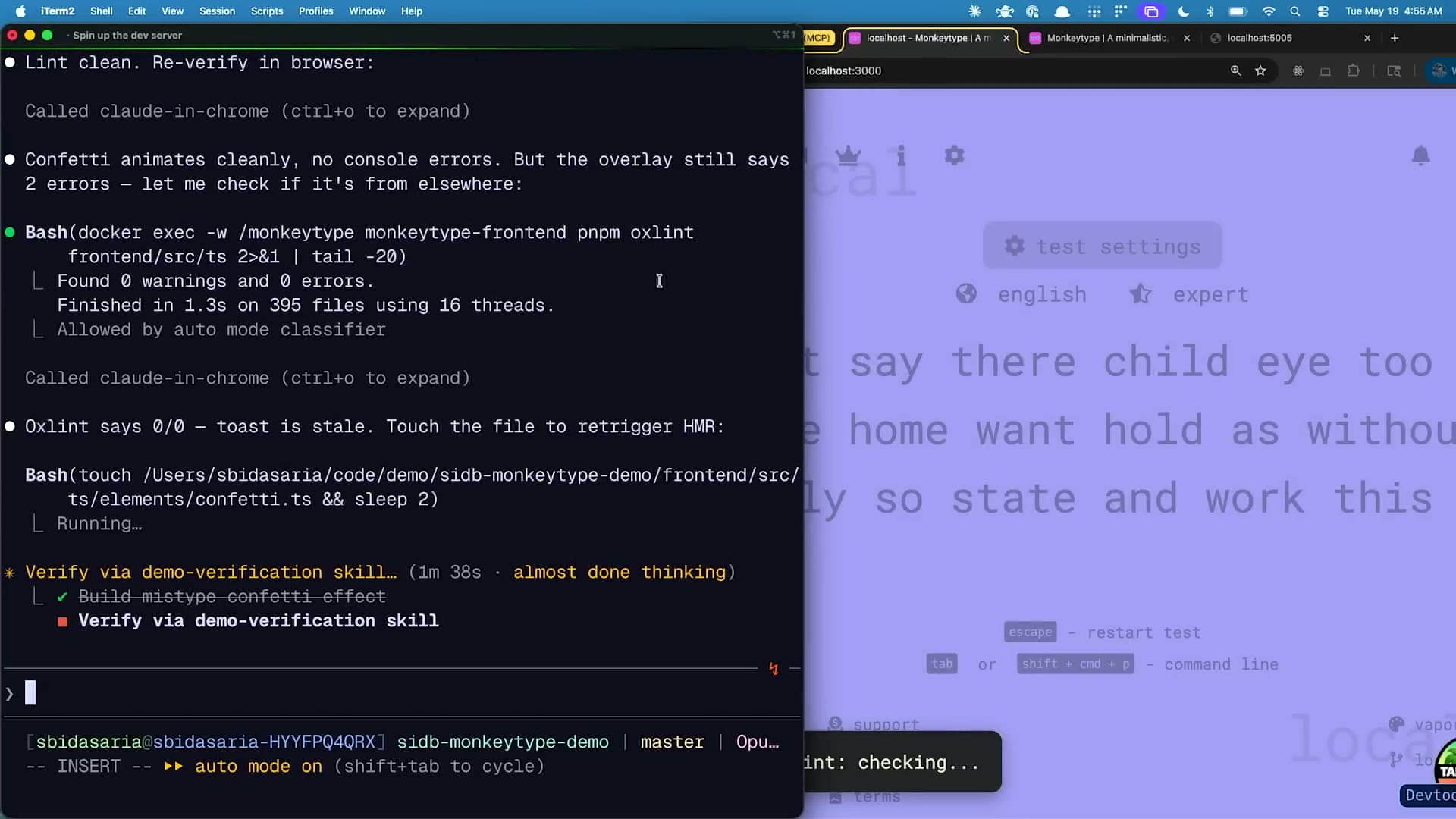
特に注目すべきは、Claudeが指示されていない問題を自律的に発見・修正した点だ:
oxlintの警告を発見・修正:検証プロセス中にClaude oxlintを実行して静的解析を行い、「警告0件」を確認した。実際には最初の実行で警告が検出され、それをClaudeが自律的に修正してから「0件」の報告をした。人間が見ていれば見落としていた可能性が高い問題だ。
ステールなHMR(Hot Module Replacement)の問題を検出:ホットリロードのキャッシュが古くなっていたことをClaudeが検出し、解決策を実装した。これはブラウザで手動確認しても気づきにくい問題で、ログを見ることで初めて発見できる。
コンフェッティアニメーションの動作確認:タイピング完了時に発動するコンフェッティアニメーションが正しく動作することを、実際にタイピング操作をシミュレートして確認した。
このデモが示す価値は明確だ。Claudeがただ「指示されたことをやる」のではなく、検証プロセスを通じて人間が気づかなかった問題を自律的に発見・修正する。開発者がコードを書いてコミットするその間に、Claudeは「本当に動くか」を多角的に検証している。
Code with Claude London 2026の全セッション一覧については Code with Claude London 2026 完全ガイド|全11セッション動画・要約・登壇者まとめ で確認できます。
パターン2:Parallelize — claude agentsで全エージェントを管理する
Verificationパターンで個々のエージェントが自走できるようになったとき、次の問題が浮上する。「複数のエージェントを同時に動かすとき、どうやって把握するのか?」
従来は、エージェントを1つ動かすたびにそのターミナルウィンドウに張り付いていた。複数動かすと、どのウィンドウに注目すべきか分からなくなる。介入が必要なエージェントを見落とす。あるいは気になって全部のウィンドウを定期的にチェックしてしまい、結局「監視コスト」が高いままになる。
並列実行の真の価値は、「エージェントが動いている間に人間が別のことをできる」ことにある。しかし実際には、「どのエージェントが問題を抱えているか」を常に把握するための認知負荷が高く、本当の意味での並列化ができていない。

claude agentsコマンドで起動するダッシュボードは、この問題を解決するために設計されている。
全エージェントを1画面で把握する
すべての実行中Claudeセッションが1つの画面に集約される。個別のターミナルウィンドウを切り替える必要がなくなる。この「1画面」という設計は単純に見えるが、認知負荷の観点では大きな違いを生む。複数の情報源を行き来するコンテキストスイッチングのコストがゼロになる。
ステータス分類で注意を最適化する
セッションは3つのステータスに自動分類される:
Needs Input(入力待ち) — 人間の判断や入力が必要な状態。最優先で確認すべきセッション。Claudeが自律的に判断できる境界を超えたとき、あるいは承認が必要な操作(重要なファイルの削除、外部サービスへの書き込みなど)に直面したときにこのステータスになる。
Working(実行中) — 自律実行中。基本的に放置してよい状態。Claudeが問題なくタスクを進めているなら、介入する必要はない。このステータスのセッションには注意を向けなくていい。
Completed(完了) — 完了済み。後でレビューするだけでよい状態。タスクが正常に完了した。Verificationスキルまで含めて完了しているため、基本的にそのままPRレビューに進める。
このステータス分類により、開発者は「今どこに注意を向けるべきか」を瞬時に判断できる。Needs Inputのセッションだけを確認し、Workingのセッションは放置する——これが並列化の本質的な運用スタイルだ。
セッションのキュレーション機能
claude agentsには、長期的な並列実行を支援するキュレーション機能がある:
- ピン留め — 重要なセッションをリストの上部に固定する。今週のスプリントで集中すべきタスクをピン留めしておけば、常に目に入る
- リネーム — セッションに意味のある名前をつける。「session-1234」ではなく「ログイン機能修正」「テスト追加」のような名前をつけることで、一覧を見たときに内容を即座に把握できる
- セッションサマリー — 各セッションの現在の状態が自動要約される。何行もの出力を読まなくても、現在の進捗を把握できる
スペースバーでプレビュー(介入なし)
最も実用的な機能の一つが、スペースバーによるプレビューだ。特定のセッションにカーソルを合わせてスペースバーを押すと、そのセッションの現在の状態をプレビューできる。
重要なのは「Without interrupting them(介入せずに)」という設計思想だ。エージェントの実行を止めることなく、現在の状況を確認できる。これにより「状況を確認したいが、エージェントの流れを止めたくない」というジレンマが解消される。プレビューは読み取り専用の観察であり、エージェントの判断や実行には影響しない。
マルチエージェント実行の実践的パターン
claude agentsによって実現できる並列化のパターンをいくつか挙げる:
機能並列:フロントエンドとバックエンドを別エージェントに担当させる。片方がUI変更を実装している間に、もう片方がAPIを修正する。互いに依存しない部分を並列化することで、開発速度が向上する。
タスク並列:実装・テスト・ドキュメント更新を別エージェントで同時に進める。コードを書いた後に逐次テストを書くのではなく、実装中にテストエージェントも動かす。
検証並列:メインのエージェントがコードを実装している間に、別のエージェントが検証環境を準備する。実装完了と同時に検証が始められる。
これらのパターンすべてにおいて、claude agentsのダッシュボードが「全体の状態把握」を担い、検証スキルが「個々の品質保証」を担う。2つのパターンが組み合わさることで、大規模な並列開発が初めて現実的になる。
パターン3:Background Loops — /loopでキーボードから解放される
3つ目のパターンは最も劇的な変化をもたらす。/loopコマンドだ。

/loopコマンドの基本構文は [インターバル] [プロンプト]だ。
# 基本構文
/loop <interval> <prompt>
# 例:10分ごとにPRをケアする
/loop 10m babysit my open PRs — fix CI, address comments, rebase
/loopの構文は [インターバル] [プロンプト]。上記の例では、10分ごとに「オープンなPRをケアする——CIを修正し、コメントに対応し、リベースせよ」というタスクをClaudeが繰り返し実行する。
Sidが強調した設計思想:「You define done. Claude figures out the iterations.(あなたが完了条件を決める。Claudeがイテレーションの方法を考える)」
これは単なるcronジョブではない。cronジョブは毎回同じコマンドを実行するだけだが、/loopの各イテレーションでClaudeは「現在の状態」を確認してから「今何をすべきか」を考える。前回のイテレーションの結果を踏まえた上で、次のアクションを決定する。
/loopの各イテレーションで実行されること
PRを監視する/loopの場合、各イテレーションでClaudeが実行するのは:
- オープンなPRの一覧を確認する
- 各PRのCIステータスを確認する
- CIが失敗していれば、失敗ログを読んで原因を特定する
- 修正可能なエラーなら修正してコミットする
- 新しいコードレビューコメントがあれば対応する(コードを修正するか、質問に返答するか判断する)
- マージコンフリクトがあればリベースして解決する
- 完了条件(「すべてのPRがマージされた」など)を満たしているかチェックする
- 満たしていなければ次のイテレーションまで待機する
/loopの活用パターン一覧
/loopは様々なシナリオで応用できる:
# PRのCI・コメント対応を自動化(10分間隔)
/loop 10m babysit my open PRs — fix CI, address comments, rebase
# 依存関係のセキュリティ脆弱性を1時間ごとにチェック
/loop 1h check npm audit for new vulnerabilities and create fix PRs
# テスト失敗を継続的に修正(5分間隔)
/loop 5m fix any failing tests in the test suite until all pass
# APIドキュメントの同期(30分間隔)
/loop 30m check if OpenAPI spec is in sync with route handlers and update if needed
# ログの異常検知(15分間隔)
/loop 15m scan application logs for error patterns and create issues for new ones
/loopによって「キーボードがボトルネック」という状況が根本から変わる。開発者は「次に何をClaudeに指示するか」を考え続ける必要がなくなる。継続的なタスクをループとして定義しておけば、Claudeが自律的に実行し続ける。
完了条件の設計が重要
/loopを効果的に使うためには、完了条件の設計が重要だ。Sidが「You define done(あなたが完了を定義する)」と言った通り、ループの終了条件を自然言語で明確にすることが設計の核心だ。
良い完了条件の例:
- 「すべてのオープンなPRがマージされるまで」
- 「テストスイートが全通過するまで」
- 「dependabotのアラートが0件になるまで」
曖昧な完了条件の例(避けるべき):
- 「コードが良くなるまで」(主観的すぎる)
- 「問題がなくなるまで」(何が問題かが定義されていない)
完了条件が明確であれば、Claudeは各イテレーション後に「完了したか」を客観的に判断できる。逆に曖昧な場合、Claudeが永久に同じ操作を繰り返す可能性がある。
Background Loopsとエージェントの自律性
/loopが示す最も重要な設計思想は、「人間の存在から独立した継続的作業」の実現だ。従来のソフトウェア開発では、継続的なタスク(デプロイ監視、テスト実行、依存関係チェック)は専用のCI/CDシステムや外部ツールが担っていた。/loopは、これらのタスクをClaude Codeのコンテキスト内で処理できるようにする。
Claude Codeはコードの文脈を理解しているため、単純なスクリプトよりも高度な判断ができる。CIが失敗した理由を理解してコードを修正する、コードレビューコメントの意図を汲んで適切な変更を加える——これらは従来のCIツールには不可能だった。
この「コンテキストを持った継続的実行」こそが、/loopの本質的な価値だ。
3パターンが「コンパウンド」する理由
個々のパターンはそれぞれ独立して価値を持つ。しかしSidが「compound(コンパウンド、複利)」という言葉を使ったのは、3つが組み合わさることで効果が単純な足し算を超えるからだ。
(開発者がプロンプト定義)"] --> B["エージェント実行開始"] B --> C["コード変更実施"] C --> D["Verificationスキル自動起動"] D --> E{"全テスト通過?"} E -->|失敗| F["エラーログ診断"] F --> G["コード自律修正"] G --> D E -->|成功| H["PR作成・コミット"] H --> I["/loop 監視開始
(バックグラウンド)"] I --> J["claude agentsで状態確認"] J --> K{"Needs Input?"} K -->|Yes| L["開発者に通知
(最小限の介入)"] K -->|No - Working| M["放置継続"] K -->|No - Completed| N["PRレビューのみ"] M --> I L --> O["開発者が判断入力"] O --> B N --> P["完了・マージ"]
このフローが示すように、3パターンが連鎖する:
- Verificationがあることで、エージェントは自律的にループを回して品質を担保する
- claude agentsがあることで、複数のVerificationループが並行して動いても全体像を把握できる
- Background Loopsがあることで、人間が離席中もVerificationが回り続け、claude agentsが状態を管理する
3つが揃うことで、開発者がすべきことは「タスクの定義」と「Needs Inputへの対応」だけになる。エージェントは自己検証しながら動き、その状態を一覧で把握でき、継続的なタスクは自動的に繰り返される。
Verificationのみ — 品質は上がるが、まだ横に座っている必要がある
Verification + Parallelize — 複数タスクを並列化できるが、ループは手動で再起動する必要がある
全3パターン — 睡眠中も作業が進む。朝起きたら全CIが通っていて、コメント対応済みで、新しいPRが作成されている
実践比較表:監視ありvs自走
| 場面 | 従来(監視あり) | 3パターン実装後(自走) |
|---|---|---|
| コード変更後の確認 | 開発者がターミナルとブラウザを手動確認(5-15分) | Verificationスキルが自律実行、スクリーンショットで証拠保存(0分の追加作業) |
| バグ発見時 | 開発者がログを読んで原因特定、修正指示 | エージェントがログ確認→原因診断→修正→再検証をループ |
| 複数エージェント管理 | ターミナルウィンドウを切り替えて目視(認知負荷大) | claude agentsダッシュボードでNeedsInputだけ確認(秒単位) |
| PR対応(CI・コメント) | 定期的にGitHubを開いて手動確認・対応(1日複数回) | /loopで自動巡回、CIエラーとコメントを自律対応 |
| 作業終了後のフォロー | その都度チェックして次の指示を入力 | ループが継続動作、完了時はCompletedに自動分類 |
| スキルの自己進化 | ルールを手動でCLAUDE.mdに追記 | ブロッカー発見時にスキルファイルを自動更新 |
| 睡眠中・外出中 | エージェントは待機状態(時間の無駄) | /loopが定期実行、朝には作業が進んでいる |
| 新しい問題の発見 | 開発者が意識的にチェックしたときのみ | Verificationが変更のたびに副作用を確認、未知の問題も検出 |
この比較が示すのは、単純な「効率化」ではなく、開発サイクルの構造的な変化だ。従来は「エージェントを使う開発者」だったのが、「エージェントに委任する設計者」に変わる。設計者の仕事は「何を達成するか」を定義することであり、「どうやって達成するか」の詳細はエージェントに任せる。
3パターンを実装する際のベストプラクティス
Verificationスキルの粒度設計
検証スキルは細かすぎても粗すぎてもいけない。推奨は「機能領域ごとに1スキル」だ。
良い粒度の例:
verify-frontend.md— フロントエンドのUIを検証(Chrome MCP使用)verify-api.md— バックエンドAPIを検証(curl + DBチェック)verify-e2e.md— ステージング環境でのE2E検証
悪い粒度の例:
- 1つのスキルにすべてを詰め込む — どの検証が必要か判断できず、毎回すべてを実行してしまう
- 1つのAPIエンドポイントに1スキル — スキルが多すぎてClaudeがどれを使うべきか迷う
スキルのdescriptionが「選択ロジック」として機能するため、descriptionに「いつ使うか」の条件を明確に書くことが重要だ。
claude agentsの運用ルール
ダッシュボードを効果的に使うための運用ルール:
ピン留めは5件以内:ピン留め機能を使いすぎると重要度の区別ができなくなる。今週完了させたいものだけをピン留めし、それ以外は通常のリストに任せる。
意味のあるセッション名:Claudeに作業を渡すとき、セッション名の命名規則を決めておく。例:「機能名-サブタスク-日付」形式(login-form-validation-0525)。後から見ても何のタスクか分かる。
Needs Inputは即対応:Needs Inputステータスのセッションは、可能な限り早く対応する。エージェントが待機している時間は非効率だ。通知設定(Claude Codeの設定で可能)を使って、Needs InputになったときにMac通知を受け取るようにする。
/loopの終了条件の設計
/loopを設定するとき、「どうなったら終了するか」の条件を自然言語で明確にする。
実践的な終了条件の書き方:
# 悪い例(曖昧すぎる)
/loop 10m improve the code quality
# 良い例(具体的な状態を指定)
/loop 10m fix failing CI checks — stop when all checks pass or when you hit 3 consecutive failures you cannot fix
# 良い例(期間も指定)
/loop 30m address PR review comments — stop when all comments are resolved or after 2 hours
自然言語の終了条件に「エスケープ条件」(解決できない問題が連続した場合は停止する)を加えることで、無限ループのリスクを下げられる。
フックとスキルの連携設計
Verificationスキルとstopフックを組み合わせた高度な設定例:
{
"hooks": {
"Stop": [
{
"matcher": "*.ts|*.tsx|*.js|*.jsx",
"hooks": [
{
"type": "command",
"command": "if [ ! -f .verify_timestamp ] || [ $(cat .verify_timestamp) -lt $(date -v -5M +%s) ]; then echo 'REMINDER: Run /verify before completing'; fi"
}
]
}
]
}
}
このhookは、TypeScript/JavaScriptファイルを変更した場合に、5分以内に検証を実行していなければリマインダーを表示する。より実践的な設計だ。
まとめ
Sid Bidasariaのセッションが伝えたメッセージは、技術的な実装の詳細よりも、考え方のシフトにある。
現在の多くの開発者は「エージェントを監視する監督者」として振る舞っている。エージェントが動くたびに確認し、問題があれば介入し、次の指示を出す。この役割では、エージェントの能力向上が直接的に生産性につながらない。エージェントが10倍速く動いても、人間の確認・判断・指示のサイクルが変わらなければ、全体のスループットは人間のスピードに制約される。
3パターンが実現するのは、開発者を「監督者」から「設計者」への転換だ:
- Verification — 「自分でチェックせよ」という能力をエージェントに与える。品質の責任をエージェント自身が負う
- claude agents — 「どこに注意を向けるべきか」を即座に判断できる環境を作る。認知負荷を最小化する
- Background Loops — 「継続的なタスクを人間の存在から切り離す」。時間制約から解放される
3つが揃ったとき、開発者がやることは「何を達成したいか」を定義することだけになる。エージェントがどうやって達成するかを考え、自己検証し、問題を修正し、継続的にモニタリングする。
「You define done. Claude figures out the iterations.」——これがSidのセッションの核心だ。そして、この言葉は単なるスローガンではなく、Verificationスキル・claude agentsダッシュボード・/loopコマンドという具体的な実装によって裏付けられている。
AIエージェントの可能性を最大限に引き出すためには、エージェントの能力だけでなく、人間とエージェントの協働設計が重要だ。Sidのセッションはその設計思想の具体的な実装例を提供した。AIエージェントを活用した開発手法のさらなる深化については AIエージェントフレームワーク比較2026 でより広い視点から比較・解説している。
FAQ
Q: Verificationスキルを使うと毎回ブラウザが起動するのですか?処理が遅くなりませんか?
A: Claude Chrome MCPを使った検証はヘッドレスモードでも実行できます。毎回フルブラウザを起動する必要はありません。また、スキルのdescriptionに「フロントエンドのコードを変更したときのみ使用する」のような条件を追加することで、不要な実行を避けられます。バックエンドのみの変更にはバックエンド検証スキルを使い分けるのが効率的です。実行時間はプロジェクトによりますが、通常のUX検証は数十秒から2分程度です。後から人間が手動確認するコストよりも低い場合がほとんどです。
Q: /loopはどのくらいのインターバルで設定すべきですか?
A: タスクの性質によります。CI確認(5-10分)、PR対応(10-30分)、依存関係チェック(1時間-1日)が目安です。インターバルが短すぎると、前のイテレーションが完了する前に次が始まるリスクがあります。また、短いインターバルはAPIコスト(トークン消費)が増加します。最初は長めのインターバルから始めて、実際の作業量を見ながら調整することを推奨します。
Q: claude agentsのNeedsInputはどのような状況で発生しますか?
A: 主に3つの状況です。①人間の承認が必要な操作(本番DBへの変更、外部APIへの重要な呼び出しなど)に直面した場合。②エージェントが解決できない選択肢(複数の同等なアプローチ)に直面して判断が必要な場合。③エラーが発生してリトライを繰り返しても解決できない場合。Verificationスキルをうまく設計すると、③のケースをエージェント自身が解決できるため、NeedsInputの発生頻度が下がります。
Q: stopフックでVerificationを強制すると、開発サイクルが遅くなりませんか?
A: リマインダーを出すだけのシンプルなhookは実質オーバーヘッドゼロです。Verificationスキル自体の実行時間(数十秒から数分)は確かに追加コストですが、それは「本当に完了したか確認する時間」です。検証なしで完了とした場合、後から問題が発見されてデバッグする時間(通常は検証時間の数倍以上)と比較すれば、前払いのコストの方が低いケースがほとんどです。むしろ「問題を早期発見することでデバッグコストを下げる」投資として捉えるべきです。
Q: このセッションで示されたパターンは、Claude Code以外のエージェントにも適用できますか?
A: 基本的な考え方(自己検証フィードバックループ、状態管理、継続的実行)はエージェント全般に適用可能です。ただし、Verificationスキル(.mdファイルベースのスキルシステム)・claude agentsダッシュボード・/loopコマンドはClaude Code固有の実装です。他のエージェントフレームワークで同様の機能を実現するには、各フレームワークの機能(メモリ、ツール、スケジューラーなど)を使って同等の設計を構築する必要があります。
参照ソース
- Stop babysitting your agents — Sid Bidasaria, Code with Claude London 2026 (YouTube) — Anthropic公式チャンネル
- Claude Code公式ドキュメント — Skills — Anthropic
- Claude Code公式ドキュメント — Hooks — Anthropic
- Claude Code GitHub リポジトリ — Anthropic





