AnthropicのMember of Technical Staff、Arnaud DokoがCode with Claude London 2026で公開した「How we Claude Code」は、長時間エージェントと協働するための3フェーズ開発フローを完全実演した技術セッションだ。「モデルが賢くなるほど、仕様の曖昧さが致命的な問題になる」——DokoはこのセッションでAnthropic社内での実際の開発プロセスを包み隠さず公開し、ブレインストーミングスキル・HTMLスペック・検証内蔵アーキテクチャという3つの武器を使った実践的なワークフローを示した。
Claude Codeを使った開発の全体像については、Claude Code完全ガイド2026:インストールから本番運用までをご覧ください。
セッション概要:3つのフェーズ

タイトル: How we Claude Code
登壇者: Arnaud Doko(Anthropic, Member of Technical Staff)
イベント: Code with Claude London 2026(2026年5月19日開催)
公開リポジトリ: github.com/anthropics/cwc-workshops — how-we-claude-code ディレクトリ
テーマ: 長時間エージェントのための3フェーズ開発フロー(Removing ambiguity / Understanding & planning / Integrated verification)

このセッションはCode with Claude Londonシリーズの中でも特異な位置づけを持つ。他のセッションが特定ツールやユースケースを紹介するのに対し、DokoのセッションはAnthropic社内エンジニアが「実際にどうClaude Codeを使って開発しているか」という内部プロセスをライブデモ付きで公開したものだ。
このセッションで公開されたフローは3つのフェーズに分かれている。フェーズ1は仕様の曖昧さをゼロにするインタビュー式のブレインストーミング、フェーズ2はMarkdownを卒業してHTMLで仕様を書くデザイン方向性の確定、そしてフェーズ3は検証をアーティファクトに内蔵するVerifiable Componentアーキテクチャだ。それぞれのフェーズにはGitHubに公開された実装が伴っており、誰でも今日から試せる内容になっている。
Code with Claude Londonの他セッションについてはCode with Claude London 2026 完全ガイド|全11セッション動画・要約・登壇者まとめもあわせて参照してほしい。
フェーズ1:あいまいさを排除する — Claudeにインタビューさせる
長時間エージェントで最も頻繁に失敗する原因は何か。Dokoの答えは明快だ。「仕様の曖昧さです。エージェントが賢くなればなるほど、曖昧な指示から多様な解釈が生まれ、意図とは異なる方向に走り続ける」。
この問題は短時間のエージェント実行では表面化しにくい。単純な1ファイル変更や、明確な修正タスクなら曖昧さがあっても問題にならない。しかし「新しいWebアプリを作って」「このサービスをリファクタリングして」「このデータベーススキーマを設計して」といった長時間・複雑なタスクでは、最初の仕様の曖昧さが雪だるま式に拡大していく。
例えば「割り勘アプリを作って」という指示を受けたエージェントは、いくつかの前提を立てて実装を始める。「5人以下のグループ」「均等分割のみ」「1回限りのイベント用」「英語UIのみ」。しかしユーザーが実際に想定していたのは「20人規模の旅行グループ」「個人ごとに異なる金額」「定期的な家賃精算」「日本語対応」だったとしたら、最終的に届くのはまったく異なるアプリになる。そしてこのズレは、実装が完成するまで誰も気づかない。
なぜ「良いプロンプト」を書くことが難しいのか
従来のプロンプトエンジニアリングの考え方では、「より具体的なプロンプトを書くべき」とされてきた。しかしDokoはここで逆説的な主張をする。
「Make it better(良くして)」は最悪のプロンプトだ。しかし、それに代わる「完璧な仕様書」を人間が書くことも実は難しい。
解決策: 仕様を書かせるのではなく、Claudeにあなたにインタビューさせる。
「Claudeはあなたが自分で仕様を書くよりも、あなたから要件を引き出すのが得意です」
この洞察の背景には、モデルが「ドメイン知識」を持っているという事実がある。Claudeはこれまで数千のWebアプリ、モバイルアプリ、ビジネスアプリの仕様書を学習しており、「割り勘アプリを作りたい」と言われた瞬間に、一般的な割り勘アプリが持つべき機能の全体像——グループ管理、支払い記録、精算ロジック、通知、履歴管理——を想起できる。
一方、ユーザーは自分が何を作りたいかは知っているが、すべての機能要件を漏れなく仕様化する方法を必ずしも知っていない。この非対称性を利用したのがブレインストーミングスキルだ。
この考え方は「良いプロンプターになる必要はない」というメッセージとも読める。Dokoはセッションの中でこう述べた:「ユーザーはドメインの専門家(例:割り勘アプリを必要とする人)だが、ソフトウェア仕様の専門家である必要はない。Claudeはその逆——ソフトウェア仕様の専門家だが、あなたのビジネスコンテキストは知らない。ブレインストーミングスキルはこの2つの専門性をブリッジする仕組みだ」。
この認識の転換は重要だ。「Claude Codeをうまく使うためにプロンプトエンジニアリングを学ぶ必要がある」という従来の前提に対して、Dokoは「Claudeに質問させればいい、プロンプトを学ぶ必要はない」と言い切る。エージェントが賢くなるほど、人間側のインターフェースはシンプルになるべきだという思想の表れだ。
AskUserQuestion ツールの仕組み
ブレインストーミングスキルの核心は AskUserQuestion ツールだ。これはClaude Codeが途中でユーザーに質問できるようにするカスタムツールで、仕様の穴を埋めるために設計されている。
通常、Claude Codeに指示を出すと一気に実装に走ってしまう。しかし AskUserQuestion ツールが定義されたブレインストーミングスキルを使うと、Claudeはまず質問モードに入り、必要な情報が集まったとClaudeが判断してから初めて仕様書の生成に移行する。
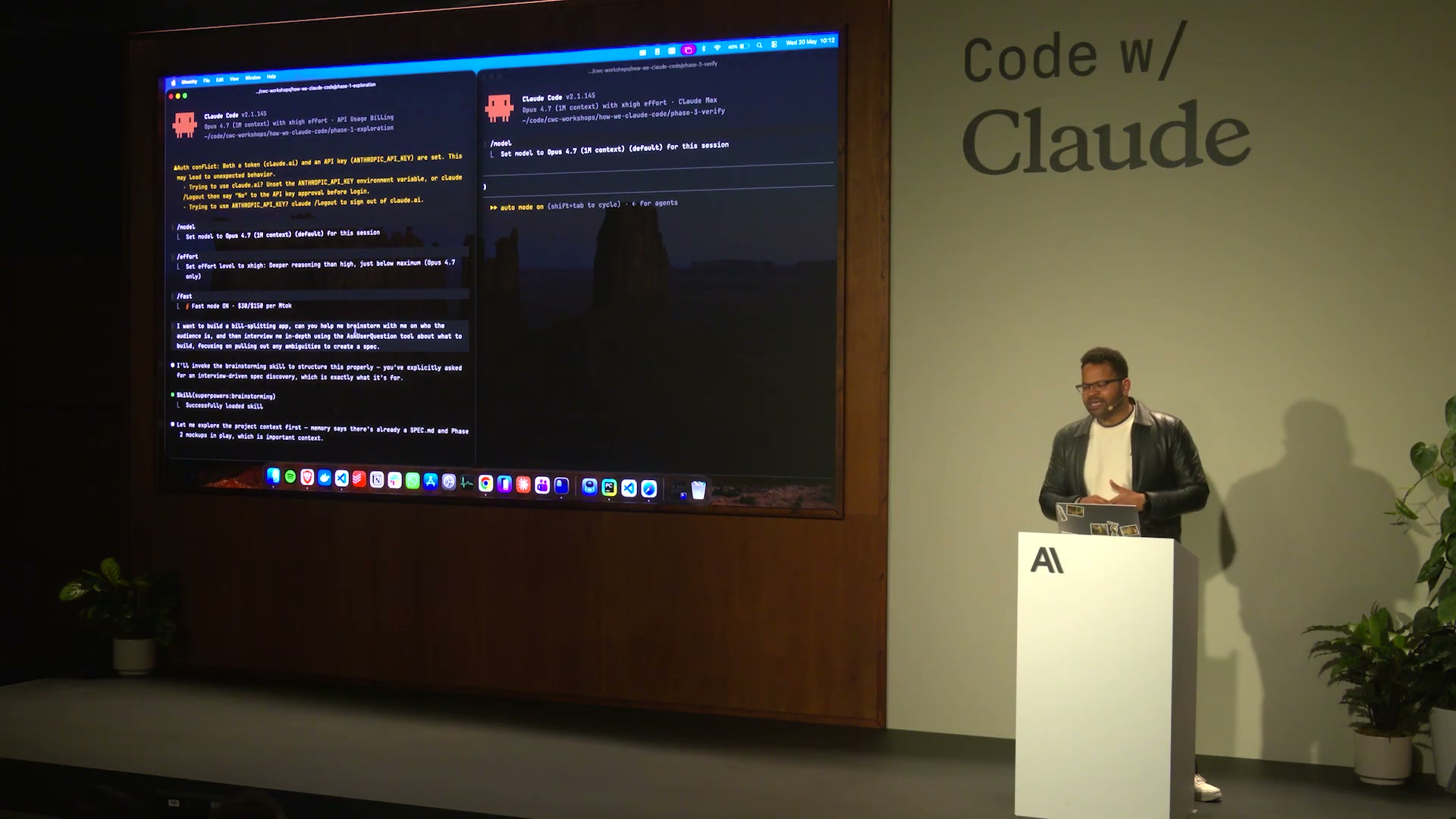
デモでは /brainstorm コマンドを実行すると、Claudeが「割り勘アプリ」というお題に対して次のような質問を行っていた:
- 何人でシェアする想定ですか?
- 支払いを均等分割しますか?それとも個人ごとに異なる金額を入力しますか?
- 通貨は単一ですか?複数通貨対応が必要ですか?
- 旅行中のトラッキング用ですか?定期的なルームメイトとの清算ですか?
- 精算方法のリマインダー機能は必要ですか?
これらの質問はDokoが事前に用意したのではない。Claudeが「割り勘アプリ」に必要な情報ドメインを自律的に判断して生成したものだ。
ブレインストーミングスキルの実装
GitHubリポジトリで公開されているブレインストーミングスキルの構造を見ていこう。スキルはYAMLフォーマットのフロントマターとプロンプト本文で構成される。
---
name: brainstorm
description: |
Interactive requirements extraction skill.
Interviews the user to create a comprehensive HTML spec
before any implementation begins.
tools:
- AskUserQuestion
model: claude-opus-4-7
effort: xhigh
fast: true
---
このYAMLの重要ポイントを解説する。
tools: [AskUserQuestion] — このスキルでは実装ツール(WriteFile, BashCommand など)を意図的に除外し、AskUserQuestion のみを使用可能にしている。これによってClaudeは「質問して情報を集める」モードに強制され、途中でコードを書き始めることができない。
effort: xhigh — Claudeの思考にかけるリソースを最大化する。要件抽出フェーズは後続のすべての作業の質を決定するため、ここにコストをかけることは合理的だ。
fast: true — 思考の出力(<thinking> タグの内容)をスキップし、ユーザーへの質問のみを表示する。/effort xhigh と fast: true の組み合わせは「深く考えるが、出力は簡潔に」という意味を持つ。
スキルのプロンプト本文は以下のような構造になっている(Dokoがデモで見せた内容から再構成):
You are an expert product requirements analyst. Your job is NOT to implement
anything yet — your job is to gather enough information to create a
comprehensive HTML spec.
## Your process
1. Ask targeted questions using AskUserQuestion tool (5-10 questions max)
2. Identify gaps in the requirements
3. Once you have enough information, generate a complete HTML spec
## Question strategy
- Ask about the core user journey first
- Identify edge cases and error states
- Clarify non-functional requirements (performance, offline, accessibility)
- Do NOT ask generic questions — each question should be specific to the domain
## Output
Generate a self-contained HTML file with:
- Visual mockups (CSS-styled)
- Component inventory
- Data model outline
- User stories
スキルの完全な実装はgithub.com/anthropics/cwc-workshopsで公開されているため、自分のプロジェクトの .claude/skills/ ディレクトリにコピーすれば即座に使えるようになる。
インタビューが終わったあと何が生成されるか
ブレインストーミングが完了すると、Claudeは収集した情報を元にHTMLスペックのドラフトを自動生成する。このHTMLはフェーズ2でさらに精緻化されるが、フェーズ1の時点でも既に次の要素が含まれている:
- コンポーネントインベントリ — 必要なUIコンポーネントの一覧
- ユーザージャーニー — 主要なユースケースのフロー記述
- データモデルの輪郭 — 必要なデータ構造の概要
- 未解決の問い — さらに確認が必要な曖昧な点のリスト(赤字でハイライト)
特に「未解決の問い」セクションが重要だ。Claudeは会話の中で答えられなかった質問(「オフライン対応は必要か?」「ユーザー認証はどうするか?」)をHTMLのコメント内に <!-- TODO: 確認が必要 --> という形で残しておく。これがフェーズ2でのデザイン確定時に解消すべき宿題リストになる。
Dokoはデモ後にこう述べた:「フェーズ1が終わった時点で、『何を作るか』は完全に合意されている。フェーズ2以降のClaudeは『どう作るか』だけに集中できる。この分離が生産性を劇的に向上させる」。
git clone https://github.com/anthropics/cwc-workshopscp -r cwc-workshops/how-we-claude-code/.claude/skills/brainstorm.md .claude/skills/プロジェクトのルートで
/brainstorm を実行すると、インタビューモードが起動する。
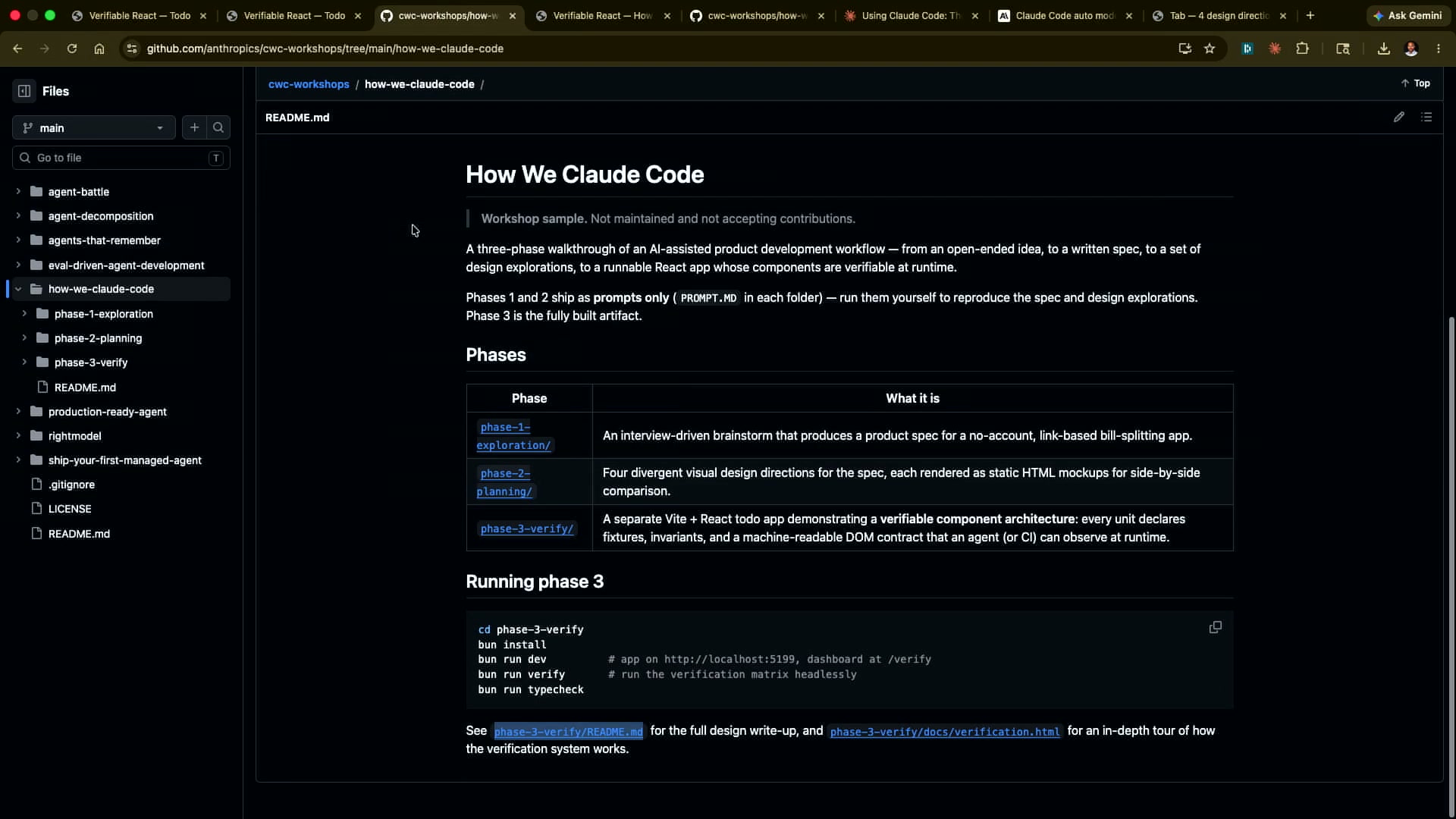
フェーズ2:HTMLで仕様を書く — Markdownを卒業する
フェーズ1でブレインストーミングが完了すると、次のフェーズに移行する。ここでDokoが提唱するのが「Markdownからの卒業」だ。
なぜMarkdownでは不十分なのか
Dokoは具体的な問題点を挙げた。「仕様書が200行を超えると、Markdownはスケールしなくなります」。プロジェクトが始まった当初、仕様書は10行、20行と小さく始まる。この段階ではMarkdownで十分だし、軽量で扱いやすい。問題は仕様が育っていく中で起きる。
機能が増え、エッジケースが明確になり、デザイン変更の記録が積み重なると、Markdownは「テキストの海」になる。Claudeがコンテキストウィンドウにこの長大なMarkdownを読み込む際、テキストとして処理するため視覚的な構造が失われる。「ヘッダー部分をネイビー系の濃い青にする」という指示はテキストで書けるが、Claudeが正確に意図を掴める保証はない。
具体的な課題は次の通りだ:
- 視覚的フィードバックが貧しい — テキストのみでデザインの方向性を伝えるのは難しい
- 情報密度が低い — スクリーンショットやスタイルが埋め込めない
- エディタビリティが悪い — 大規模なMarkdownファイルは構造が把握しにくい
-
フィードバックループが遅い — 「こういうデザインで」を文章で伝えるのは非効率
- 視覚的フィードバックが貧しい — テキストのみでデザインの方向性を伝えるのは難しい
- 情報密度が低い — スクリーンショットやスタイルが埋め込めない
- エディタビリティが悪い — 大規模なMarkdownファイルは構造が把握しにくい
- フィードバックループが遅い — 「こういうデザインで」を文章で伝えるのは非効率
- 差分が読みにくい — 400行のMarkdownに何が変わったか把握するのが困難
一方、HTMLスペックには次のような利点がある:
Opus 4.7と4つのデザイン方向性
フェーズ2でDokoが使うのは claude-opus-4-7 モデルだ。Opus 4.7はAnthropicのビジョン能力が強化されたモデルで、視覚的なHTMLを処理する際に特に力を発揮する。
デモでは、ブレインストーミングで収集した割り勘アプリの要件から、4つのデザイン方向性をHTMLで生成していた:
- Brutalist — 機能優先、装飾なし、情報密度最大
- Tokyo Fintech — 東京の金融アプリ風、ネオン×ダーク、精密なタイポグラフィ
- Minimal iOS — Apple Human Interface Guidelines準拠、余白重視
- Material You — Google Material Design 3、動的なカラーシステム
それぞれ完全に異なるビジュアル言語で生成された4つのHTMLファイルを見比べ、「このBrutalistの情報密度とTokyo Fintechのカラーパレットを組み合わせたい」という形でフィードバックできる。これがMarkdownでは実現できない、HTMLスペックの最大の利点だ。
/fast モードと /effort xhigh の組み合わせ
フェーズ2でDokoが推奨する設定がある:
/model claude-opus-4-7
/effort xhigh
/fast
この組み合わせの意味を整理すると:
/model claude-opus-4-7— ビジョン能力が高いモデルを選択/effort xhigh— 最大思考コストで4方向を丁寧に設計/fast— thinking出力をスキップして結果のみ表示(ユーザーが見るのは最終HTMLのみ)
一見矛盾して見えるこの組み合わせには明確な理由がある。
/effort xhigh はClaudeの思考の深さを制御する(モデルの内部処理)。/fast はClaudeの出力の見せ方を制御する(ユーザーへの表示)。つまり「深く考えるが、出力は結果だけ見せる」という設定だ。デザインフェーズでは思考プロセスを見せる必要はなく、4つのHTMLファイルを素早く見比べることの方が重要。
フェーズ2の成果物は確定したHTMLスペックだ。この時点でユーザーは「このデザイン方向性で実装を進める」という明確な合意をエージェントと取ることができる。
HTMLスペックへのフィードバックの方法
HTMLスペックができたあと、ユーザーがどうフィードバックするかも重要だ。Dokoはいくつかの方法を示した。
最もシンプルなのはHTMLコメントでのメモだ。ブラウザのデベロッパーツールでHTML直接編集し、気になる箇所に <!-- このボタンはもっと大きく、角丸を強調して --> というコメントを追加する。これをClaude Codeに渡すだけで意図が正確に伝わる。
次にCSS変数の上書きだ。HTMLスペックには通常 --primary-color、--font-size-base、--border-radius などのCSS変数が定義されている。これらの値を直接変更してブラウザでプレビューし、確認できたらClaudeに「このCSS変数で行こう」と伝える。
最も高度な方法がスクリーンショット参照だ。Opus 4.7のビジョン能力を活かし、「こういうデザインにしたい」という参考画像をそのまま貼り付けることができる。「このデザインの左サイドバーのスタイルを採用して」というビジュアル指示が可能になる。
これらの方法はすべて、テキストによる説明よりもはるかに情報密度が高く、誤解が生じにくい。Dokoがフェーズ2を「Understanding & Planning(理解と計画)」と名付けたのは、このフェーズがエージェントと人間が「共通の視覚的言語」を確立するフェーズだからだ。
フェーズ3:検証をアーティファクトに内蔵する
フェーズ3がDokoセッションの最も革新的な部分だ。従来のアプローチでは、開発が終わった後にテストを追加する。しかしDokoは真逆の発想を提唱する。
なぜ後付けテストでは不十分なのか
長時間エージェントが複雑なアプリを構築するとき、後付けでテストを追加しようとすると複数の問題が生じる:
- エージェントが「完成」を誤解する — テストがないと、エージェントはUIが表示されれば完成と判断する
- 回帰検出が遅れる — 後半のフェーズで前半の機能が壊れても気づかない
- 人間によるQAがボトルネックになる — スケールしない
- エージェント自身が自律検証できない — 「本当に動くか」を自分で確認できない
Verifiable Componentアーキテクチャはこれらすべての問題を解決する。ただし「テスト駆動開発(TDD)の焼き直しではないか?」という疑問も湧く。DokoはこれをTDDとは明確に区別している:「TDDはコードを書く前にテストを書く。これは良いプラクティスだが、エージェント環境では問題がある。エージェントはテストを書いた後で実装するとは限らない。エージェントはテストを適当に通過させるコードを書くかもしれない。Verifiable Componentは実装とテストを不可分に結合させることで、この問題を回避する」。
registerUnit() は「テストファイル」ではなく「コンポーネントの自己宣言」だ。コンポーネント自身が「私はこういう入力でこういう動作をする」と宣言する。エージェントがコンポーネントを実装する際には、この宣言も同時に実装しなければ不完全とみなされる。検証はコンポーネントの一部であり、切り離せない。
Verifiable Component Architecture
Verifiable Componentアーキテクチャの中核は registerUnit() 関数だ。各コンポーネントはこの関数を使って自分の「検証仕様」を宣言する。
// TodoItem.tsx(抜粋)
import { registerUnit } from '../verification/register';
registerUnit({
name: 'TodoItem',
fixtures: [
{
name: 'completed todo',
props: { id: '1', text: 'Buy milk', completed: true },
'data-verify-completed': 'true',
},
{
name: 'incomplete todo',
props: { id: '2', text: 'Walk dog', completed: false },
'data-verify-completed': 'false',
},
],
invariants: [
{
name: 'completed items have strikethrough',
check: (el) => {
const completed = el.querySelector('[data-verify-completed="true"]');
const style = window.getComputedStyle(completed);
return style.textDecoration.includes('line-through');
},
},
{
name: 'checkbox reflects completed state',
check: (el) => {
const checkbox = el.querySelector('input[type="checkbox"]');
const completed = el.getAttribute('data-verify-completed') === 'true';
return checkbox.checked === completed;
},
},
],
});
このコードが行っていることを分解して理解しよう。
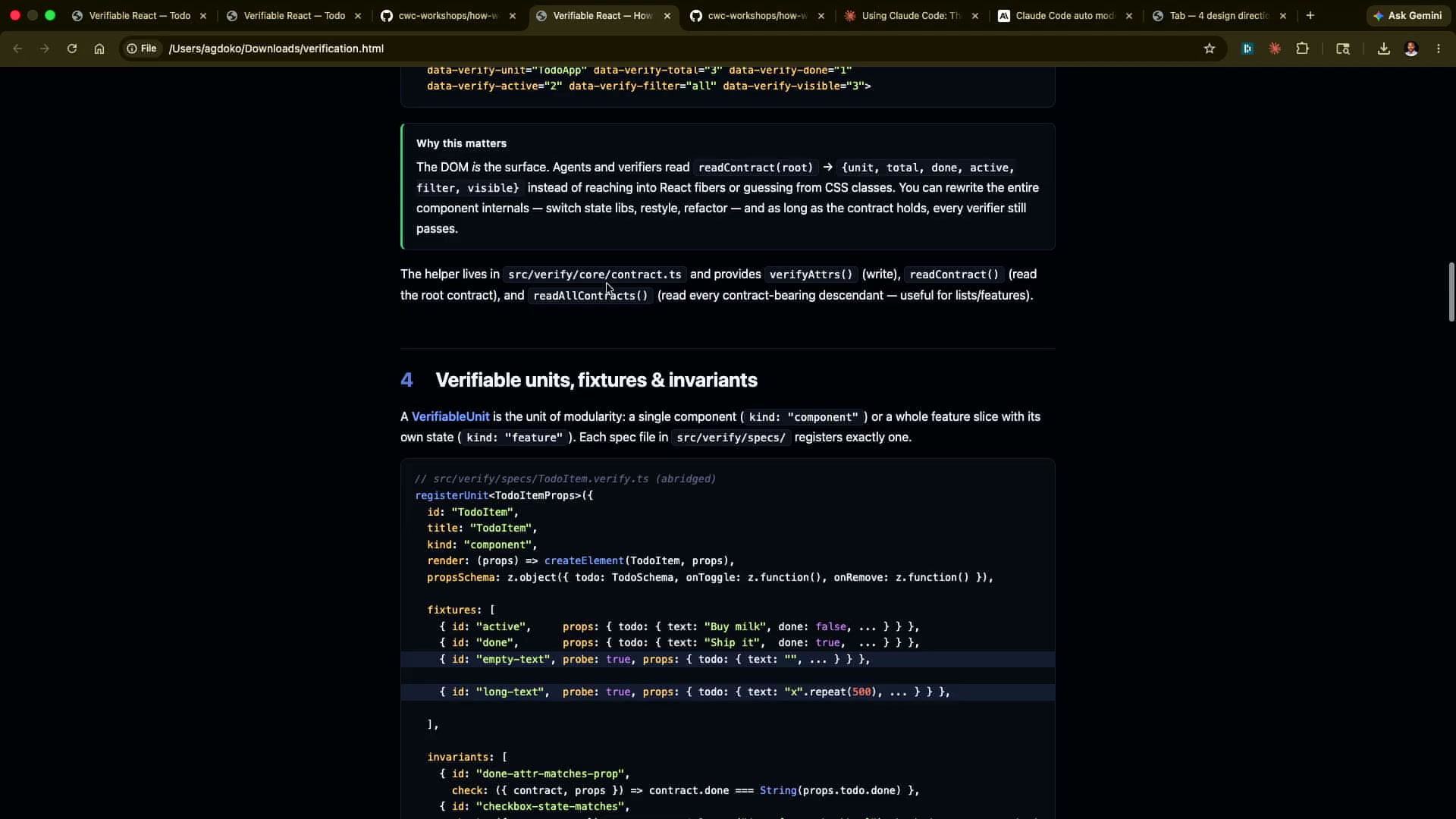
fixtures — コンポーネントをテストするための入力データセット。「完了済みTodo」と「未完了のTodo」という2つの状態を定義している。フィクスチャには data-verify-* DOM属性が含まれており、後でPlaywrightなどのブラウザ自動化ツールがDOM要素を特定する際のアンカーになる。
invariants — コンポーネントが常に満たすべき条件(不変条件)。「完了済みアイテムは取り消し線が表示されるべき」「チェックボックスの状態は completed プロパティと一致するべき」という2つのルールが定義されている。インバリアントは「このコンポーネントが正しく動作しているとはどういうことか」を機械的に検証可能な形で表現したものだ。
data-verify-* DOM属性 — これがアーキテクチャの巧妙な点だ。CSSクラスやコンポーネントの内部IDではなく、専用の data-verify-* 属性を使う。これによって「スタイル変更によってテストが壊れる」問題を回避できる。例えば class="todo-item completed" を class="task done" にリネームしてもテストは壊れない。data-verify-completed="true" という属性は検証目的専用であり、スタイリングの変更とは完全に独立している。
この設計思想は「セマンティクスとスタイルの分離」というHTML本来の思想と一致する。data-verify-* 属性はドキュメントの意味(このTodoは完了済みだ)を表現し、CSSクラスは見た目(完了済みは灰色で表示する)を表現する。两者が独立しているため、デザイン変更がテストを壊すことはない。
window.__verify API
registerUnit() で登録された検証ユニットは、グローバルの window.__verify オブジェクトから操作できる:
// ブラウザのコンソールから実行可能
window.__verify.manifest() // 登録済みコンポーネント一覧
window.__verify.runAll() // 全コンポーネントの検証実行
window.__verify.run('TodoItem') // 特定コンポーネントのみ検証
この window.__verify APIが後述の「エージェント駆動検証」を可能にする鍵だ。Playwright MCPを通じてClaudeがブラウザのコンソールにアクセスし、window.__verify.runAll() を実行してすべての検証結果を読み取れる。
3つの検証サーフェス(人間・エージェント・ヘッドレス)
Verifiable Componentアーキテクチャが特に優れているのは、1つの実装で3つの異なる検証サーフェスを提供できる点だ。
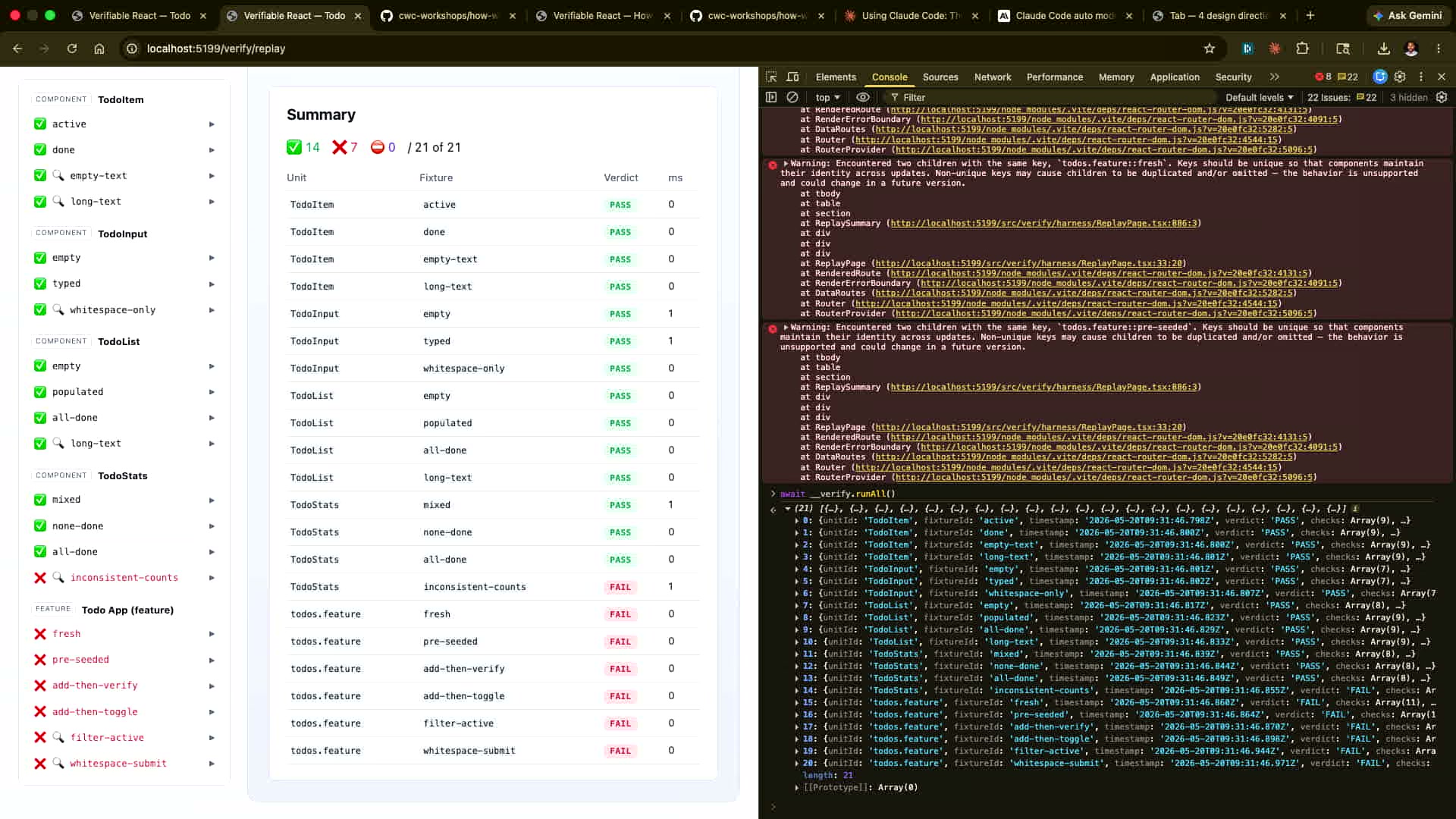
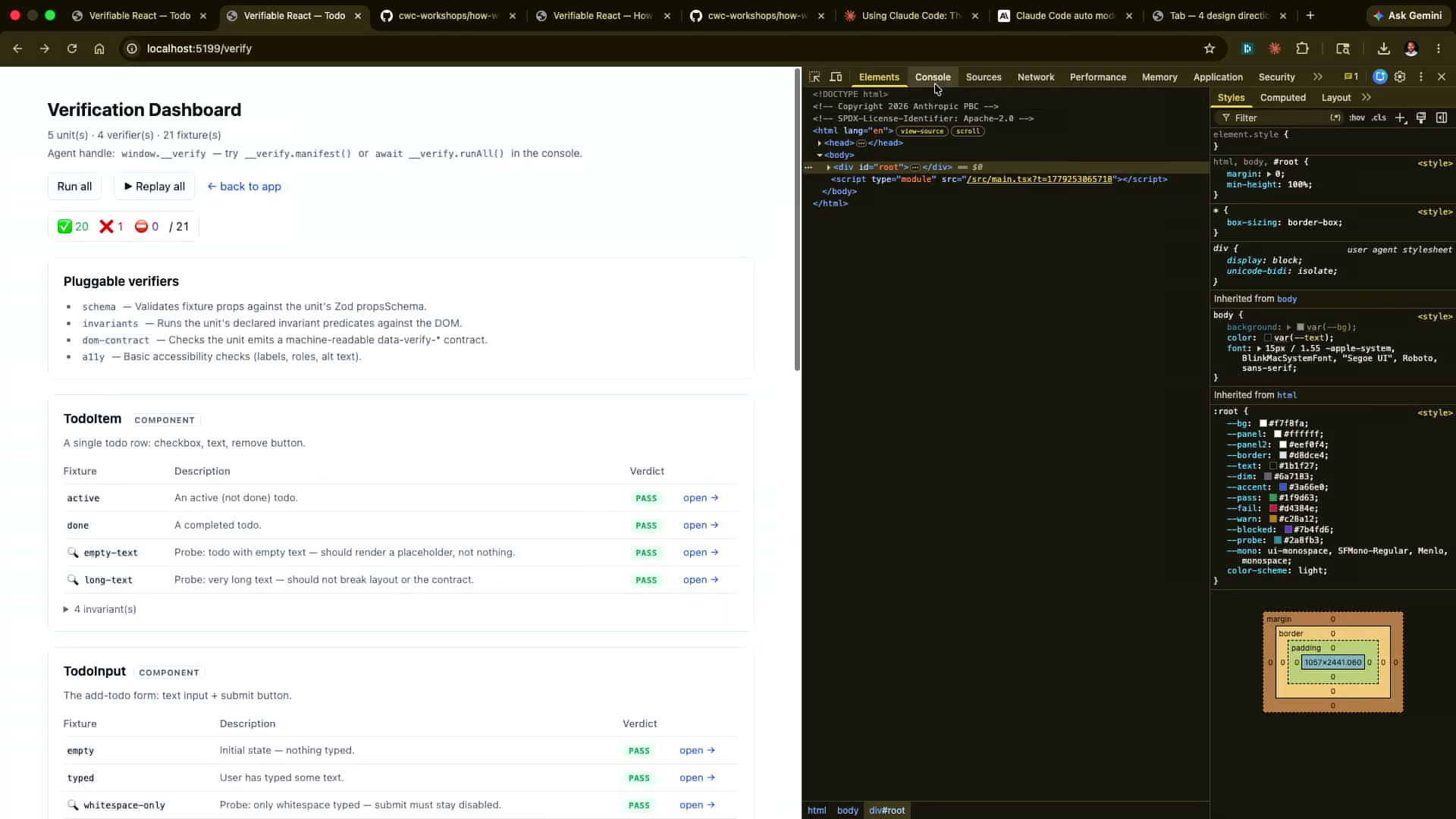
サーフェス1:人間が見るダッシュボード(/verify ルート)
localhost:5199/verify にアクセスすると、すべてのコンポーネントの検証状態をビジュアルなダッシュボードで確認できる。各コンポーネントのフィクスチャが実際にレンダリングされ、インバリアントが通過しているかどうかが一目でわかる。
これは開発者がQAを行う際の主要インターフェースだ。「TodoItemコンポーネントの完了状態表示が正しいか」を確認するために、実際のアプリを操作する必要がなく、/verify を開けば即座にわかる。
サーフェス2:エージェントが操作するブラウザ(Playwright MCP)
Dokoのデモで最も印象的だったのがこのサーフェスだ。Claude CodeにPlaywright MCPが設定されていると、エージェント自身がブラウザを操作して検証を実行できる。
エージェントのワークフローは次のようになる:
- Playwright MCPで
localhost:5199/verifyを開く window.__verify.runAll()をコンソールで実行- JSON形式の検証結果を読み取る
- FAILしたコンポーネントを特定
- 該当コードを修正して再検証
このループをエージェントが自律的に回すことができる。人間がQAを行う必要がなく、「動いているかどうか」をエージェント自身が判断できる。
Playwright MCPによるエージェント自律検証が特に力を発揮するのは「大規模リファクタリング後の回帰チェック」だ。例えばグローバルなCSS変数を変更したとき、どのコンポーネントのインバリアントが壊れたかを手動で確認するのは大変だ。しかしエージェントが /verify を一度確認するだけで、壊れたコンポーネントのリストが即座に得られる。修正→再検証→全PASS というサイクルをエージェントが自律的に完走できる。
サーフェス3:ヘッドレス実行(CI/CD)
bun run verify
このコマンドひとつで、ブラウザを起動せずにすべての検証を実行できる。Playwright headlessモードを使い、ダッシュボードと同一のインバリアント群を評価する。GitHubActionsなどのCIパイプラインに組み込むことで、PRのたびに自動検証が走る。
デモではCIパイプラインの出力が表示され、14件のPASSと7件のFAILが表示されていた。7件のFAILはDokoが意図的に「inconsistent-counts」という名前でバグを植え付けたもので、「エージェントがFAILを検出できる」というデモンストレーション目的だった。
Playwright MCPでエージェントが自律検証する
フェーズ3の最大の価値は「エージェント駆動の自律検証ループ」だ。Playwright MCPの設定からエージェントの検証ループまでのフローを図示する。
Brainstorming Skill
/brainstorm"] -->|インタビュー完了| B["Phase 2
HTMLスペック生成
4デザイン方向性"] B -->|方向性確定| C["Phase 3
実装開始
React + Vite"] C --> D["registerUnit 宣言
fixtures + invariants"] D --> E{"検証サーフェス選択"} E -->|人間QA| F["/verify ダッシュボード
localhost:5199/verify"] E -->|エージェント自律| G["Playwright MCP
ブラウザ自動操作"] E -->|CI/CD| H["bun run verify
ヘッドレス実行"] G --> I["window.__verify.runAll
コンソール実行"] I --> J{"PASS/FAIL?"} J -->|FAIL検出| K["コード修正
Claude Code自律対応"] K --> I J -->|全PASS| L["実装完了"] H --> M["GitHub Actions
PR自動チェック"]
このフローの核心は「エージェントが自分の出力を自分で検証できる」という点だ。従来の開発では「実装→人間がテスト→バグ報告→修正」というループに人間が介在していた。Verifiable Componentアーキテクチャでは「実装→エージェントが自律検証→バグ検出→自律修正」というループが成立し、人間はフェーズ1の要件確認とフェーズ2のデザイン確定にだけ関与すればよくなる。
Dokoはセッションの中で「エージェントがコードを書いた後すぐに /verify を確認する」デモを見せた。エージェントがTodoListコンポーネントを実装し、Playwright MCPを使って /verify を開き、window.__verify.runAll() を実行し、1件のFAILを発見し、自律的にコードを修正して再検証まで行うサイクルを、ユーザーの介入なしに完了させた。これは単なるデモではなく、DokoがAnthropic社内で実際に使っているワークフローだと強調した。
Playwright MCPの設定方法
Dokoのデモ環境を再現するためのPlaywright MCP設定を紹介する。Claude Desktopの設定ファイル(claude_desktop_config.json)に以下を追加する:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["-y", "@playwright/mcp@latest"],
"env": {
"PLAYWRIGHT_HEADLESS": "false"
}
}
}
}
Claude CodeではMCP設定を .claude/mcp.json に記述する方法も使える。どちらでもPlaywright MCPが有効になり、エージェントが mcp__playwright__browser_navigate、mcp__playwright__browser_console_evaluate などのツールを使ってブラウザを制御できるようになる。
AIエージェントを使った自律的な検証ループに興味があれば、AIエージェントフレームワーク比較2026:LangGraph・CrewAI・AutoGen完全解説も参照してほしい。
このフローが解決する「長時間エージェント問題」
Dokoの3フェーズフローを深く理解するために、このフローが解決しようとしている根本的な課題を整理しておきたい。
現在のLLMエージェントには、コンテキストウィンドウという根本的な制約がある。どれだけ賢いモデルであっても、一度に処理できる情報量には限界がある。長時間・大規模なタスクでは、エージェントは途中でコンテキストを切り捨てたり、以前の指示を「忘れた」ような挙動を示す。
この制約を前提にしたとき、3フェーズフローはコンテキスト管理の戦略として機能する:
フェーズ1の役割(コンテキスト前処理): 仕様を「Claudeが最も効率よく処理できる形式(HTMLドキュメント)」にまとめる。あいまいさを事前に排除することで、エージェントが実行中に「どうするべきか」で迷うコンテキスト消費を最小化する。
フェーズ2の役割(計画の可視化): 実装計画をコードではなくHTMLという中間表現で固める。HTMLは軽量で、コンテキストウィンドウに収まりやすく、かつ視覚的に豊富な情報を含む。
フェーズ3の役割(検証のコンテキスト非依存化): 検証をコンポーネントに内蔵することで、検証はコンテキストに依存しなくなる。window.__verify.runAll() の実行だけで「今の実装が正しいか」を判断できるため、エージェントが以前の仕様を記憶していなくても検証が成立する。
フェーズ3(検証)を先に設計しようとすると失敗する。何を作るかが未確定な状態でインバリアントを書けないからだ。フェーズ1→2→3の順序は、「曖昧さの排除」→「合意の形成」→「合意の機械的確認」という認識論的な順序に対応している。これは単なる作業の順序ではなく、正しい意思決定の順序だ。
ワークショップで学んだ実践知
Dokoのセッションを通じて得られた実践的な知見を整理する。まず、MarkdownスペックとHTMLスペックの使い分け基準を比較表で示す。
| 比較項目 | Markdownスペック | HTMLスペック |
|---|---|---|
| 適切なスケール | 〜200行、小規模機能 | 200行超、プロダクト全体 |
| 視覚表現 | テキストのみ | CSS/画像/スクリーンショット埋め込み |
| Claudeのビジョン活用 | 不可 | Opus 4.7のビジョン能力をフル活用 |
| デザイン方向性の伝達 | 文章による説明(低精度) | 実際のHTMLレンダリング(高精度) |
| 複数案の比較 | 難しい | 4方向を並列生成して見比べ可能 |
| エージェントへのフィードバック | テキスト編集 | HTMLコメント + CSS変数変更 |
| バージョン管理 | Git friendly | Git friendly(バイナリなし) |
| 長期的なメンテナンス | 平文テキストで容易 | マークアップが複雑になりうる |
この表が示すのは「HTMLはMarkdownの上位互換ではない」という点だ。小規模な機能スペックやクイックな指示はMarkdownで十分だ。しかし複雑なUIを持つプロダクトを長時間エージェントで構築するなら、フェーズ2のタイミングでHTMLに移行することがDokoの強い推奨だ。
長時間エージェントのための3フェーズ全体像
Dokoが一貫して強調したのは「フェーズをスキップするな」というメッセージだ。
フェーズ1をスキップすると → あいまいな仕様でエージェントが走り出し、後半で大規模リライトが発生する
フェーズ2をスキップすると → 方向性が確定しないまま実装が進み、デザインの大幅変更コストが跳ね上がる
フェーズ3をスキップすると → エージェントが「見た目は正しい」と誤認し、ロジックの不整合が潜伏し続ける
3フェーズは独立した手法ではなく、互いを支え合う統合的なシステムだ。
Beyond the basics with Claude Codeで紹介された Context Engineering や Hooks など、Claude Codeの高度な使い方についてはBeyond the basics with Claude Code — Londonセッション完全解説も参照してほしい。
実践的なチェックリスト
Dokoのフレームワークを自分のプロジェクトに適用するためのチェックリストを以下に示す。
- フェーズ1の準備
cwc-workshopsリポジトリのブレインストーミングスキルをコピー.claude/skills/brainstorm.mdとして配置/brainstormでインタビューを開始(/effort xhigh推奨)
- フェーズ2の準備
- モデルを
claude-opus-4-7に切り替え /fastをONにする(thinking出力不要)- 4方向のHTMLデザイン案を生成してもらう
- フィードバックはHTMLコメントかCSSの直接編集で行う
- モデルを
- フェーズ3の準備
- React + Vite プロジェクトを初期化
registerUnit()をコンポーネントに実装data-verify-*DOM属性を設計/verifyルートを追加- Playwright MCPを設定
bun run verifyをCIに組み込む
このアーキテクチャの限界と注意点
Verifiable Componentアーキテクチャには明確な利点がある一方で、注意すべき点もある。
適用範囲の限定: このアーキテクチャはUI/UXコンポーネントを持つフロントエンドアプリに最適化されている。バックエンドのビジネスロジック、データパイプライン、インフラ自動化などには直接適用できない。これらのユースケースには別のアプローチが必要だ。
インバリアントの品質: registerUnit() が強力なのは、インバリアントが適切に定義されている場合に限る。「コンポーネントがレンダリングされる」というトリビアルなインバリアントだけ書いても意味がない。意味のあるインバリアントを書くには、コンポーネントの「正しさ」についての深い理解が必要だ。
メンテナンスコスト: コンポーネントの仕様が変わるたびに registerUnit() の定義も更新が必要だ。仕様変更と検証定義の同期を保つためのプロセスが必要になる。
Dokoはこれらのトレードオフについてオープンに話した:「このアーキテクチャはReact+Viteのフロントエンドに最適化されています。あなたのユースケースに合わない場合は、原則だけを取り出してください——検証をアーティファクトに内蔵する、3つのサーフェスで確認できるようにする、エージェントが自律検証できるAPIを提供する、という3つの原則は、別の技術スタックでも応用できます」。
まとめ
Arnaud DokoのセッションはAnthropic社内での実践的な開発フローを余すことなく公開した、非常に密度の高いセッションだった。
3フェーズのフレームワーク(あいまいさの排除→HTMLスペック→検証内蔵)は、それぞれが独立したベストプラクティスとして有用だが、3つが組み合わさることで初めてフル効果を発揮する。
特に重要なのは思想的な転換点だ:「モデルが賢くなるほど、制約せずに任せるべき」「人間はドメインを提供し、Claudeが要件を引き出す」「検証は後付けでなく設計の一部」——これらの洞察はClaude Code 1.0時代の常識を根底から覆す。
セッション全体を通じて印象的だったのは、DokoがAnthropic社内での実際の失敗談もオープンにシェアしたことだ。「かつては直接実装させていた。仕様書を渡してコードを書かせて、最後にテストを追加した。それで何度も大規模リライトが発生した。このフレームワークは、その失敗から生まれた」と述べた。
最先端のAIモデルを開発している組織でさえ、エージェント活用に試行錯誤があることが明らかになった。Dokoのセッションが持つ最大の価値は「Anthropicでさえこう使っている」という実践的な信頼性だ。このフレームワークは理論ではなく、現場の失敗から蒸留された知恵だ。
Code with Claude London 2026の他セッションで紹介された「Beyond the basics with Claude Code」のContext EngineeringやHooks機能と組み合わせることで、さらに強力なエージェント開発環境が構築できる。Beyond the basics with Claude Code — Londonセッション完全解説では、CLAUDE.mdの効果的な書き方、セッション管理、カスタムスラッシュコマンドについて詳しく解説している。
1. github.com/anthropics/cwc-workshops をクローン
2.
how-we-claude-code/ ディレクトリのREADMEを読む3. Phase 1のブレインストーミングスキルを自分のプロジェクトに追加
4. 次の機能実装で
/brainstorm から始めてみる小さな一歩から始めれば、3フェーズフローの効果を体感できる。
参照ソース
- Arnaud Doko, “How we Claude Code” — Code with Claude London 2026, YouTube: https://www.youtube.com/watch?v=IlqJqcl8ONE
- cwc-workshops/how-we-claude-code — GitHub公開リポジトリ: https://github.com/anthropics/cwc-workshops
- Playwright MCP — Microsoft公式: https://github.com/microsoft/playwright-mcp





